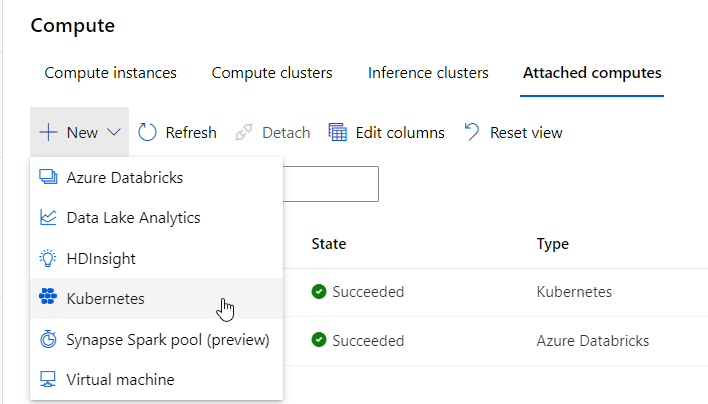
Azure Machine Learning donne la possibilité de supporter les calculs de Machine Learning par des ressources extérieures et différentes des machines virtuelles classiques de l’on retrouve dans les compute instances ou compute clusters.
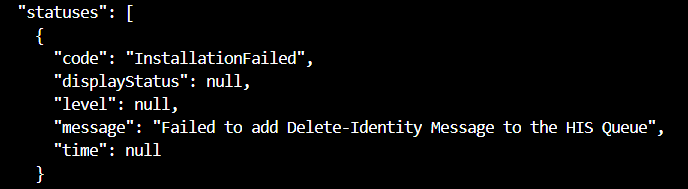
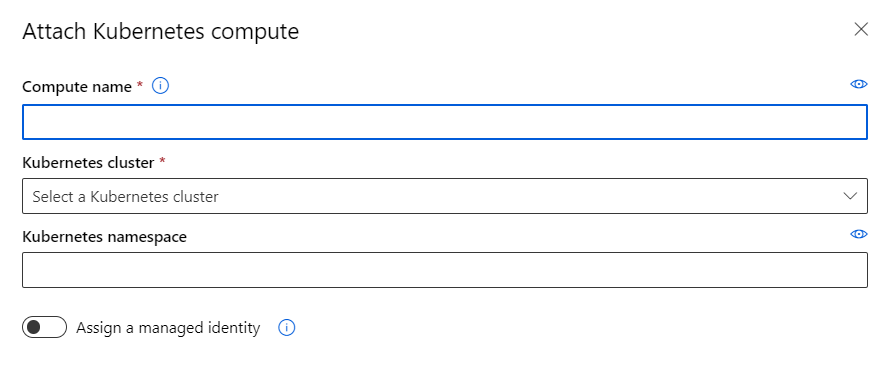
Nous allons voir dans cet article comment mettre à disposition un attached compute de type Kubernetes. Pour une ressource Azure Kubernetes Service déjà existante dans la souscription Azure, nous allons avoir besoin d’ajouter une extension Azure Machine Learning sur le cluster k8s. Cette installation ne se fait que par l’intermédiaire des commandes en ligne (az cli).
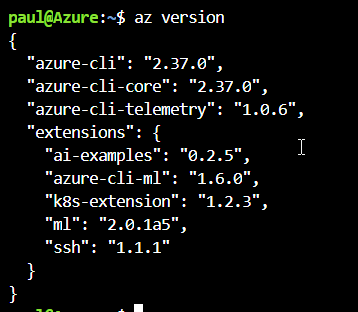
Depuis le portail Azure, il est possible de lancer une fenêtre Cloud Shell déjà connectée, sous le login de l’utilisateur. Vérifions les versions installées.
Si k8s-extension n’est pas présent ou n’est pas à jour (version minimale : 1.2.3, il faut l’installer par la commande ci-dessous.
az extension update --name k8s-extension
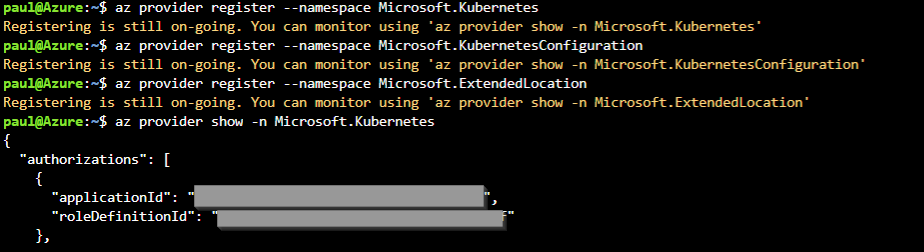
Nous allons avoir besoin d’ajouter une identité managée sur la ressource Azure Kubernetes Service, ce qui se fait par la commande suivante.
az aks update --enable-managed-identity --name <aks-name> --resource-group <rg-name>
Comme indiqué dans la documentation, il faut tout d’abord inscrire les différents fournisseurs.
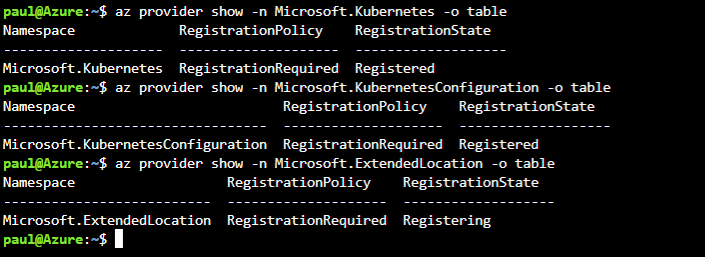
Nous pouvons surveiller le bon déroulement des inscriptions, tous les statuts doivent passer sur “Registered”.
Nous pouvons maintenant passer à l’ajout de l’extension.
Nous choisissons dans la documentation disponible sur ce lien la syntaxe adaptée à AKS (manageClusters) pour un test rapide (à ne pas utiliser pour un environnement de production).
Nous avons présenté dans un précédent article la plateforme de Data Science de Dataïku et son installation sur une VM dans Azure. Nous avons également déjà abordé la connexion à un compte de stockage Azure, afin de lire des fichiers de données ou d’écrire les différents résultats obtenus.
Dans un Système d’Information non centré autour du Data Lake, certaines données particulièrement intéressantes pour le Machine Learning peuvent être stockées dans les tables d’une base de données, souvent orientée “analytique”. Le Data Warehouse d’Azure, Synapse Analytics, est disponible dans les connexions prévues par Dataïku DSS. Nous allons détailler ici les actions à réaliser pour définir la connexion à la base de données. Un grand merci à mon collègue Benjamin BENITO qui a réalisé les opérations techniques décrites ci-dessous.
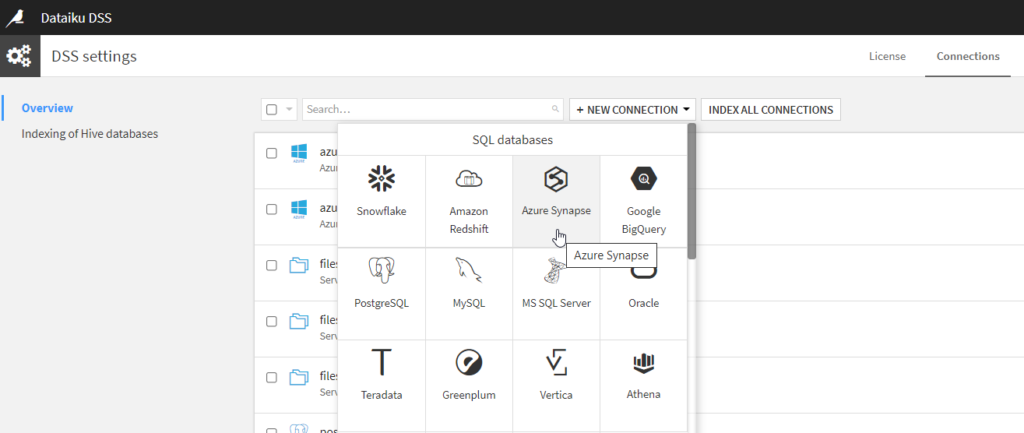
Dans les paramètres de Dataïku DSS, nous pouvons trouver la liste des différentes bases de données SQL compatibles avec le Studio de Data Science.
Nous choisissons Azure Synapse. Il faut noter, que dans une exploitation plus large des capacités de Synapse Analytics, il sera aussi possible d’utiliser cette ressource comme moteur de calcul Spark. Nous verrons ceci dans un prochain article.
Dedicated SQL Pool
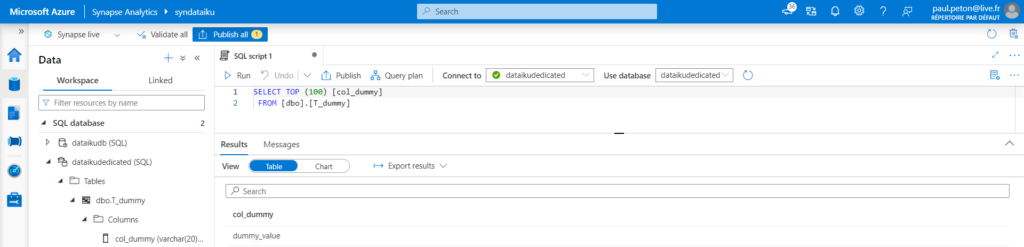
Une base de données de type “dedicated SQL pool” aura été préalablement créée du côté de Synapse Analytics.
Pour la démonstration, nous disposons d’une table à une colonne, contenant une valeur.
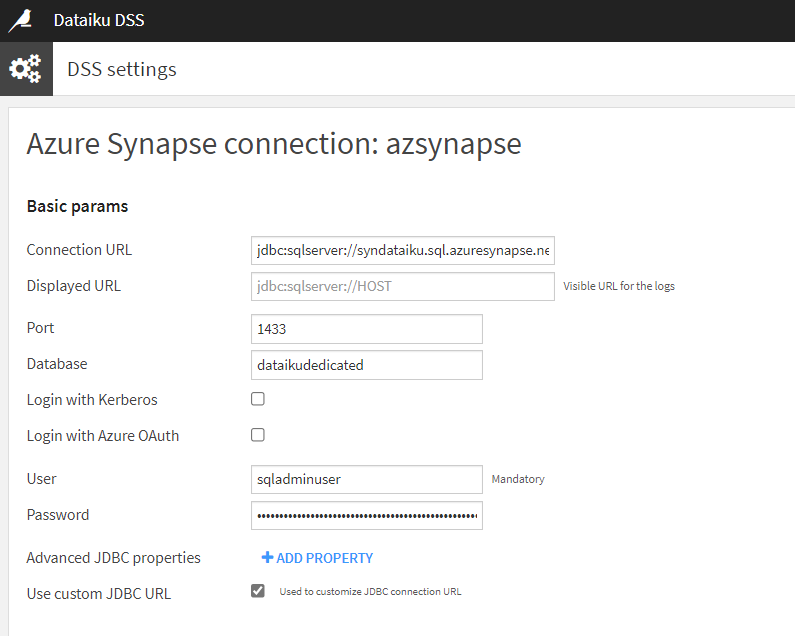
Nous pouvons maintenant renseigner les différents éléments attendus pour la définition de la connexion. Commençons par cocher la case “Use custom JDBC URL”.
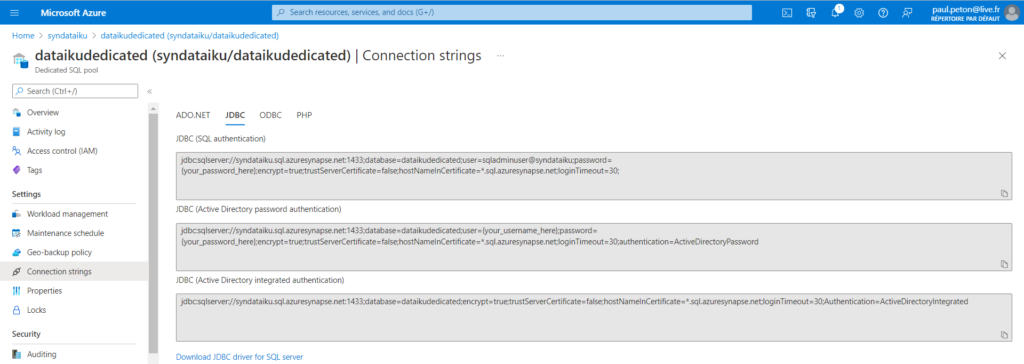
L’URL JDBC se trouve sur le portail Azure, à la page de la ressource Dedicated SQL Pool, onglet “connection strings“. Nous utiliserons ici la première version, utilisant la connexion SQL.
Il faudra remplacer ici le texte {your_password_here} par le mot de passe du compte administrateur.
Ces informations, ainsi que le port ouvert (1433) pourront également être précisées dans les cases disponibles. Il ne reste plus alors qu’à tester la connexion à l’aide du bouton situé en bas à gauche de l’écran. Je vous recommande de créer la connexion (bouton “create”) au préalable afin de sauvegarder les informations saisies.
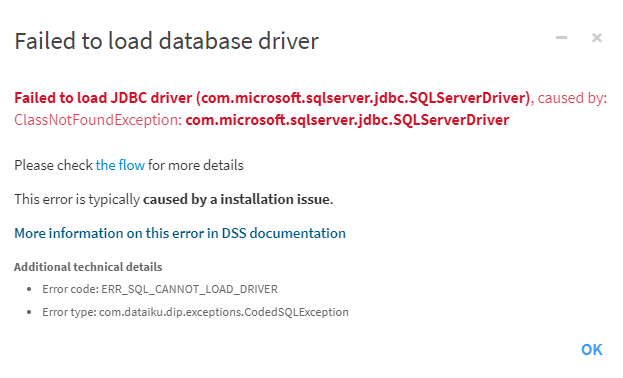
Il est alors fort probable que vous soyez confronté.e.s à l’erreur ci-dessous.
Cette erreur est due à l’absence de driver SQL Server sur la VM où est installé Dataïku DSS. L’URL suivante détaille cette erreur.
Nous allons donc nous connecter à cette machine virtuelle Linux pour effectuer manuellement l’installation du driver attendu. Nous devons disposer pour cela d’un login / password ou d’une clé SSH.
Voici les différentes commandes à jouer successivement.
Les premières commandes réalisent le téléchargement du binaire nécessaire, le dézippe puis le copie à l’endroit attendu. Un restart de DSS est ensuite nécessaire.
La connexion est maintenant établie !
Nous pouvons utiliser le lien “Import tables to datasets” pour obtenir des données stockées dans le Data Warehouse.
Serverless SQL Pool
Pour utiliser le mode serverless de Synapse Analytics, nous devrions nous orienter vers un autre type d’authentification. En effet, ce mode correspond à la création de méta-données sur des fichiers présents dans un Data Lake mais sans matérialisation dans le Data Warehouse. Des droits sous-jacents (sur les fichiers du Data Lake) sont donc nécessaires et il n’est pas possible d’attribuer de tels droits au user connu uniquement de la base de données.
Le message d’erreur rencontré sera alors :
Failed to read data from table, caused by: SQLServerException: External table 'dbo.<external_table>' is not accessible because location does not exist or it is used by another process.
La documentation officielle de Dataïku donne toutes les étapes permettant d’utiliser l’authentification au travers d’Azure Active Directory.
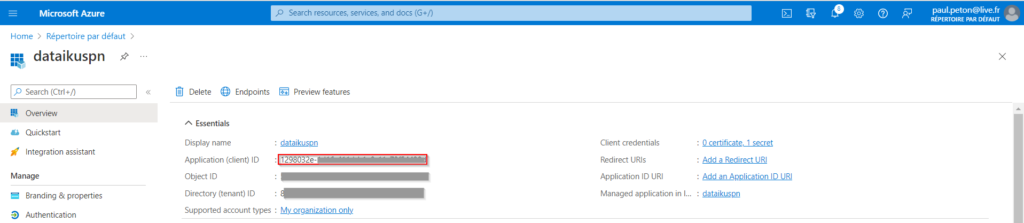
Nous avons besoin d’un Principal de Service, c’est-à-dire d’une identité dans Azure. Nous relevons tout d’abord l’application ID (ou client ID) qu’il sera nécessaire de renseigner dans Dataïku DSS.
Dans le menu “Endpoints”, nous notons l’information de l’OAuth 2.0 token endpoint (v1).
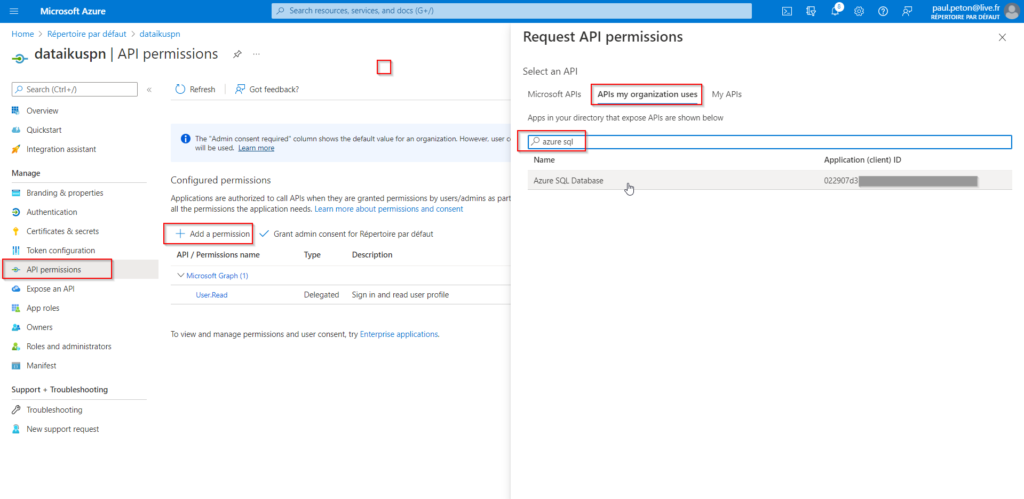
Dans le menu “API permisssions”, nous devons ajouter la permission Azure SQL Database.
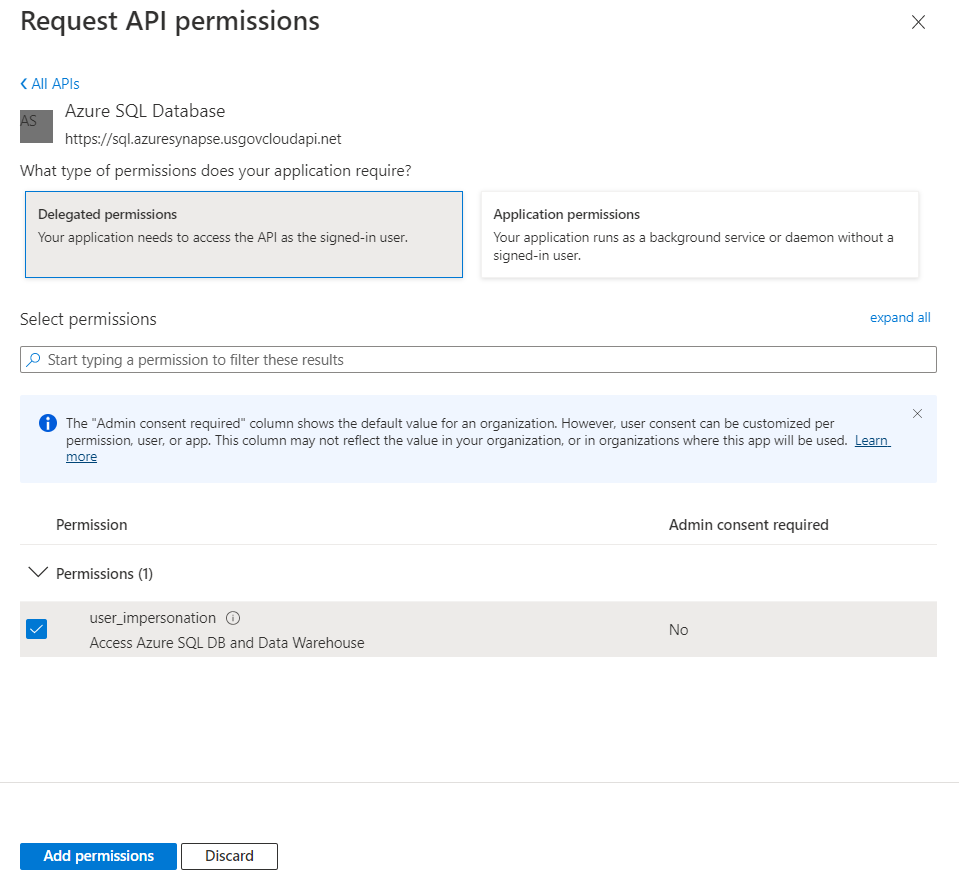
Choisir ensuite “Delegated permissions” puis cocher la case user_impersonation.
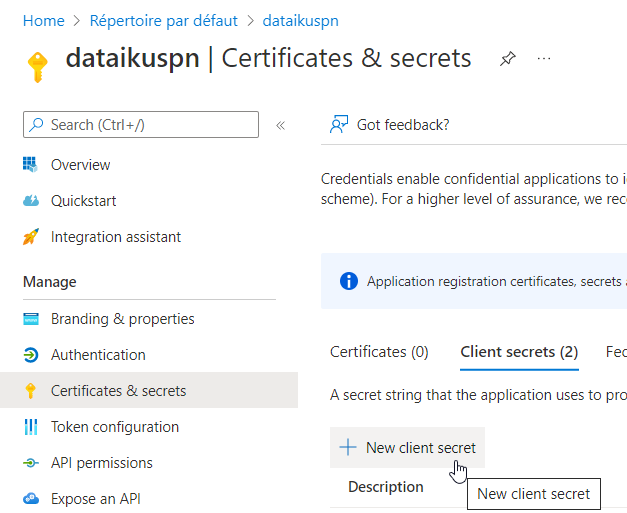
Nous terminons le paramétrage de cette identité en lui associant un secret. Notez ici bien la valeur du secret, que vous ne pourrez plus retrouver par la suite.
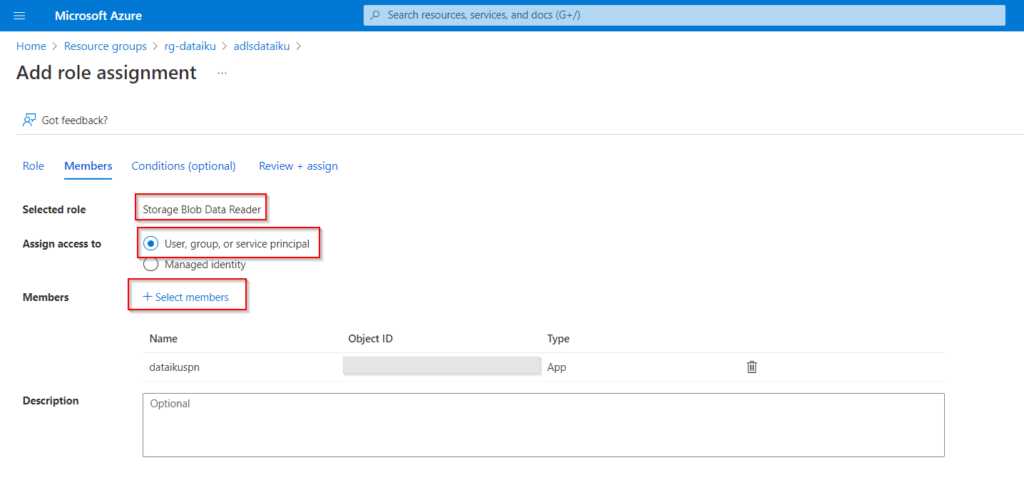
Toujours dans le portail Azure, il faut donner les droits de lecture sur le Data Lake au principal de service. Cela se fait au moyen de l’ajout d’un RBAC de type “Blob storage data reader”.
Sinon, une erreur comme ci-dessous se produira lors de l’aperçu de la table ou de la vue :
Failed to read data from table, caused by: SQLServerException: File 'https://adlsdataiku.dfs.core.windows.net/dataiku/input/diamonds.csv' cannot be opened because it does not exist or it is used by another process.
Nous reprenons maintenant la définition d’une nouvelle connexion Synapse Analytics depuis le Data Science Studio.
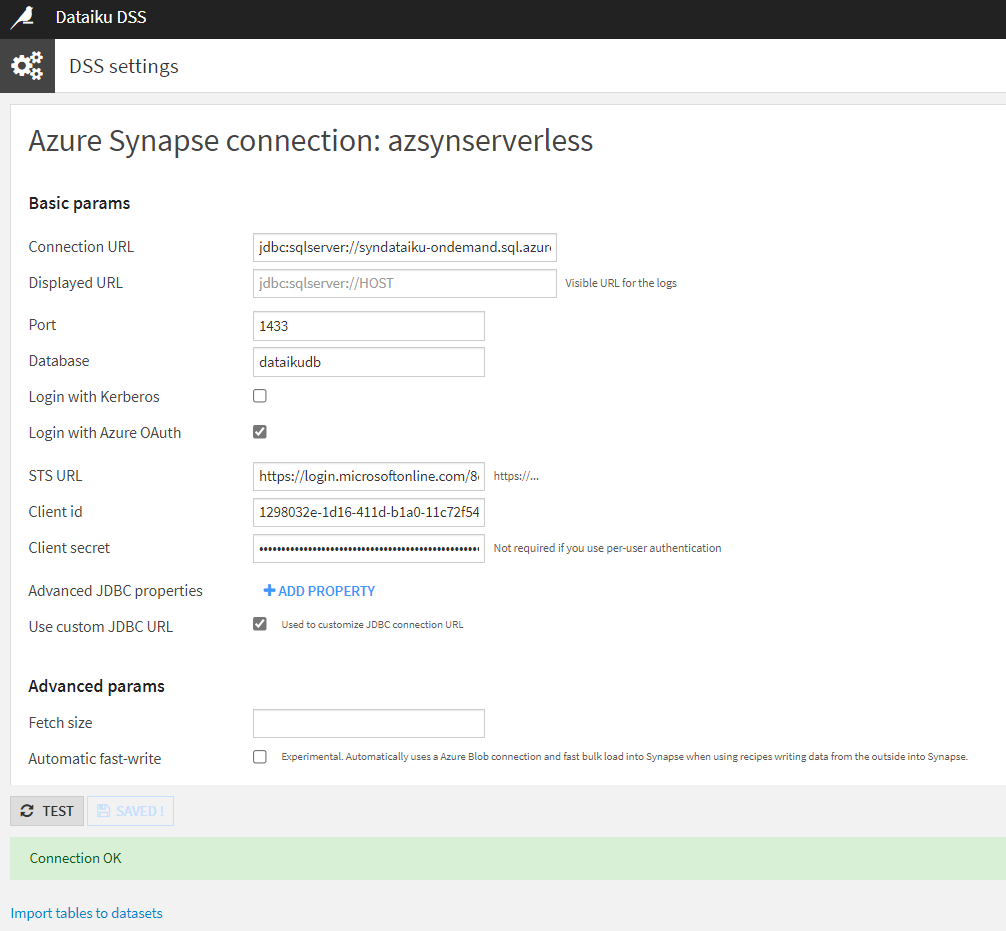
En cochant la case “Use custom JDBC URL”, il faut donner une Connection URL de la forme suivante :
Nous précisons le port (1433 par défaut) et le nom de la Database.
Pour la partie liée à l’Azure AD, il faut cocher la case “Login with Azure OAuth” puis coller les informations préalablement collectées :
STS URL (OAuth 2.0 token endpoint (v1))
Client id (application id)
Client secret (la valeur du secret et non le secret id)
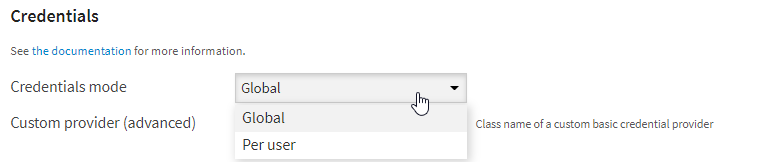
Deux modes de “credentials” sont possibles : Global ou Per user. Ce second mode signifie que c’est le login utilisé dans DSS qui est repris pour s’authentifier auprès de la base Synapse. Il ne sera alors pas nécessaire de renseigner le client secret.
Depuis Synapse Analytics, dans une nouvelle requête SQL, nous allons déclarer le principal de service (SPN) comme un utilisateur de la base de données. Veillez à bien être connecté à “Built-in”, c’est-à-dire la base serverless.
Voici le code à exécuter, où le nom du SPN doit être mis à jour. Il est nécessaire d’attribuer des droits de type “BULK” puis “SELECT” sur les objets qui seront autorisés à Dataïku DSS.
CREATE USER [dataikuspn] FROM EXTERNAL PROVIDER WITH DEFAULT_SCHEMA=[dbo];
GO
GRANT ADMINISTER DATABASE BULK OPERATIONS TO dataikuspn;
GO
GRANT SELECT ON OBJECT::dbo.V_diamonds TO [dataikuspn];
GO
Il est maintenant possible d’ouvrir la liste des tables à importer depuis l’interface de DSS.
Ce second scénario s’avère intéressant pour limiter les coûts d’utilisation de Synapse Analytics (coût à la quantité de données lues) et facilite l’exploitation des données du Data Lake qui auront pu être réorganisées sous forme de vues SQL plus lisibles des utilisateurs de Dataïku.
La stratégie “Lakehouse” de Databricks vise à fusionner les usages du Data Lake (stockage de fichiers) et du Data Warehouse (modélisation de données dans un but analytique). Il semble donc évident de trouver des connecteurs vers les principaux outils de Business Intelligence Self Service dans la partie “SQL” de l’espace de travail Databricks.
Nous allons détailler ici le processus de création de dataset et de mise à jour pour Power BI. Mais avant tout, résumons en quoi consiste la fonctionnalité “SQL” de Databricks.
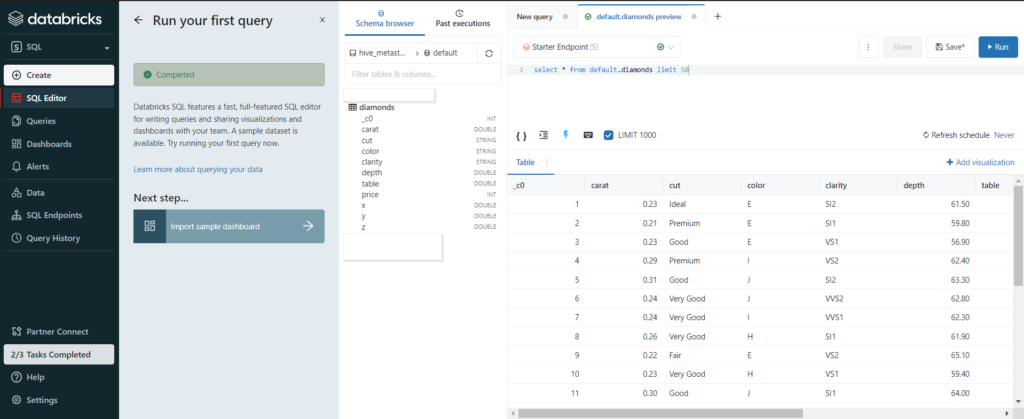
Le constat est fait qu’aujourd’hui (comme depuis plus de 30 ans…), le langage SQL reste majoritairement utilisé pour travailler les données, en particulier pour effectuer des opérations de transformations, d’agrégats ou encore de fusions. Nous pouvions d’ores et déjà utiliser des notebooks Databricks s’appuyant sur l’API Spark SQL et définir des tables ou des vues dans le metastore Hive associé à un cluster (tables visibles uniquement lorsque le cluster est démarré).
Nous pouvons créer une table à partir de la syntaxe suivante, en s’appuyant sur des fichiers de type CSV, parquet ou encore Delta :
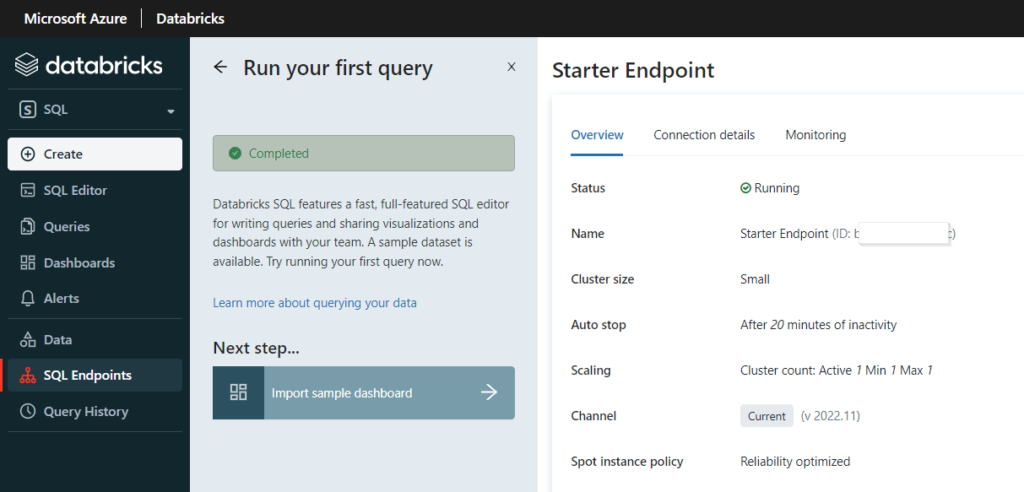
La requête est exécutée par un “SQL endpoint” qui n’est autre qu’un cluster de machines virtuelles du fournisseur Cloud (ici le cloud Azure de Microsoft).
Différentes tailles prédéfinies de clusters sont disponibles et correspondent à des niveaux de facturation exprimés en Databricks Units (DBU).
A termes, nous espérons profiter d’une capacité “serverless” qui serait mise à disposition par l’éditeur, conjointement au fournisseur de cloud public.
La table précédemment créée est ensuite “requêtable” au moyen des syntaxes SQL traditionnelles.
Il serait alors possible de créer un dashboard dans l’interface Databricks mais nous allons profiter de la puissance d’un outil comme Power BI pour exploiter visuellement les données.
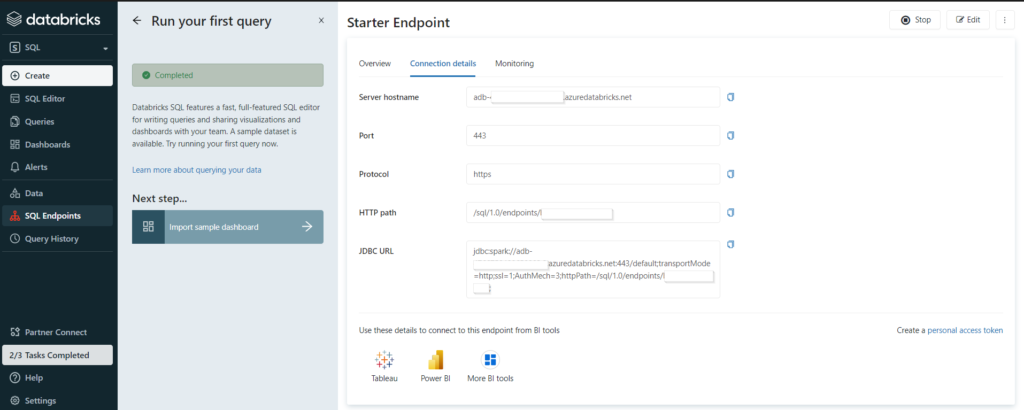
Nous récupérons donc les informations de connexion au SQL endpoint avant de lancer le client Power BI Desktop.
Databricks SQL endpoint comme source de données
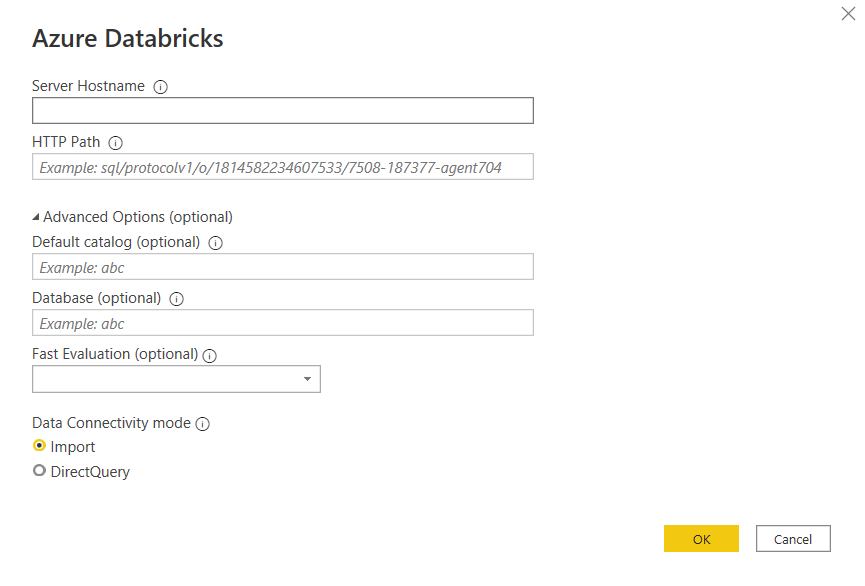
Nous recherchons Azure Databricks dans les sources de données de Power BI Desktop.
Nous retrouvons ici les informations décrivant le SQL endpoint :
server hostname : l’URL (sans htpps) de l’espace de travail Databricks
HTTP path
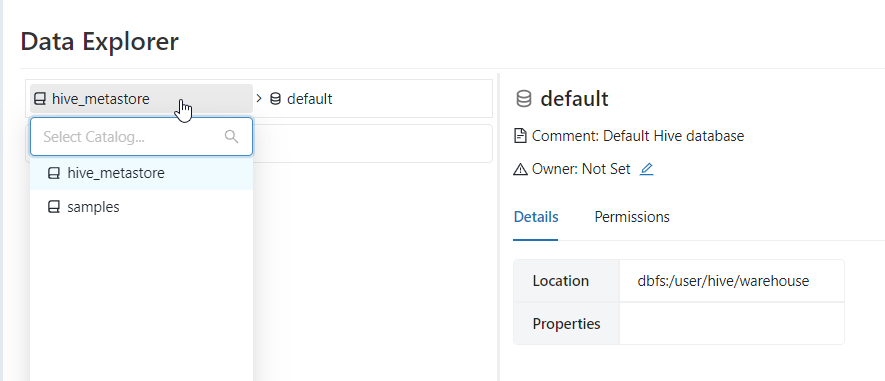
le catalogue (par défaut hive_metastore)
le database (ou schéma)
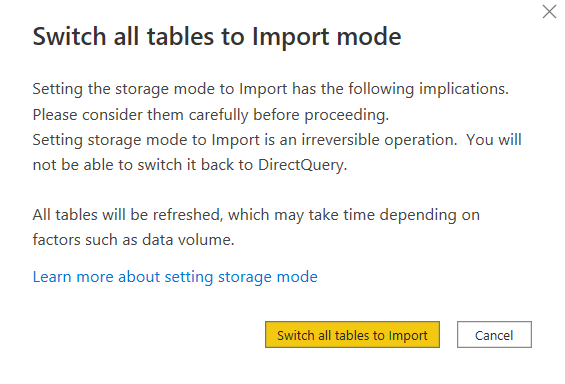
A noter que les deux modes de connexion de Power BI sont disponibles : import et DirectQuery. Pour ce dernier, il faudra prendre en compte le nécessaire “réveil” du SQL endpoint lors de la première requête. Quelques minutes peuvent être nécessaires.
Précisions qu’il est possible de créer un catalogue autre que celui par défaut (hive_metastore) et il serait alors pertinent de rédiriger le stockage des métadonnées vers une partie du Data Lake ou vers un compte de stockage dédié, comme expliqué dans cet article.
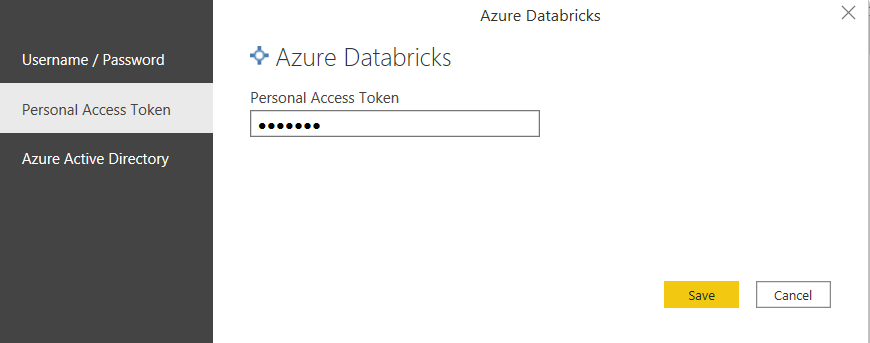
Pour voir les données du metastore, il faudra choisir une méthode d’authentification parmi les trois disponibles.
Le jeton d’accès personnel (Personal Access Token) semble simplifier les choses mais attention, sa validité est lié au compte qui l’a généré. Un utilisateur retiré de l’espace Databricks disparaît avec ses jetons ! Le périmètre associé à un PAT est très large : utilisation du CLI et de l’API Databricks, accès aux secret scopes, etc.
Nous allons donc préférer la connexion au travers de l’annuaire Azure Active Directory.
Pour gagner du temps, nous pouvons télécharger un fichier au format .pbids qui est un fichier contenant déjà les informations de connexion renseignées.
La vue des tables disponibles s’ouvre alors directement si nous disposons déjà d’une authentification définie dans notre client Power BI Desktop.
C’est alors une connexion de type DirectQuery qui est réalisée. Il sera possible de basculer en mode import en cliquant sur le message en bas à droite du client desktop.
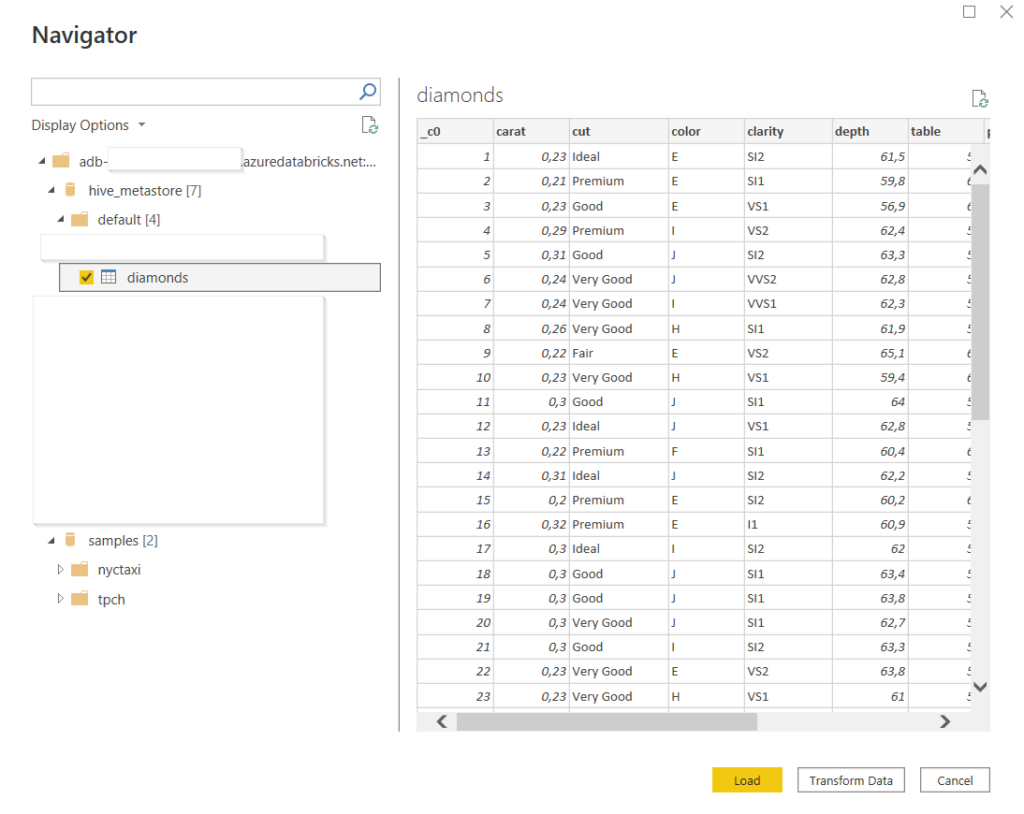
En ouvrant l’éditeur de requêtes Power Query, nous pouvons voir la syntaxe utilisée pour définir la connexion.
let
Source = Databricks.Catalogs("adb-xxx.x.azuredatabricks.net", "/sql/1.0/endpoints/xxx", []),
hive_metastore_Database = Source{[Name="hive_metastore",Kind="Database"]}[Data],
default_Schema = hive_metastore_Database{[Name="default",Kind="Schema"]}[Data],
diamonds_Table = default_Schema{[Name="diamonds",Kind="Table"]}[Data]
in
diamonds_Table
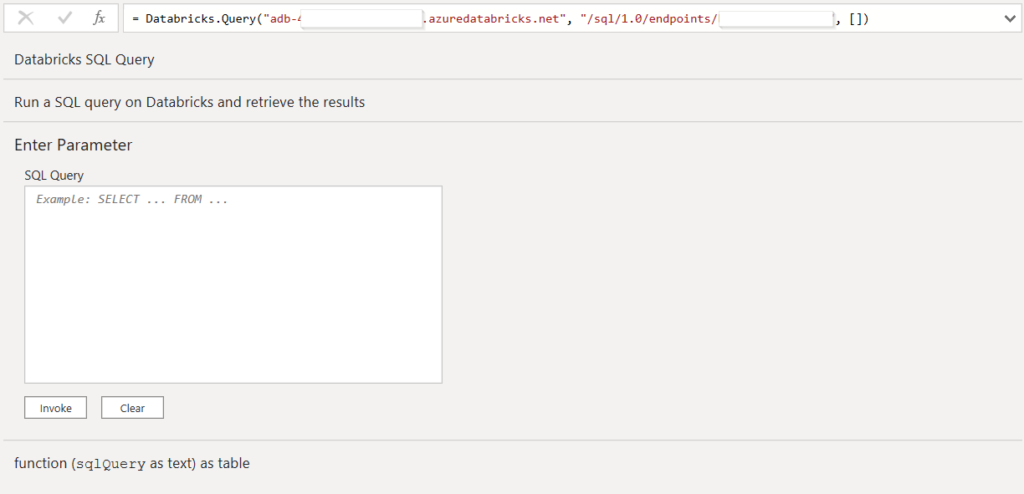
La fonction Databricks.Catalogs peut être remplacée par la fonction Databricks.Query qui permet alors de saisir directement une requête SQL dans l’éditeur.
Planifier une actualisation du dataset
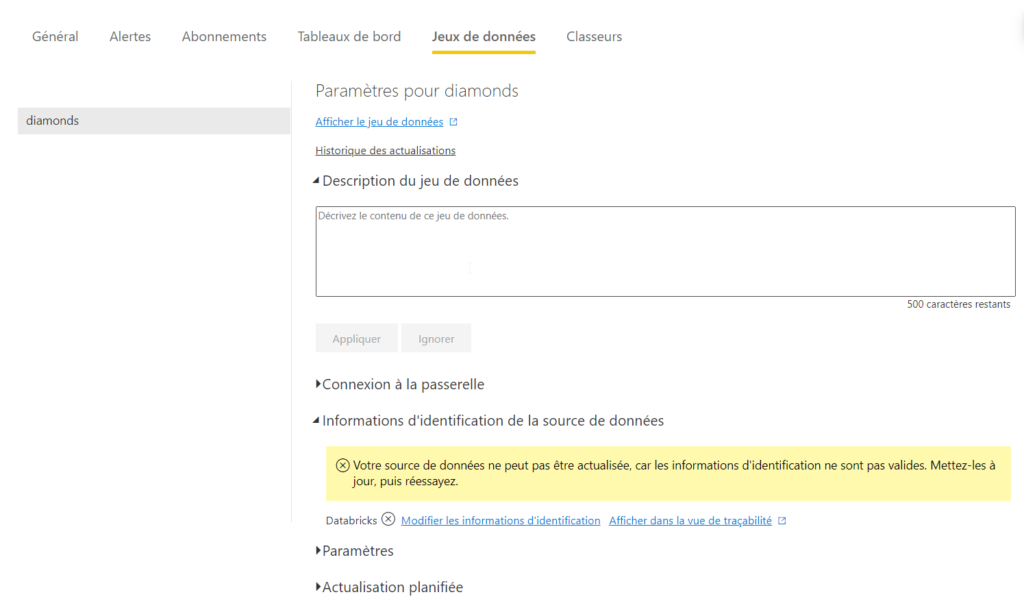
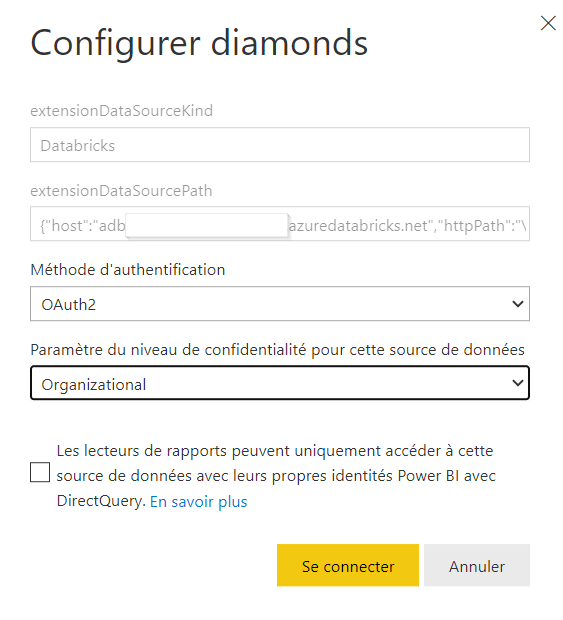
Une fois le rapport publié sur l’espace de travail Databricks, nous allons pouvoir actualiser directement les données, sans passer par le client desktop. Nous nous rendons pour cela dans les paramètres du dataset, au niveau des informations d’identification.
Nous devons ici redonner les informations de connexion. Nous en profitons pour préciser le niveau de confidentialité des données.
Dans le cas d’une connexion de type DirectQuery, nous pouvons demander à ce que l’identité de l’AAD des personnes en consultation soit utilisée. Cela permet de sécuriser l’accès aux données mais à l’inverse, il sera nécessaire que ces personnes soient déclarées dans l’espace de travail Databricks.
En conclusion, le endpoint SQL de Databricks est une approche intéressante pour éviter le coût d’un serveur de base de données dans une architecture décisionnelle. Il sera pertinent de préparer au maximum les données dans le metastore Hive pour profiter pleinement de la puissance de l’API Spark SQL et du cluster de calcul. Le petit avantage du SQL endpoint sur la connexion directe à un cluster Databricks (voir cet article) consiste dans la séparation des tâches entre clusters :
interactive cluster pour les travaux quotidiens d’exploration et de modélisation des Data Scientists
job cluster pour les traitements planifiés, de type batch
SQL endpoint pour la mise à disposition des données vers un outil de visualisation
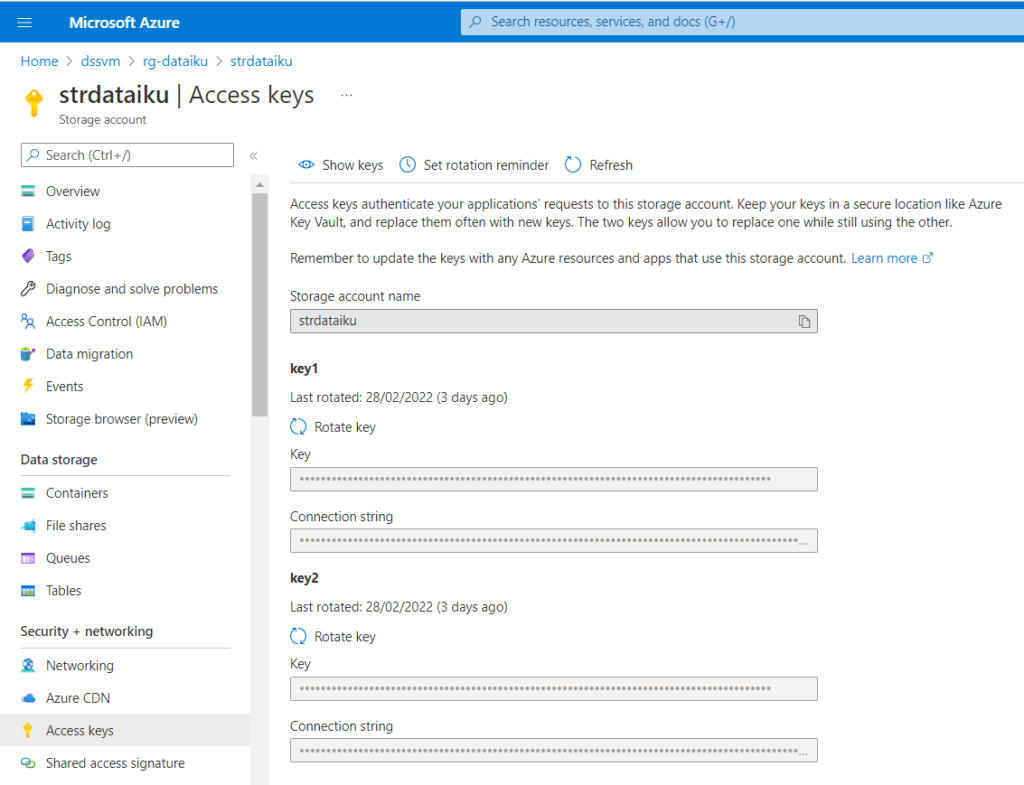
Suite à l’article initial sur l’installation de la sandbox Dataïku DSS, nous allons maintenant voir comment faire interagir le studio avec un compte de stockage Azure Blob Storage. Nous souhaiterons bien sûr lire des fichiers de données mais aussi écrire des données dite “raffinées” suite aux opérations de nettoyage et de transformation pouvant être réalisées par la plateforme de Dataïku.
Les tests relatés ci-dessous ont été réalisés avec ma collègue Sulan LIU.
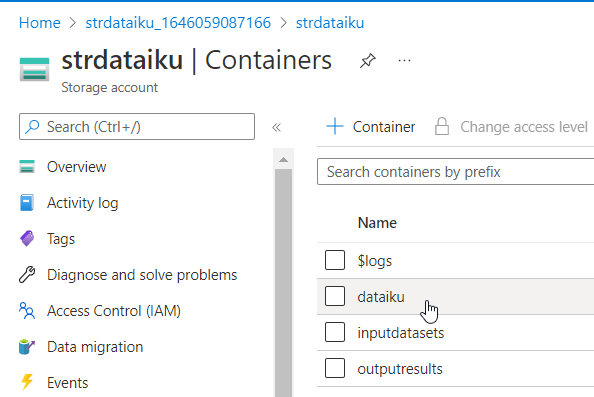
Création d’un compte de stockage blob
Nous disposons d’un compte de stockage créé sur le portail Azure, dans lequel nous pourrons définir plusieurs conteneurs (containers). Nous verrons ci-dessous l’intérêt de disposer de plusieurs de ces répertoires physiques.
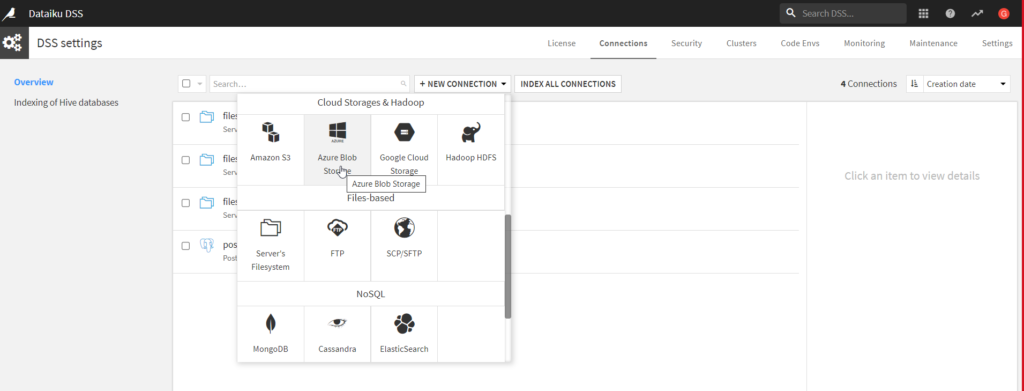
A partir du menu DSS settings puis Connections, nous pouvons cliquer sur le bouton “+NEW CONNECTION” et choisir le cloud storage Azure Blob Storage.
Nous allons maintenant détailler les principales options disponibles pour définir cette connexion.
Connection
La première information attendue est le nom que portera cette connexion du sein du Data Science Studio.
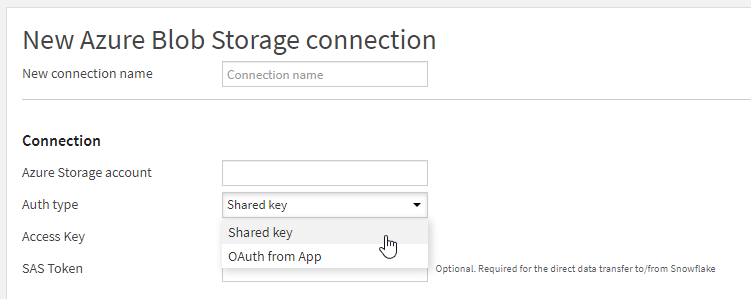
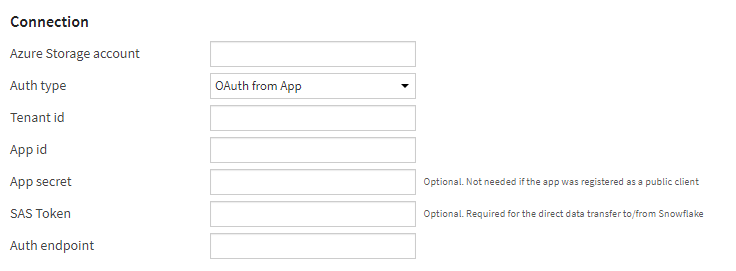
Nous pouvons ensuite choisir entre deux modes d’authentification vis à vis de la ressource Azure.
Le premier mode donne un accès total au compte de stockage au moyen du nom du compte de stockage et de la clé d’accès du compte de stockage. Selon les données contenues sur ce stockage, ce mode de connexion ne sera sans doute pas recommandé.
Nous pourrons préférer le mode de connexion “OAuth from App” correspondant à un principal de service déclaré dans l’annuaire Azure Active Directory.
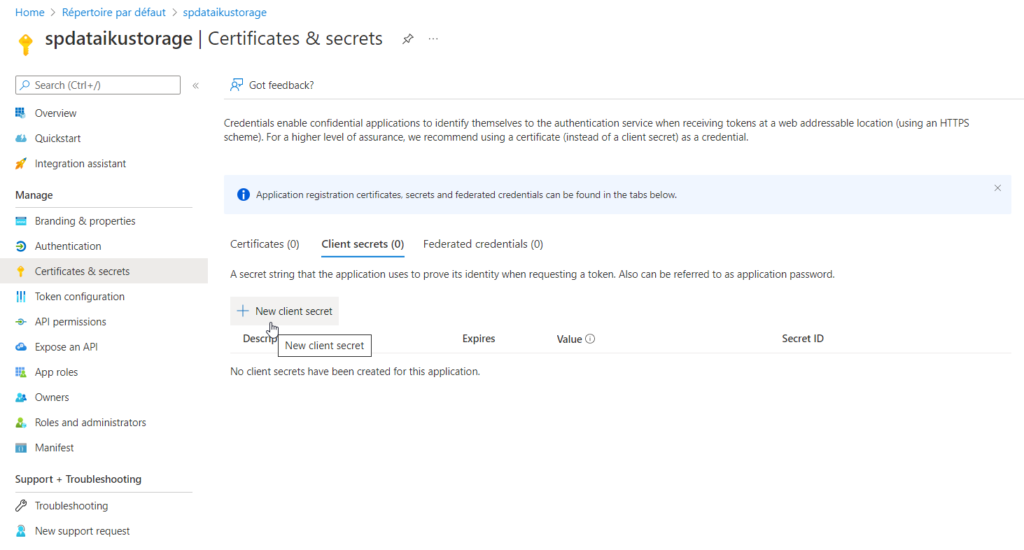
Après la création du principal de service (menu “app registration”), il faut créer un secret associé.
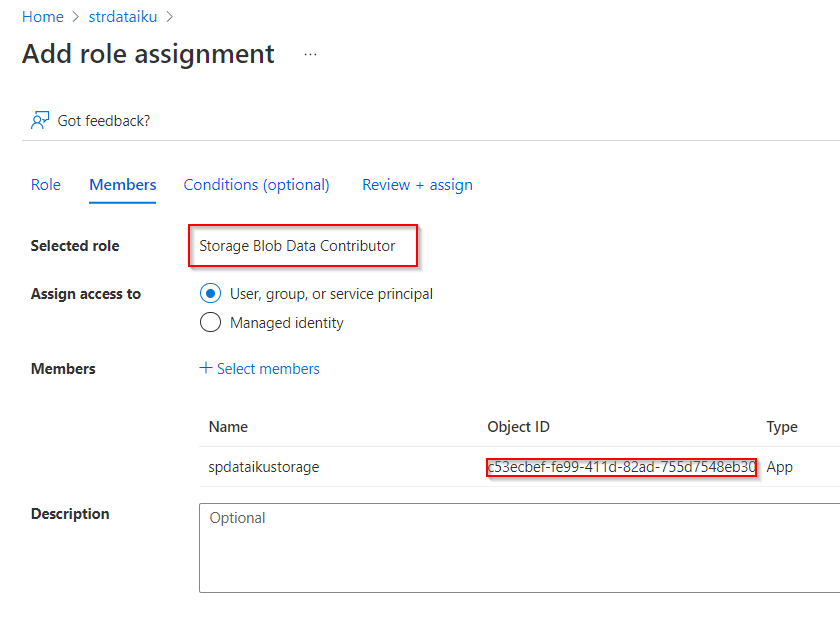
Il sera bien sûr nécessaire de donner à cette identité des droits “Storage Blob Data Contributor” sur la ressource de stockage Azure.
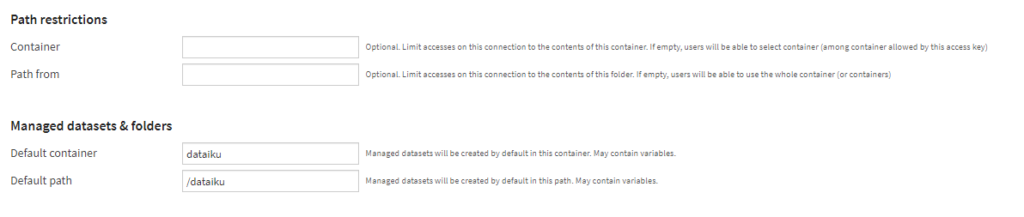
Path restriction and default container
Une connexion peut être définie vers la totalité des containers ou avec une restriction sur l’un d’eux. Une bonne pratique me semble être de définir une connexion par conteneur, afin de bien isoler les rôles (données brutes en entrée, données préparées intermédiaires, prévisions en batch…).
Si l’on ne définit pas de conteneur dans la connexion, il est impératif qu’un conteneur par défaut existe. Sans modification de la valeur par défaut, celui-ci doit être nommé dataiku (sans tréma sur le i).
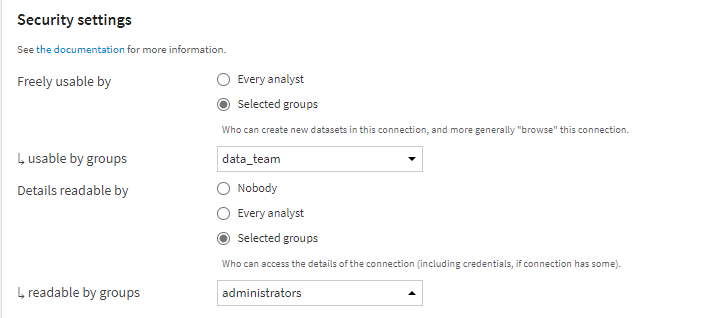
Security settings
Les paramètres de sécurité vont enfin permettre de donner des droits d’utilisation à tous les utilisateurs “analysts” ou bien seulement à des groupes.
Une bonne pratique consistera à ne donner l’autorisation “Details readable” qu’à un groupe administrateur de la plateforme. En effet, ce droit donne accès à la configuration de la connexion et donc par exemple à l’App ID (client ID) du principal de service.
Lecture et écriture de jeux de données
Nous pouvons maintenant démarrer un nouveau projet au sein du Data Science Studio et nous commençons logiquement par la définition d’un premier dataset.
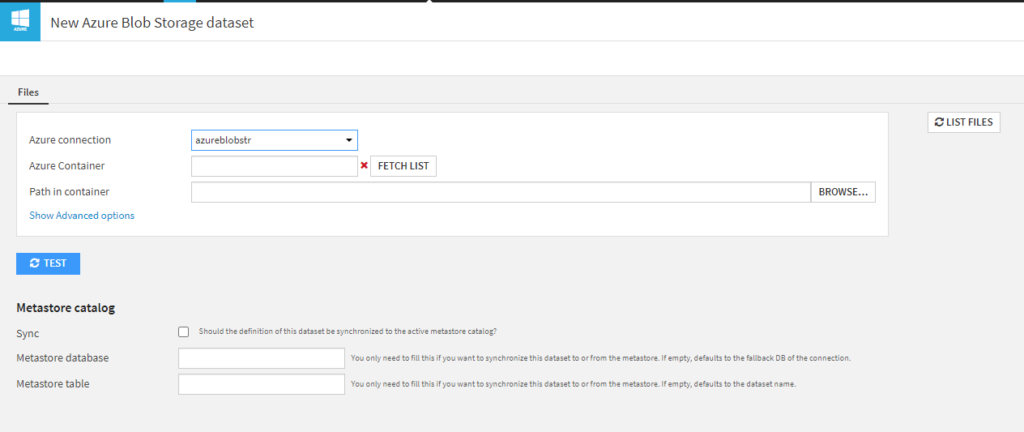
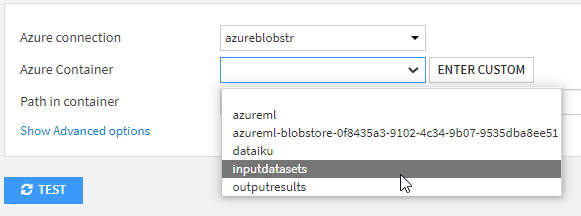
Nous vérifions que la connexion précédemment définie apparaît bien dans la première liste déroulante.
Il sera ensuite nécessaire de cliquer sur le bouton FETCH LIST pour voir apparaître les containers autorisés.
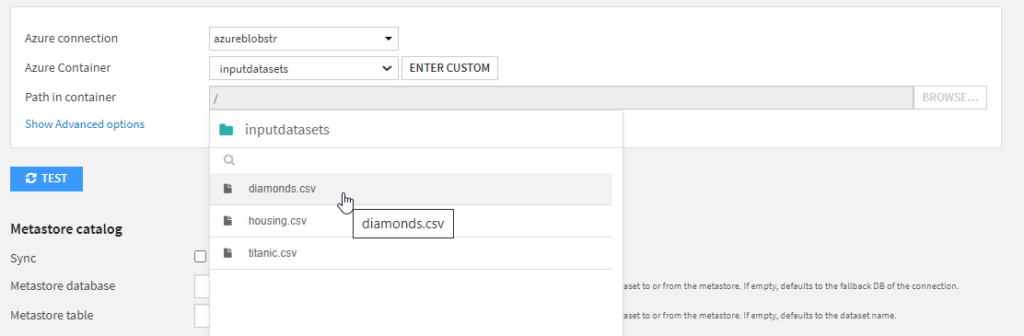
Le bouton BROWSE permet alors de choisir le fichier voulu.
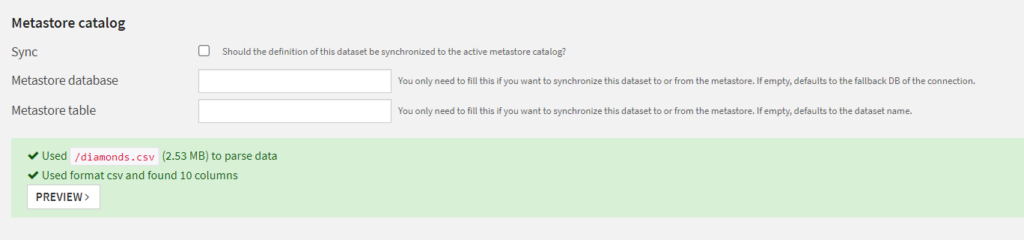
Un message nous informe du bon parsing (séparation des colonnes) du fichier.
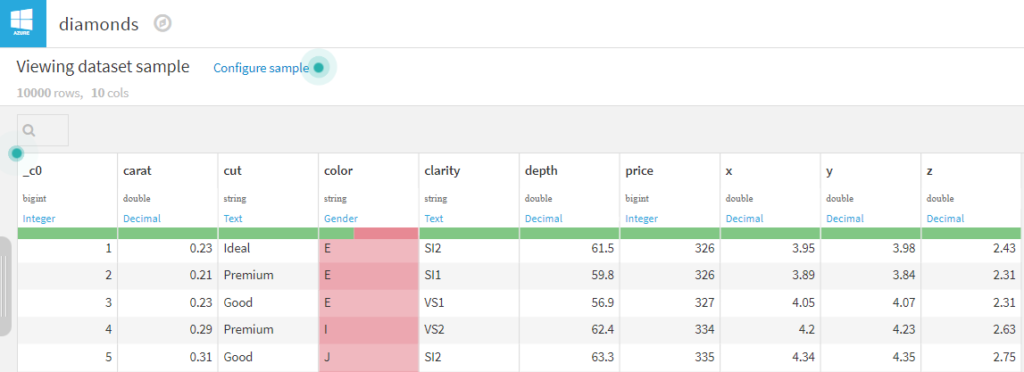
Un aperçu du jeu de données (PREVIEW) est alors disponible et nous pouvons voir que les colonnes ont été automatiquement typées. Un rapide contrôle visuel sera toutefois souhaitable. Nous pouvons par exemple rencontrer une colonne dont les premières valeurs (celles de l’aperçu) seraient vides.
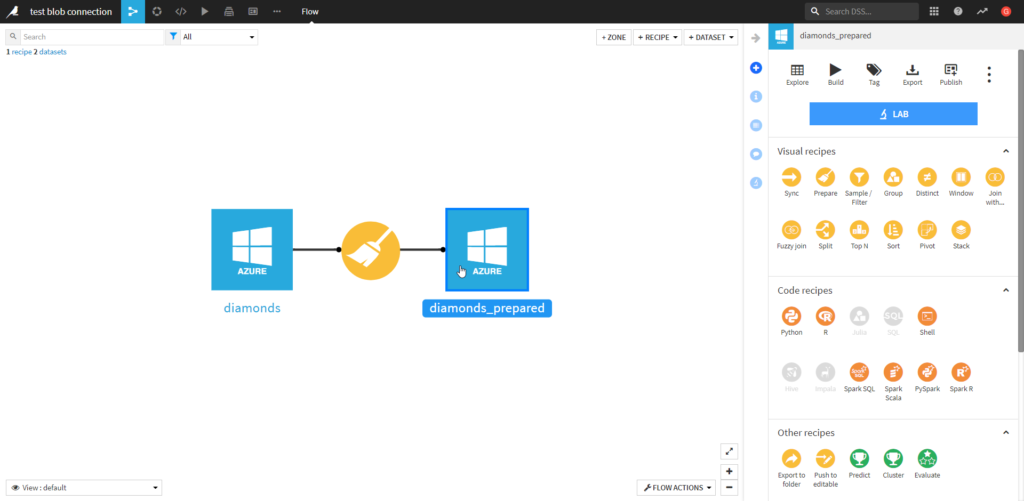
Nous pouvons maintenant construire un premier flow basé sur ce jeu de données.
Nous ajoutons quelques opérations de transformation au sein d’une “recipe“.
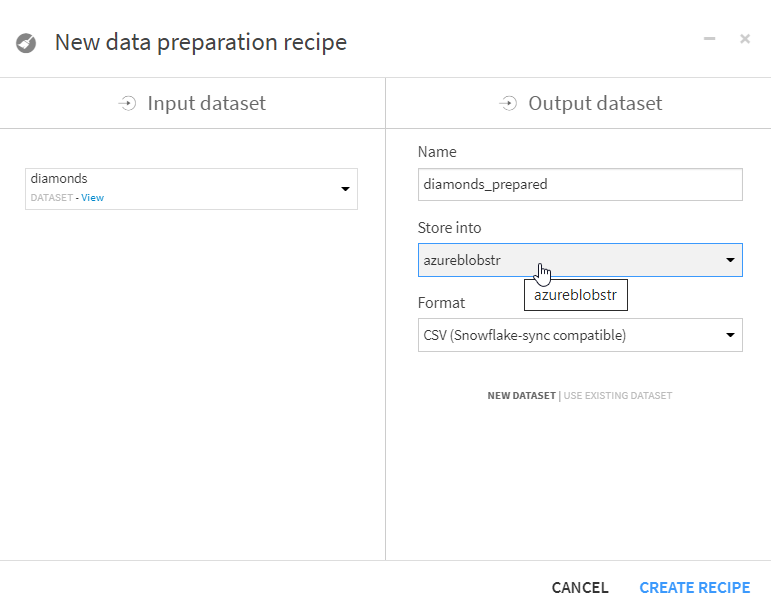
A la fin de la préparation des données, nous définissions l’output dataset. Dans la liste déroulante “Store into”, nous retrouvons naturellement la connexion définie au compte de stockage.
Vous pourriez, à cette étape, rencontrer le message d’erreur ci-dessous.
Dataset error – Failed to check if the new dataset name is safe, there could be a problem with the database: Failed to get information for location '', caused by: NoSuchElementException: An error occurred while enumerating the result, check the original exception for details., caused by: StorageException: The specified container does not exist.
Ce message nous alerte sur le fait que le container nommé “dataiku” n’a pas été créé. Veuillez vérifier ce point, présenté en tout début d’article.
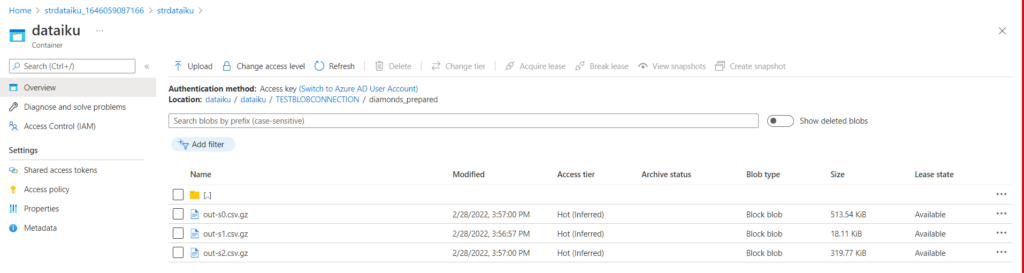
Nous vérifions que le dataset s’est bien enregistré dans le container du compte de stockage.
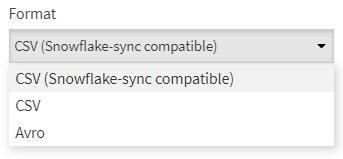
Nous remarquons que le dataset, enregistré au format CSV et compressé (.gz), est partitionné automatiquement. Nous disposons de trois choix de format, le format Avro étant un format dit orienté colonne et également compressé.
Dans la version sandbox de Dataïku DSS, nous ne pourrons en revanche pas utiliser une ressource de type Azure Synapse Analytics pour lire et écrire des données. En effet, un driver JDBC est nécessaire mais les répertoires de la machine virtuelle ne sont pas accessibles. Nous aborderons donc la version Enterprise de Dataïku DSS dans de prochaines articles.
En France, le milieu de la Data Science connaît bien, de réputation au moins, la société Dataïku et son Data Science Studio qui s’est imposé comme l’une des plateformes SaaS les plus performantes du marché. Le cadran Gartner a reconnu la société qui est aujourd’hui implantée à New-York.
Si la plateforme peut être installée sur les serveurs de l’entreprise, il est également possible de l’utiliser, supportée par les ressources du Cloud, en particulier, le cloud Azure de Microsoft.
Utiliser Dataïku DSS au sein d’Azure
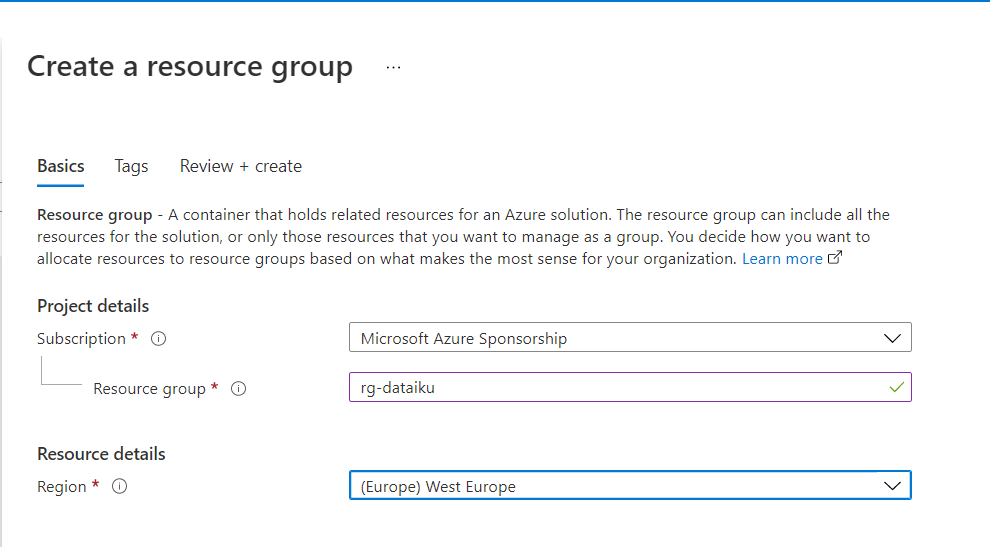
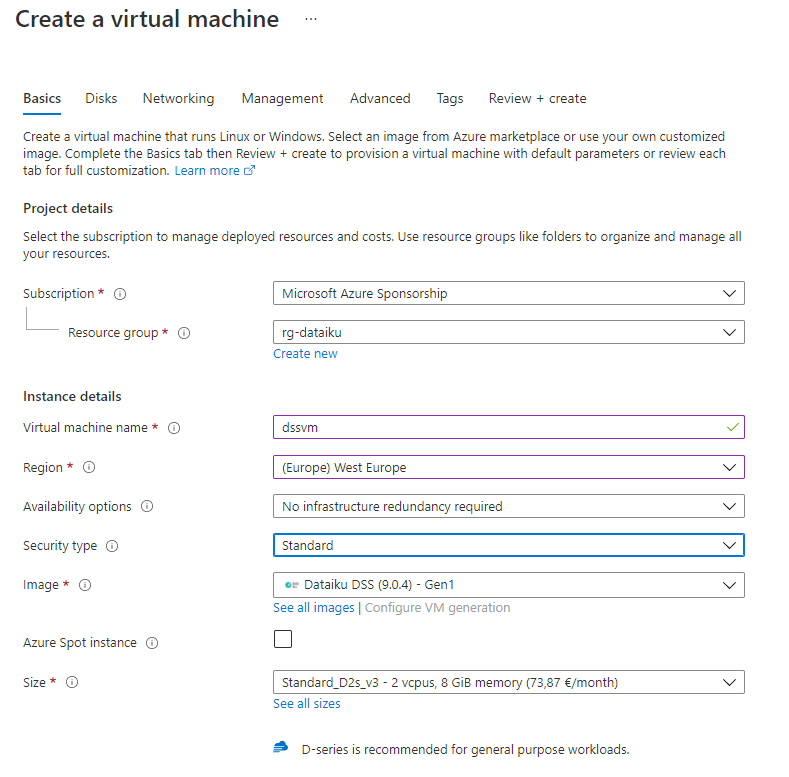
Nous allons commencer par créer un groupe de ressources Azure dédié à Dataïku DSS.
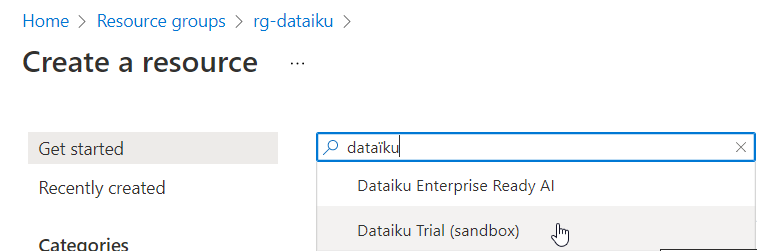
Dans la Market Place Azure, nous trouvons deux entrées :
Dataïku Enterprise Ready AI
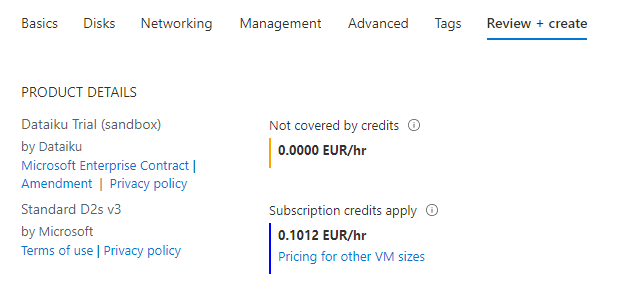
Dataïku Trial (sandbox)
Nous allons commencer par la version “bac à sable” et de prochains articles traiteront de la version Enterprise.
La tarification se fait sur le temps où la machine virtuelle Linux est allumée, et en fonction du type de machine choisie.
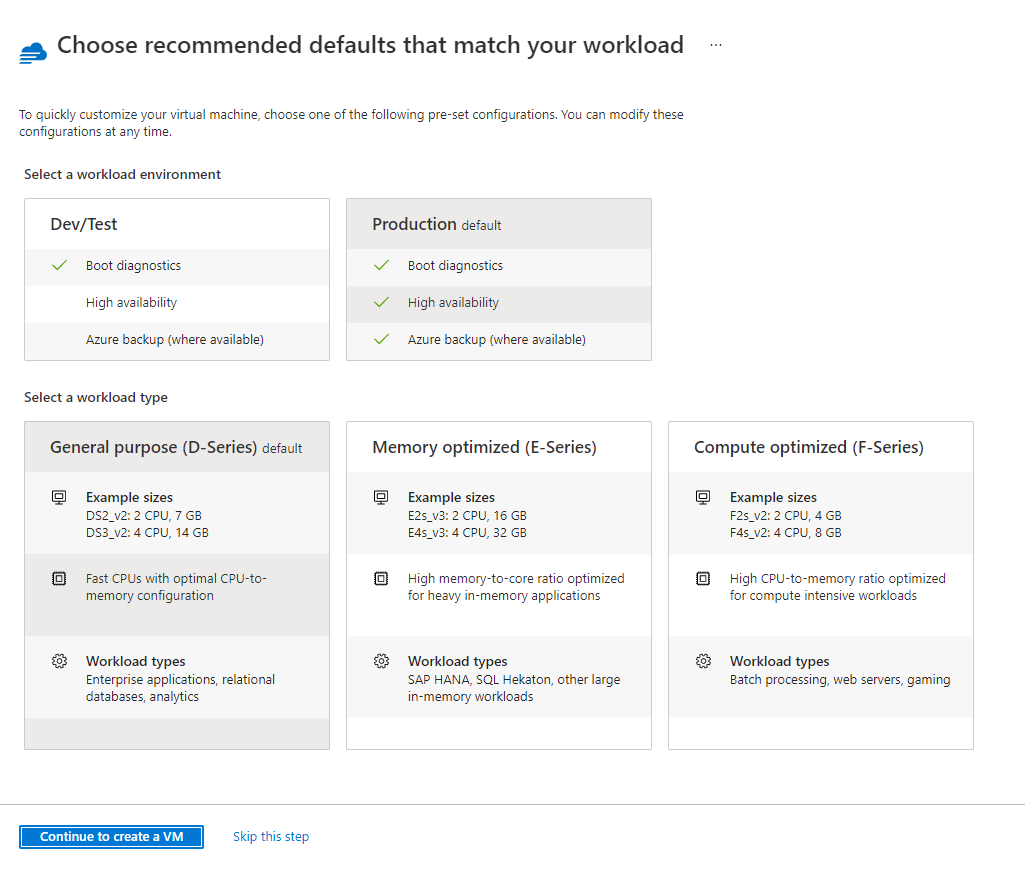
Le choix de la configuration d’installation se fait entre deux modes :
Dev/Test
Production
La configuration de la machine virtuelle se termine en choisissant une image contenant l’installation de Dataïku DSS.
Nous disposerons ainsi de la version 9 de Dataïku DSS, dont le descriptif est disponible sur cette page.
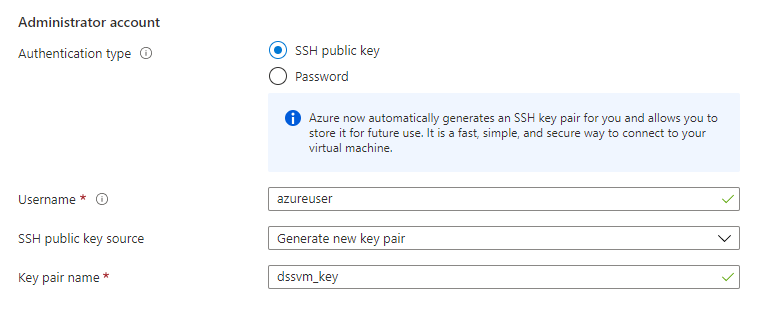
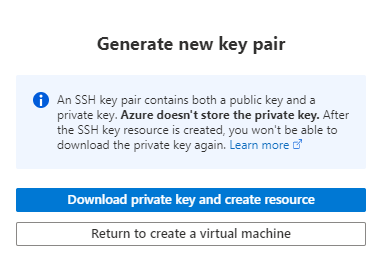
Il sera sûrement nécessaire de se connecter directement à cette machine et nous choisissons le mode SSH, qui demandera la création d’un clé privée, à télécharger sur le poste depuis lequel nous accèderons à la machine. Pensez à utiliser WSL pour faciliter toutes les opérations en lien avec les machines virtuelles Linux ! Mais attention, en version sandbox, les répertoires d’installation de Dataïku ne seront pas accessibles. Cela nous empêchera en particulier d’installer un driver JDBC nécessaire pour communiquer avec une ressource Azure Synapse Analytics mais nous y reviendrons dans un prochain article.
Il ne sera enfin pas possible de se connecter avec une identité présente dans l’annuaire Azure AD.
Nous terminons le processus de création sur un récapitulatif tarifaire, indiquant bien que nous ne serons facturés que sur l’utilisation de la machine virtuelle.
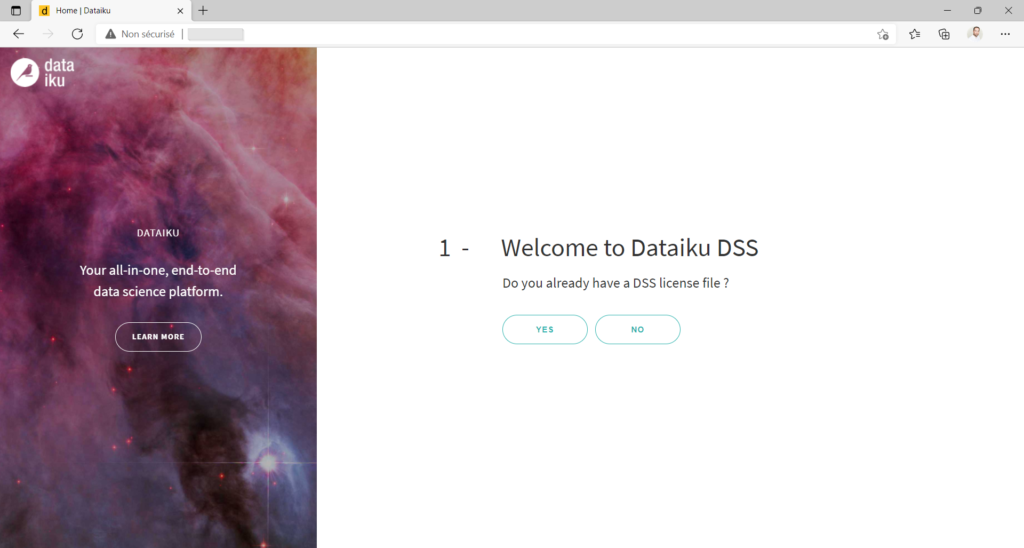
Il suffit maintenant de saisir l’IP publique de la machine virtuelle Linux dans un navigateur (connexion http non sécurisée pouvant lever une alerte dans votre navigateur).
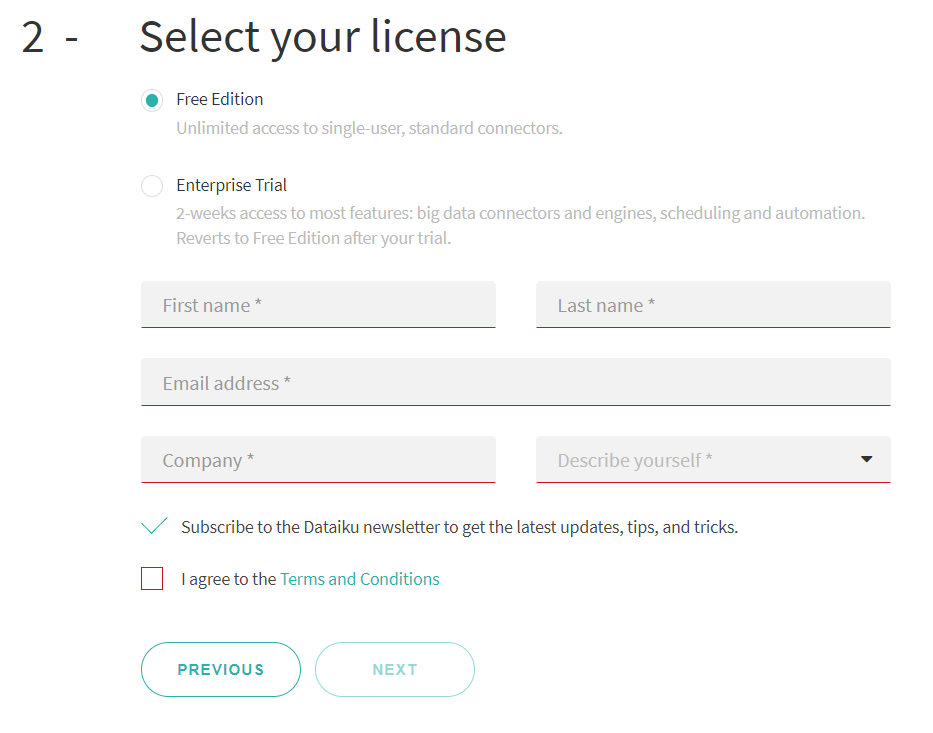
Sans licence, nous cliquons sur “NO” afin d’entamer la phase d’évaluation du produit ou son utilisation gratuite (Free Edition).
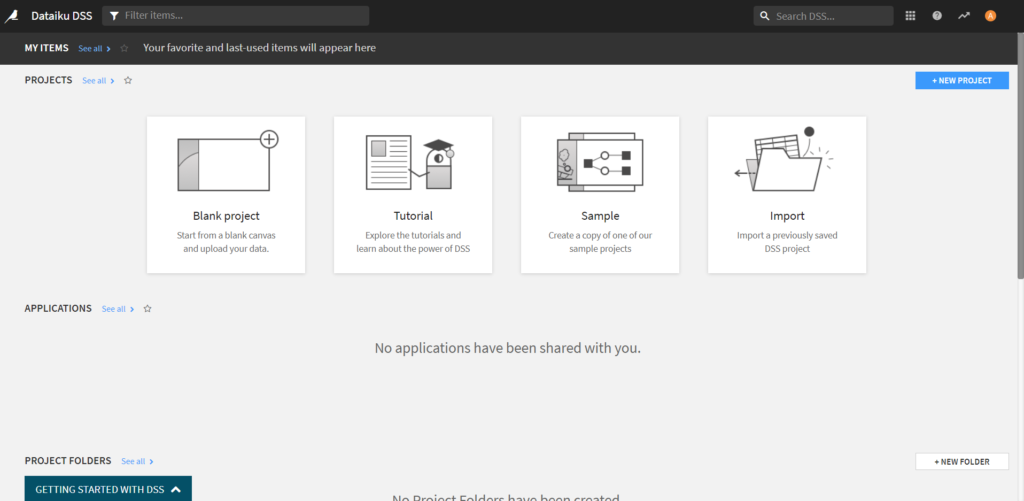
Le Studio est maintenant prêt et nous disposons d’un login / password (admin /admin par défaut) pour nous reconnecter ultérieurement.
Nous voici dans le Data Science Studio.
Si vous utilisez à plusieurs cette ressource, il est recommandé de créer d’autres comptes utilisateurs.
De prochains articles viendront présenter les interactions de Dataïku DSS avec différentes ressources Azure :
Azure Storage Account (blob ou Data Lake gen2) pour le stockage de données
Azure Synapse Analytics – SQL pool (anciennement DataWarehouse) comme source de données ou cible d’écriture
Azure Synapse Analytics – Spark pool comme ressource de calcul, en particulier pour les entrainements
Azure Kubernetes Services en particulier pour le serving de modèles
Le cluster Spark managé que propose Azure Databricks permet l’exécution de code, présent dans des notebooks, dans des scripts Python ou bien packagés dans des artefacts JAR (Java) ou Wheel (Python). Si l’on imagine une architecture de production, il est nécessaire de disposer d’un ordonnanceur (scheduler) afin de démarrer et d’enchaîner les différentes tâches automatiquement.
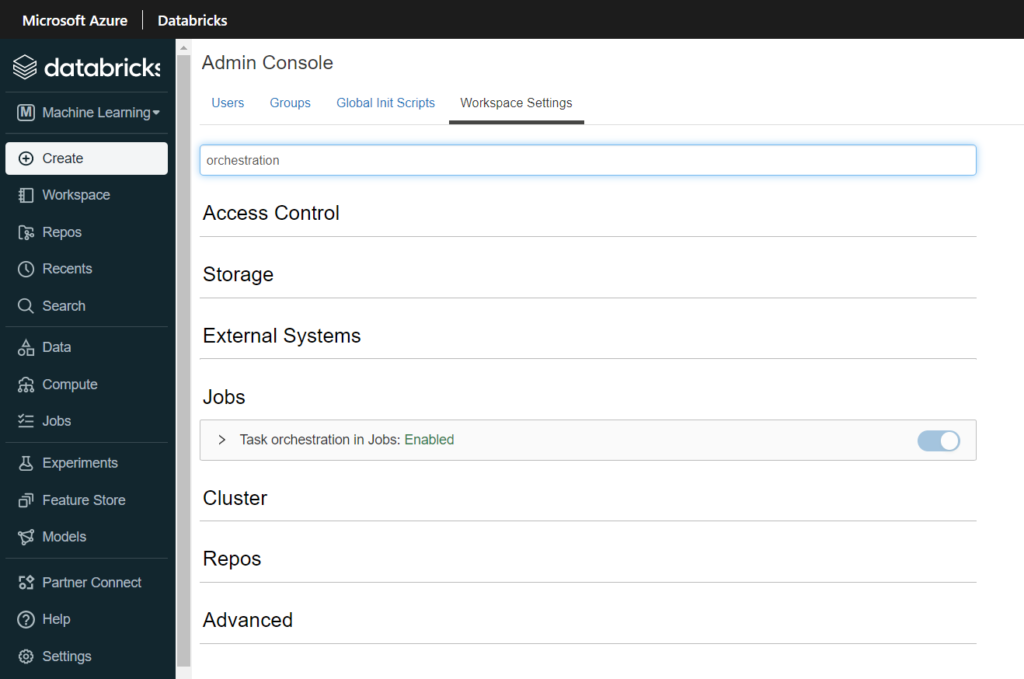
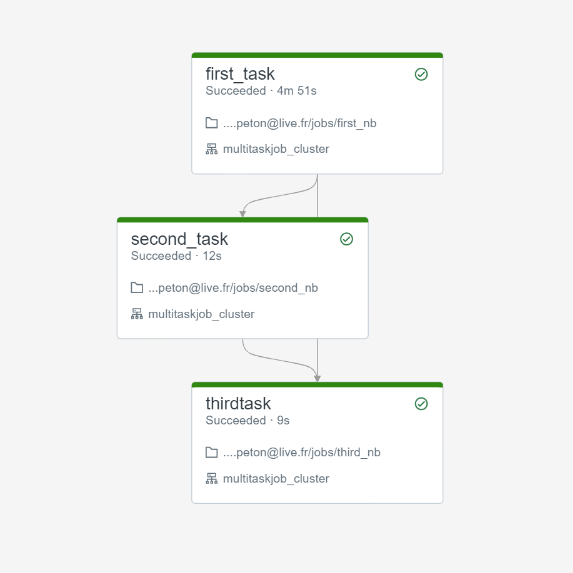
Nous connaissions déjà les jobs Databricks, nous pouvons dorénavant enchaîner plusieurs tasks au sein d’un même job. Chaque task correspond à l’exécution d’un des éléments cités ci-dessus (notebook, script Python, artefact…). Comme il s’agit à ce jour (mars 2022) d’une fonctionnalité en préversion, il est nécessaire de l’activer dans les Workspace Settings de l’espace de travail.
Le principal intérêt d’enchainer des tasks à l’intérieur d’un même job est de conserver le même job cluster, qui se différencie des interactive clusters par… sa tarification ! En effet, celui-ci est environ deux fois moins cher qu’un cluster utilisé par exemple pour des explorations menés par les Data Scientists.
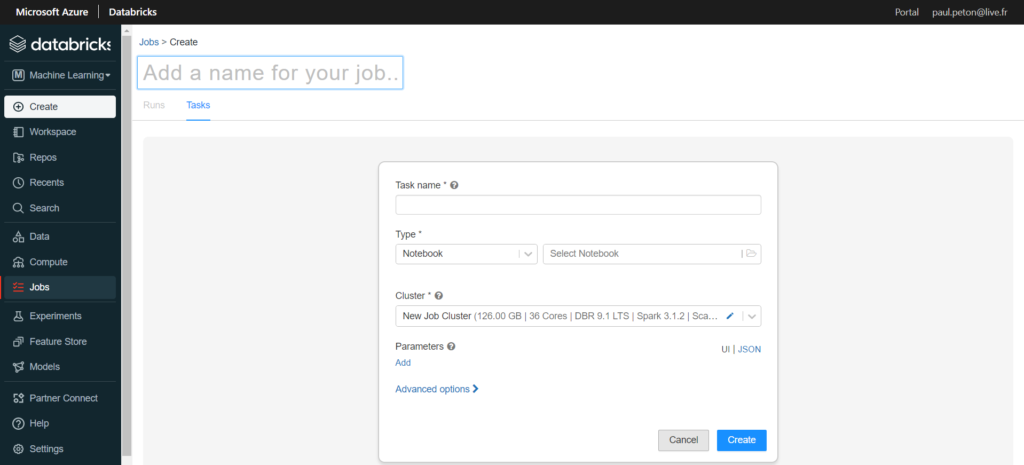
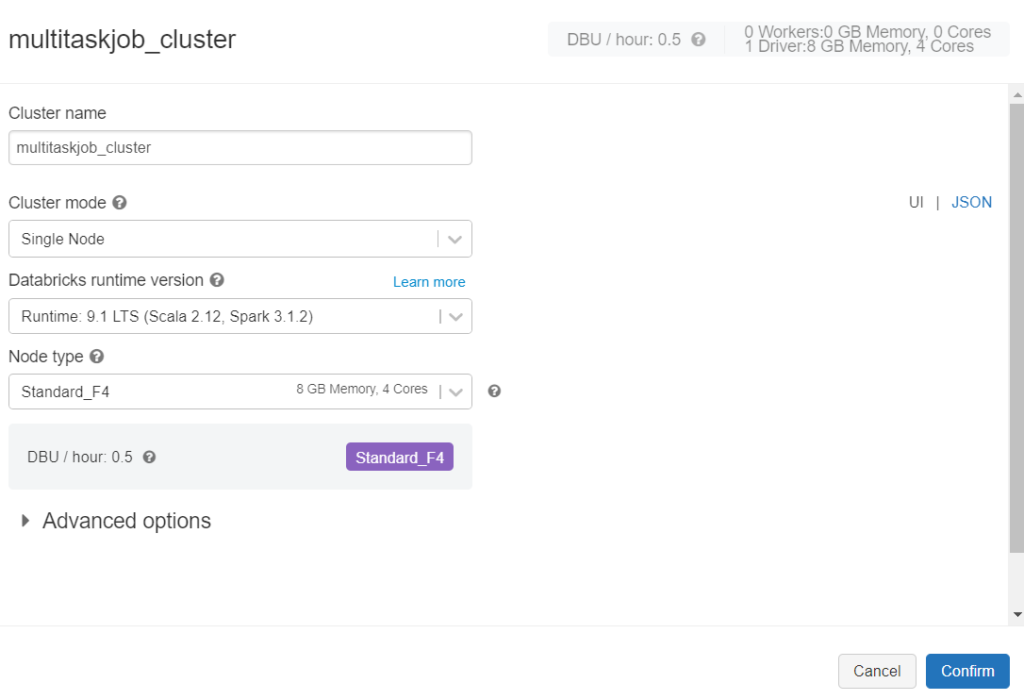
Le menu latéral nous permet de lancer la création d’un nouveau job (pensez à bien le nommer dans la case située en haut à gauche).
Pour réaliser nos premiers tests, nous utiliserons un job cluster de type “single node”, associée à une machine virtuelle relativement petite.
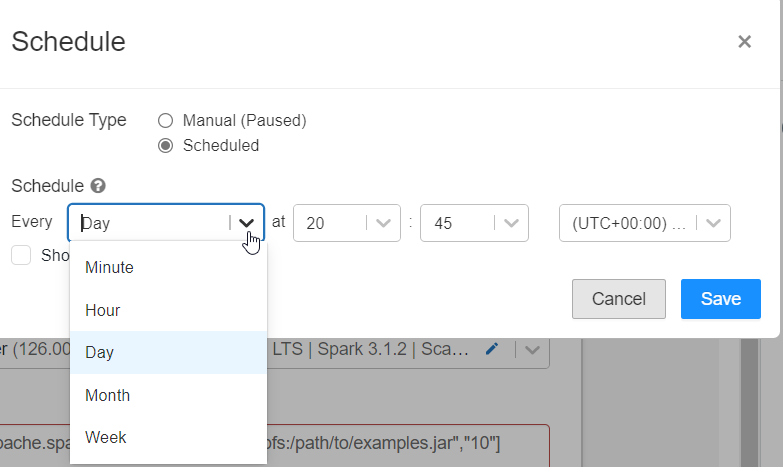
Le job se planifie à un moment donné, défini par une interface graphique ou une syntaxe classique de type CRON telle que : 31 45 20 * * ?
Syntaxe CRON : 31 45 20 * * ?
Nous pourrons retrouver tous les logs d’exécution dans l’interface “jobs” de l’espace de travail.
Passer des informations d’une tâche à une autre
L’enchainement de tâches nous pousse rapidement à imaginer des scénarios où une information pourrait être l’output d’une tâche et l’input de la suivante. Malheureusement, il n’existe pas à ce jour de fonctionnalité native pour répondre à ce besoin. Nous allons toutefois explorer ci-dessous deux possibilités. Il existe également quelques variables réservées pouvant être passées en paramètres de la tâche : job_id, run_id, start_date…
Passer un DataFrame à une autre tâche
Nous nous orienterons tout naturellement vers le stockage d’une table dans le metastore de l’espace de travail Databricks.
écriture d’un DataFrame en table : df = spark.read.parquet(‘dbfs:/databricks-datasets/credit-card-fraud/data/’)
lecture de la table : df = spark.table(“T_credit_fraud”)
Ceci ne peut être réalisé avec une vue temporaire, créée au moyen de la fonction createOrReplaceTempView(), celle-ci disparaissant en dehors de l’environnement créé pour son notebook d’origine.
Passer une valeur à une autre tâche
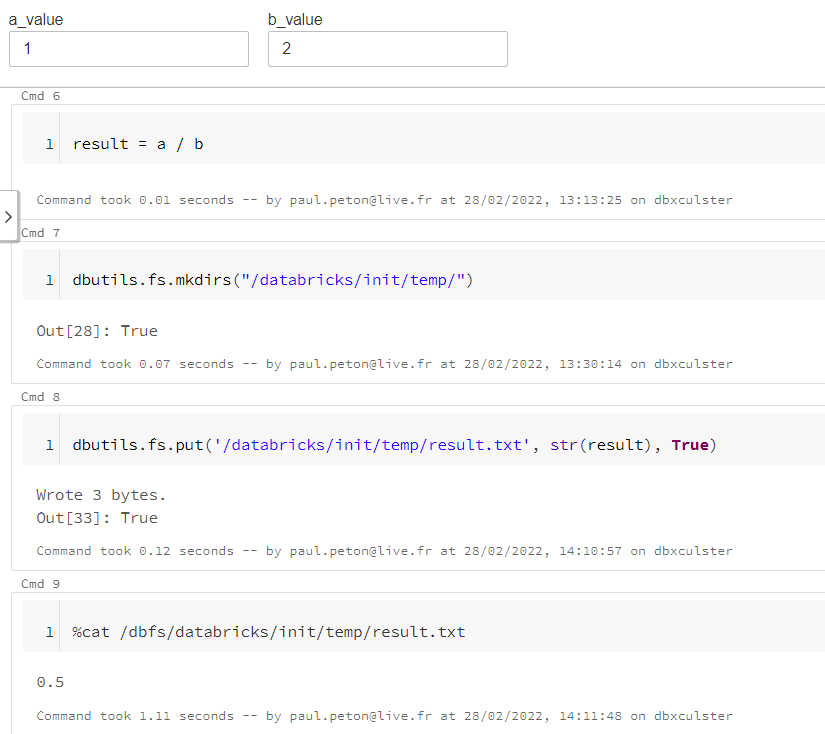
Nous profitons du fait que le job cluster soit commun aux différentes tâches pour utiliser le point de montage /databricks et y écrire un fichier. Nous pouvons ainsi exploiter les commandes dbutils et shell (magic command %sh) :
dbutils.fs.mkdirs() permet de créer un répertoire temporaire
dbutils.fs.put() écrit une chaîne de texte dans un fichier
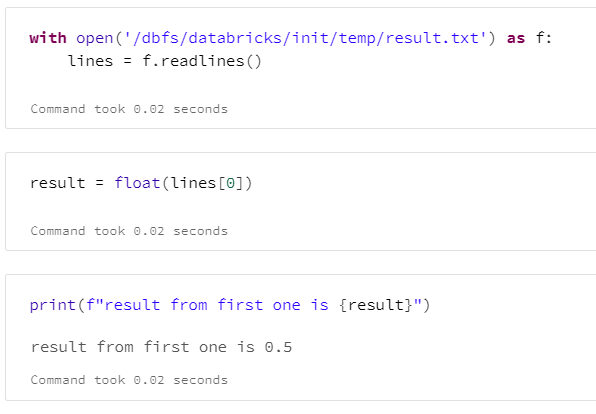
Nous vérifions ici la bonne écriture de la valeur attendue mais la commande shell cat ne permet pas de stocker le résultat dans une variable. Nous utiliserons une commande Python open() en prenant soin de préfixer par /dbfs le chemin du fichier créé lorsla tâche précédente. Attention également à bien récupérer le premier élément de la liste lines avec [0] puis à convertir la valeur dans le type attendu.
Quand continuer à utiliser Azure Data Factory ?
Dans une architecture data classique sous Azure, et orientée autour des outils PaaS, c’est le service Azure Data Factory qui est généralement utilisé comme ordonnanceur.
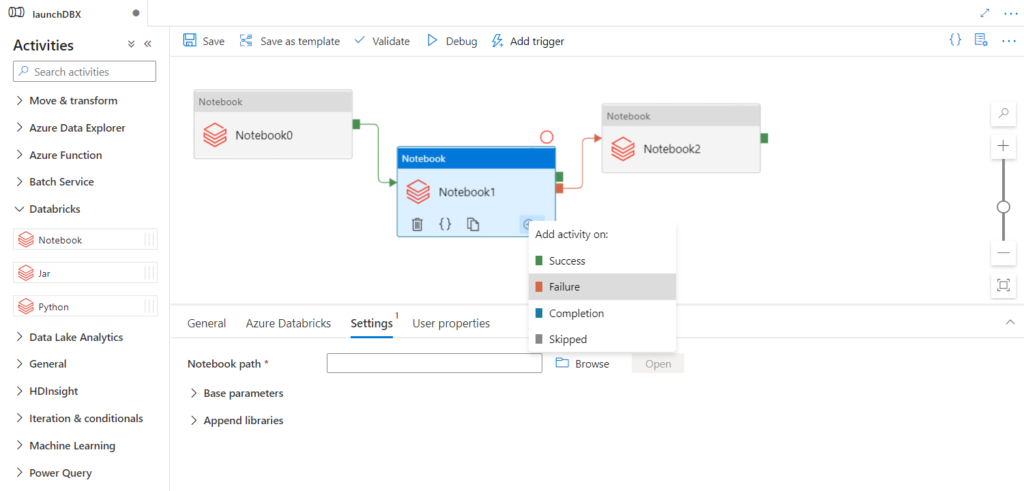
Si l’enchainement des tâches peut se conditionner en utilisant le nom des tâches précédentes, celui-ci n’aura lieu qu’en cas de succès des autres tâches.
Il n’est donc pas possible de prévoir un scénario similaire à celui présenté ci-dessous, où l’enchainement se ferait sur échec d’une étape précédente.
Les déclenchements de jobs Databricks ne se font que sur une date / heure alors qu’il serait possible dans Azure Data Factory de détecter l’arrivée d’un fichier, par exemple dans un compte de stockage Azure, puis de déclencher un traitement par notebook Databricks.
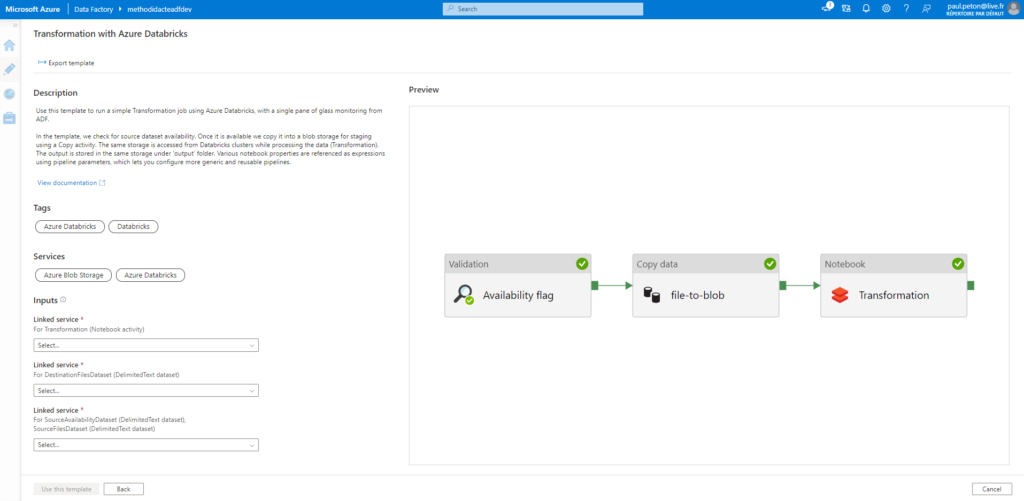
Template “Transformation with Azure Databricks”
Côté fonctionnalité de Data Factory, nous attendons que les activités Databricks puissent exécuter également des packages Wheel, comme il est aujourd’hui possible de le faire pour les JAR. Une solution de contournement consistera à utiliser la nouvelle version de l’API job de Databricks (2.1) dans une activité de type Web.
En conclusion, il s’agit là d’une première avancée vers l’intégration dans Databricks d’un nouvel outil indispensable à une approche DataOps ou MLOps, même si celui-ci est pour l’instant incomplet. Les fonctionnalités de Delta Live Tables, encore en préversion également, viendront aussi compléter les tâches traditionnellement dévolues à un ETL.
Azure Data Factory est un service managé du cloud Azure, de type “low code”, aussi bien utile pour ses fonctionnalités d’ETL/ELT que d’ordonnanceur. On appréciera particulièrement d’y intégrer toute une chaîne de traitements et d’avoir ainsi un espace centralisé de lecture des logs d’exécution.
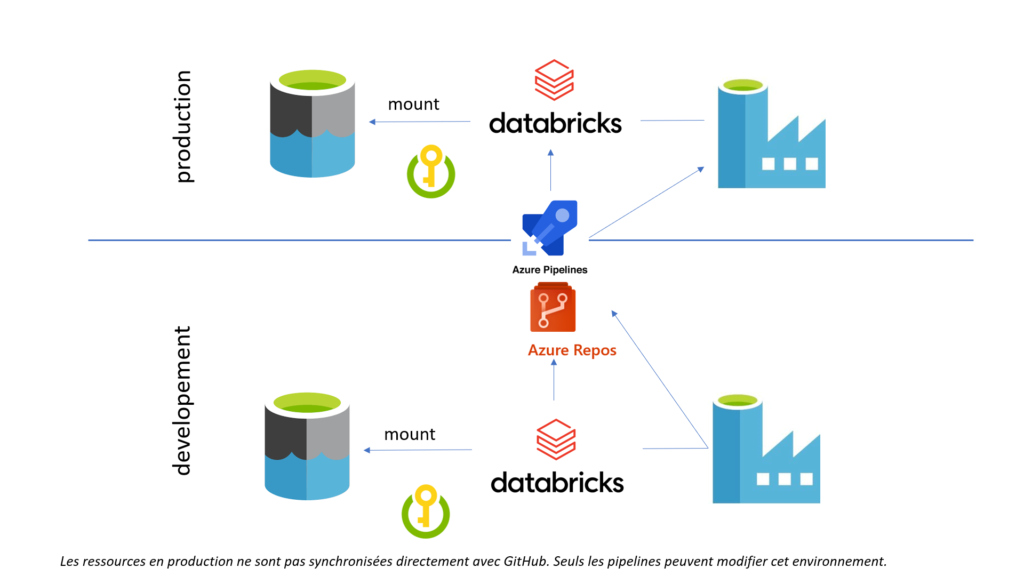
Si ce service commence à prendre de l’importance dans vos projets data, vous souhaiterez certainement développer dans une ressource qui n’est celle de production. Se posera donc alors la question du déploiement continu entre ressources.
Lier Data Factory à un repository
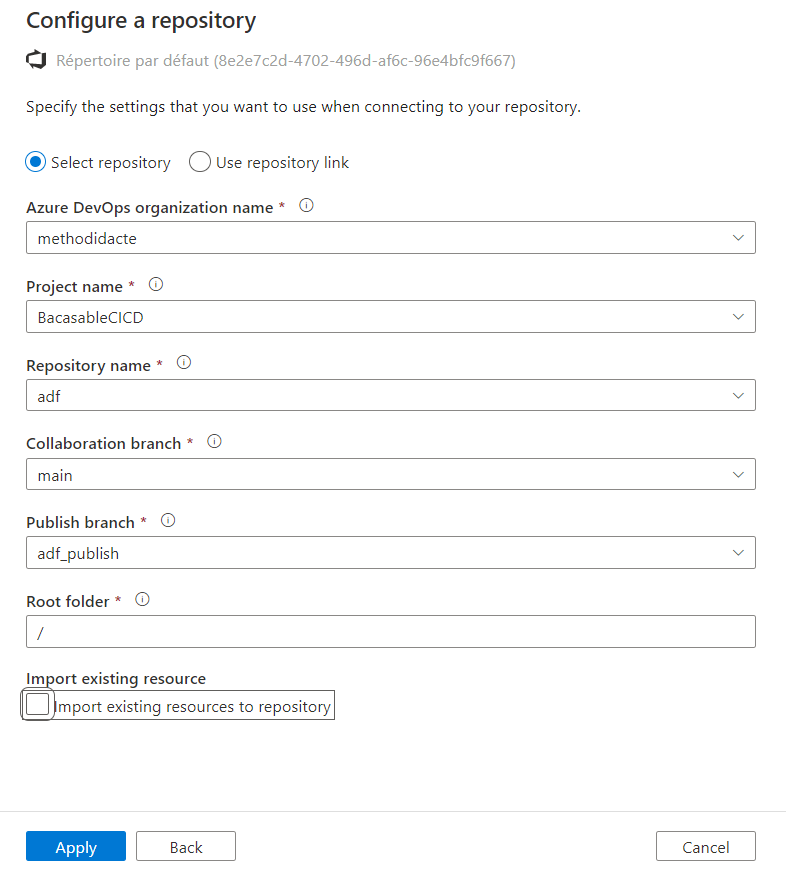
Avant de déployer, il est bien sûr nécessaire de versionner les développements ! Cela sera possible dans l’un des deux outils du monde Microsoft : GitHub ou Azure DevOps. Il est possible de définir le repository à la création de la ressource mais nous pouvons le faire, plus facilement, après l’instanciation.
A la première connexion au Studio Data Factory, nous configurons le repository, en choisissant ici une organisation et un projet Azure DevOps. Il n’est pas nécessaire d’importer le contenu de ce repository qui doit être vide pour l’instant.
Décocher la case “Import existing resource”
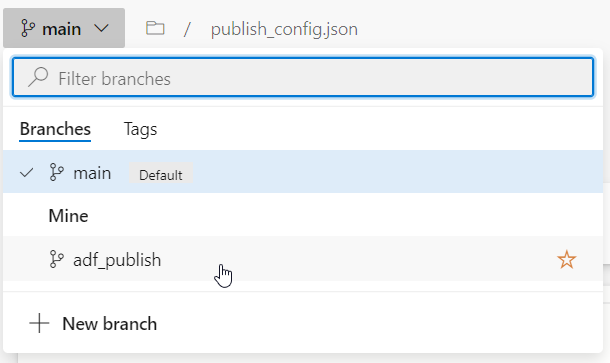
Notons tout de suite un fonctionnement propre à Data Factory que sera le travail sur deux branches :
une branche principale (nommée ici main), de collaboration
une branche de “publication” au nom réservé : adf_publish
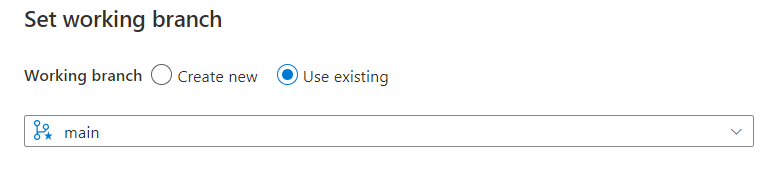
Nous verrons lors du déploiement le rôle joué par cette seconde branche. Nous terminons la configuration en définissant la branche main comme la branche de travail.
Il sera possible par la suite de créer des branches apportant de nouvelles fonctionnalités ou réalisant des corrections puis d’effectuer des opérations de merge (fusion) avec la branche principale.
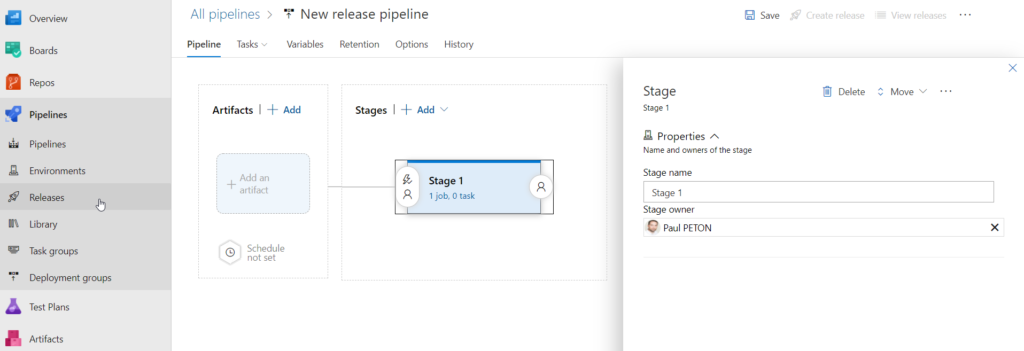
Terminons cette première partie sur une notion fondamentale : les environnements de destination lors du déploiement (pré-production, production…) ne doivent pas être liés au repository. C’est en effet une opération spécifique (un pipeline de release) qui viendra déposer le code, mais ce dernier ne doit pas pouvoir être modifié en dehors de l’environnement de développement.
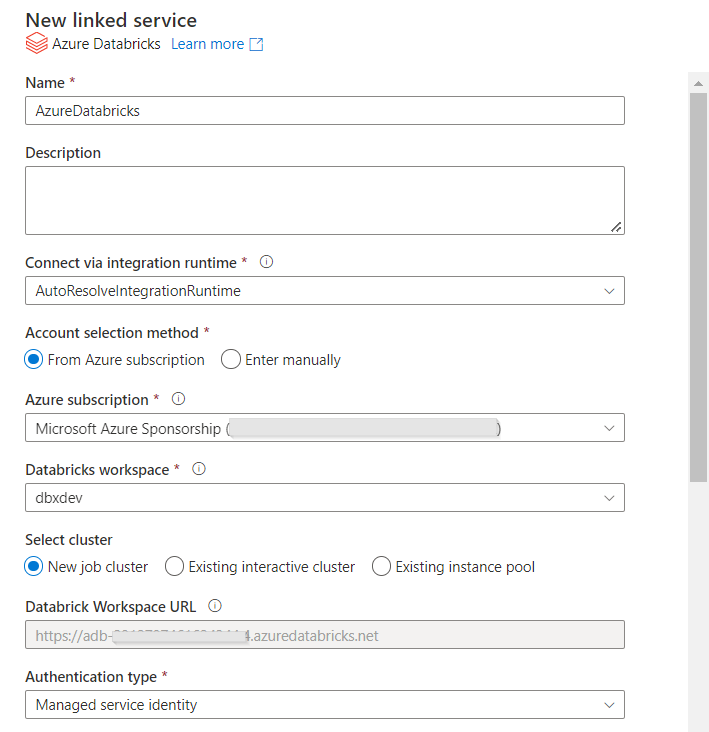
Créer un premier service lié
Les services liés sont les premiers éléments à créer dans Data Factory car ils “hébergent” les datasets ou représentent une ressource de calcul comme c’est le cas pour le service de clusters Spark managé Azure Databricks. Ce sont aussi les services liés qui sont les plus dépendants des environnements (dev, uat, prod…) car ils pointent vers d’autres ressources auprès desquelles une authentification est bien souvent nécessaire.
Voici une bonne pratique : ne pas utiliser un nom spécifique à l’environnement (par exemple ls_DatabricksDev) car ce nom doit refléter la ressource dans chaque environnement et nous ne pourrons pas le modifier.
En revanche, plusieurs propriétés ainsi que l’authentification devront être modifiées lors du déploiement entre environnements.
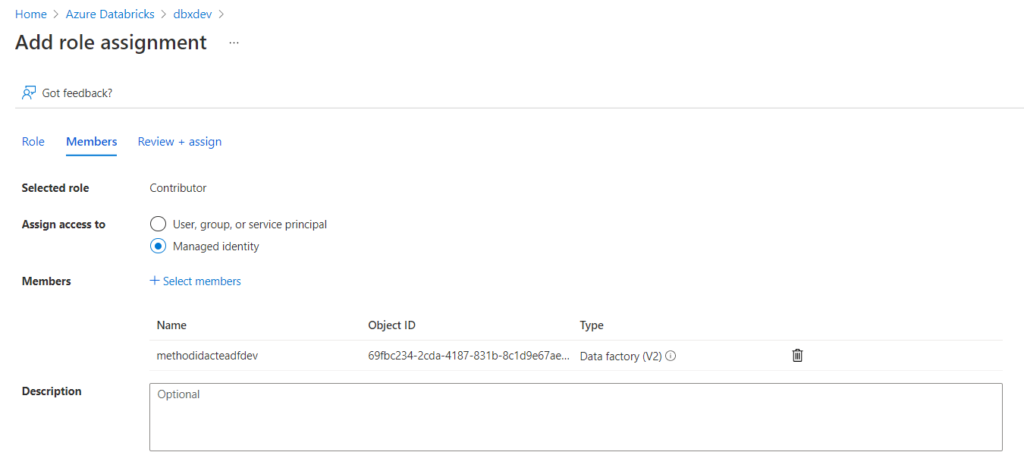
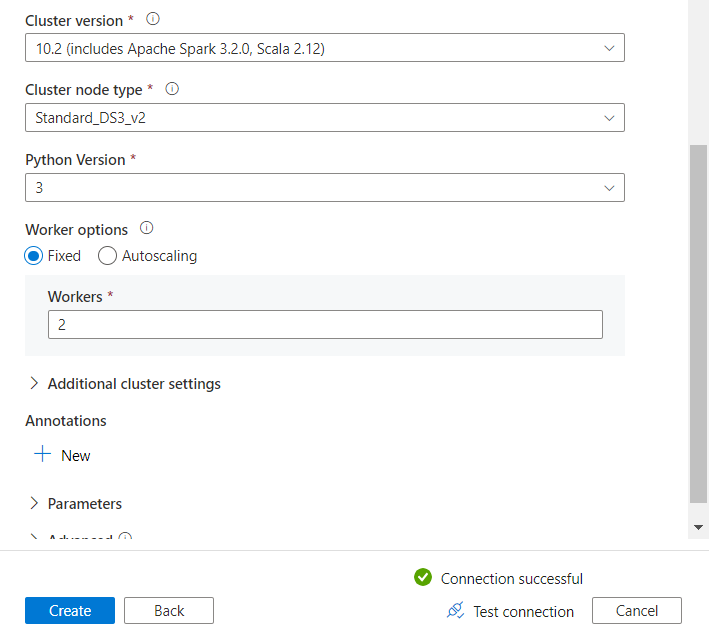
Pour un service lié Databricks, nous choisissons de nous authentifier à l’aide d’une identité managée, qu’il faudra déclarer en tant que “Contributor” au niveau de l’access control (IAM) de la ressource Databricks.
Pour vérifier que l’authentification est bien réalisée, nous déroulons les listes “cluster version” et “cluster node type”, remplacées par un message “failed” si la connexion n’est pas valide.
Il s’agit là d’une autre bonne pratique : privilégier les identités managées car celles-ci ont un périmètre très bien défini, appartiennent à l’annuaire Azure Active Directory et ne demanderont pas de manipulation lors du déploiement continu, à l’inversion d’un token ou d’un password.
Lors de la création ou de la modification d’éléments dans le Studio Data Factory, nous pouvons sauvegarder ces changements à tout moment puis réaliser une publication à l’aide du bouton “Publish”.
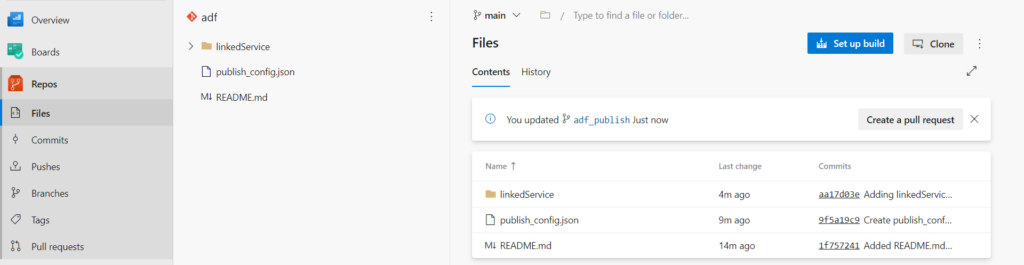
L’action Publish correspond à un “commit – push” sur le repository lié.
Nous retrouvons dans le repository les deux branches évoquées lors de l’association à Azure DevOps.
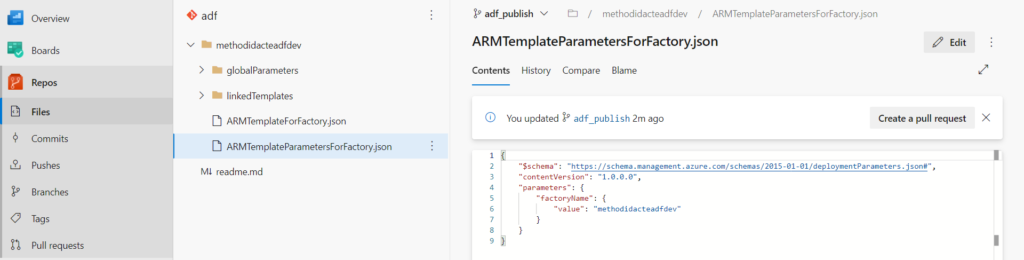
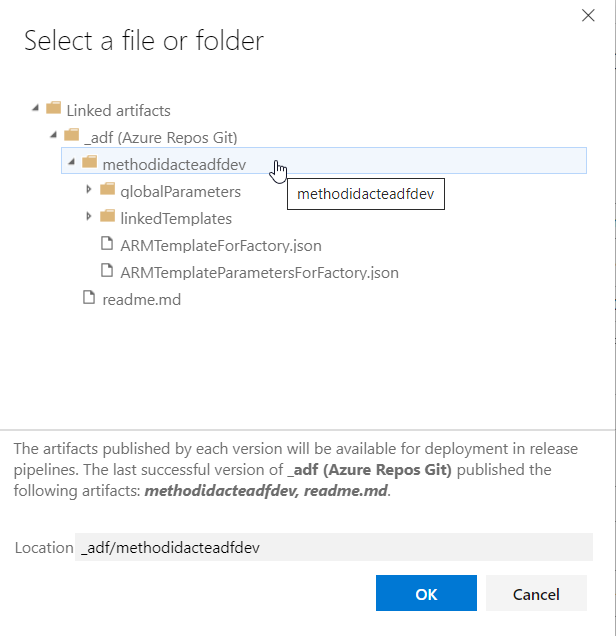
La branche adf_publish contient en particulier deux fichiers nommés respectivement ARMTemplateForFactory.json et ARMTemplateParametersForFactory.json. Ceux-ci contiennent les noms propres à l’environnement et qui devront donc être remplacés lors du déploiement.
Le nom de la ressource ADF est le premier paramètre propre à l’environnement.
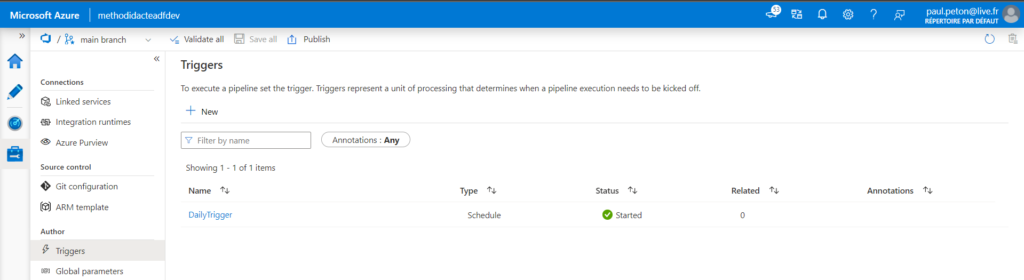
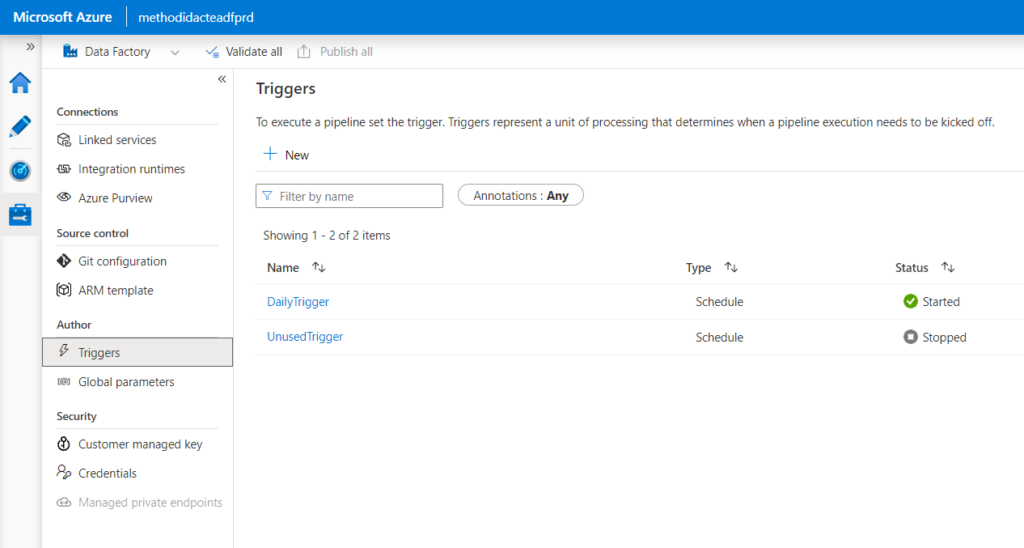
Afin de pousser la démonstration, nous ajoutons et démarrons un trigger dans le Studio Data Factory (nous verrons son importance un peu plus tard dans cet article).
Déployer par pipeline de release
Le pipeline de release convient à ce que nous cherchons à faire : déployer un environnement vers un autre, à partir d’un code versionné.
Nous démarrons le pipeline avec un “empty job”.
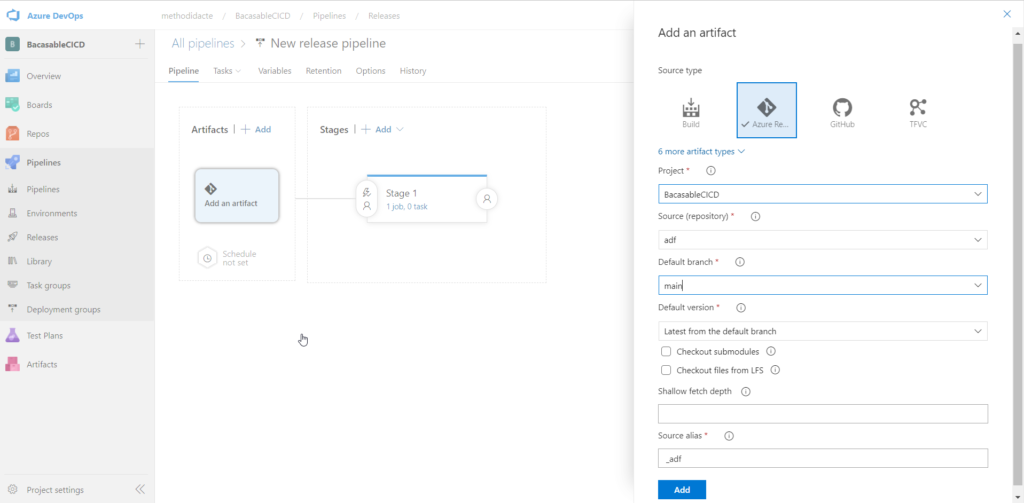
La première chose à faire est de lier l’artefact (le code versionné) au pipeline. Attention, c’est bien la branche main et non adf_publish qui est attendue ici.
La branche par défaut est la branche main.
Passons ensuite au paramétrage du stage, qui pourra être renommé par le nom de l’environnement cible (uat, prod…).
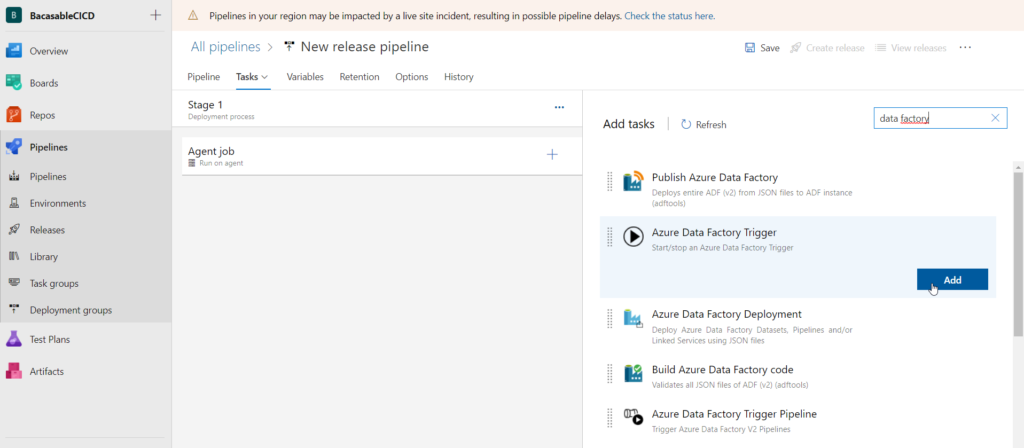
Nous recherchons dans la Market Place les tâches correspondant à Data Factory. Une installation sera nécessaire à la première utilisation.
Je vous recommande le produit développé par SQLPlayer. En effet, nous allons voir de multiples avantages (et un inconvénient…).
Autoriser le composant à accéder à une ressource Azure va demander de créer une service connection. Des droits suffisants sur Azure sont nécessaires pour réaliser cette opération.
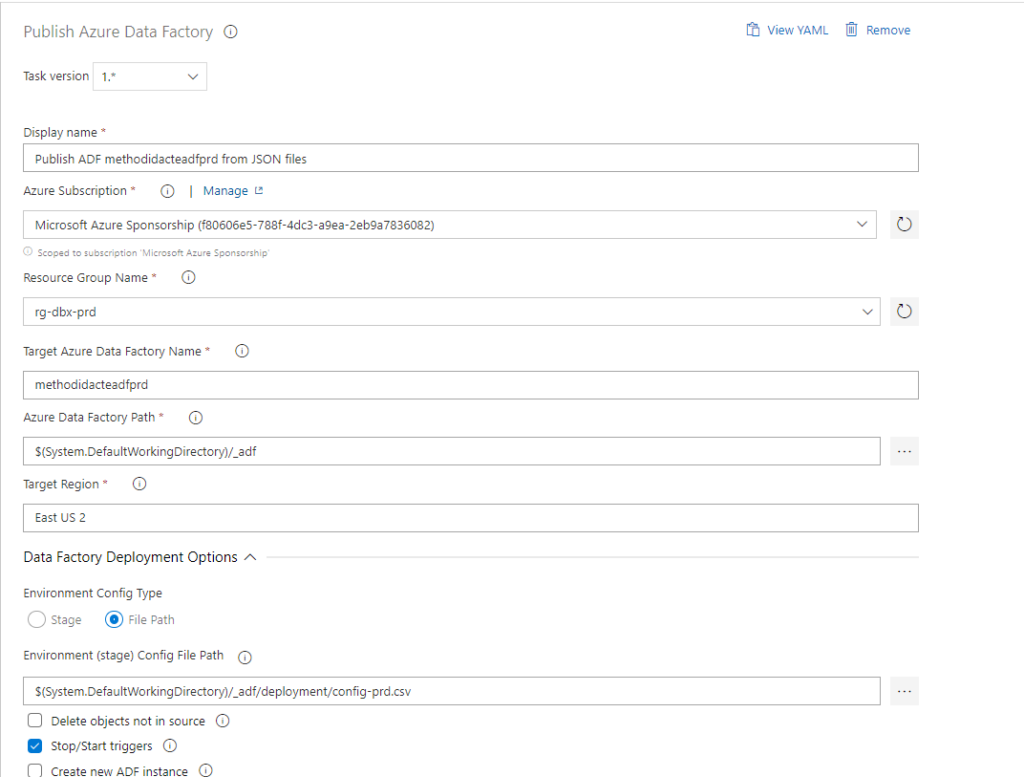
Dans la boîte de dialogue ci-dessous, les champs attendus concernent l’environnement cible :
nom du groupe de ressource
nom de la ressource Azure Data Factory
chemin vers le répertoire des fichiers JSON (branche adf_publish)
nom de la région où est située la ressource
Le fichier de configuration sera précisé plus tard.
Pour indiquer le path du dossier contenant les fichiers du template ARM, nous utilisons une nouvelle boîte de dialogue, en prenant soin de descendre un cran au-dessous du repository.
Veillez également à cocher la case “Stop/Start triggers”. En effet, le déploiement ARM ne pourra avoir lieu si des triggers sont actifs. C’est ici un avantage de cette extension : il n’est pas nécessaire d’ajouter par exemple un script PowerShell réalisant le stop puis le start. Une limite de l’approche par PowerShell consiste dans le fait que l’intégralité des triggers sont redémarrés. Il serait donc nécessaire de supprimer les triggers qui ne sont pas utilisés, plutôt que de les mettre en pause.
A ce stade, une première release pourrait être lancée et elle déploiera à l’identique l’environnement de développement.
Modifier les paramètres propres à l’environnement
Nous avons évoqué ci-dessus les fichiers JSON de la branche adf_publish. Ceux-ci permettent de réaliser un déploiement de template ARM (Azure Resource Manager), qui correspond à une approche dite Infra as Code, propre à l’univers Azure de Microsoft.
Pour déployer les développements vers un autre environnement, nous devons remplacer certaines valeurs :
nom de la ressource Data Factory
chaines de connexion
identifiant et mot de passe
URL
certains paramétrages spécifiques (ex.: type et dimension d’un cluster Databricks)
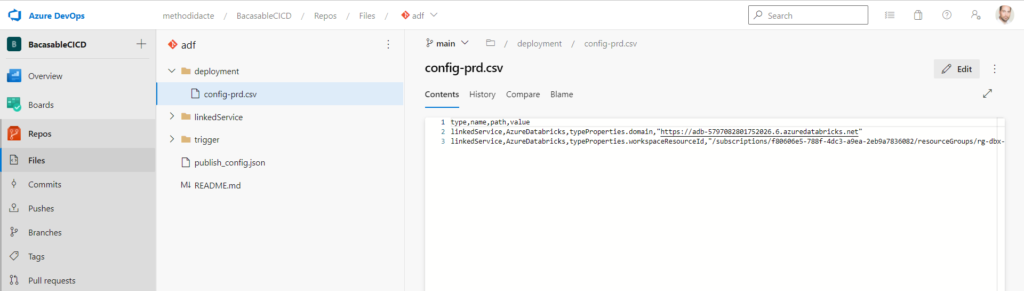
Nous allons ici préciser toutes les modifications à apporter au moyen d’un fichier CSV qui sera stocké sur la branche main du repository, dans un répertoire deployment et nommé config-{stage}.csv où la valeur de stage indique l’environnement cible.
Voici un exemple de fichier CSV qui transforme les informations nécessaires pour changer de workspace Azure Databricks. Les noms de colonnes en première ligne doivent être respectés.
Une documentation complète, sur la page de l’extension, explique comment renseigner ce fichier. Nous serons particulièrement vigilants quant à la gestion des secrets (tokens, mots de passe, etc.). Une astuce pourra être d’utiliser des variables d’environnement dans ce fichier, elles-mêmes sécurisées par Azure DevOps. Une meilleure pratique consistera à utiliser un coffre-fort de secrets Azure Key Vault, lui-même déclaré comme un service lié.
EDIT : en cas d’utilisation d’un firewall sur la ressource Azure Key Vault, il sera nécessaire d’ajouter l’IP de l’agent DevOps à ce firewall. Or, cette adresse IP n’est pas fixe.
Nous pouvons maintenant lancer la release.
Nous vérifions enfin dans le Studio Data Factory que les éléments développés sont bien présents, en particulier les triggers. Ceux-ci sont alors dans l’état “démarré” ou “arrêté” de l’environnement de développement.
Cette approche pourrait être perturbante si tous les triggers de développement sont arrêtés (les faire tourner ne se justifie sans doute pas). Mais nous avons bénéficier d’une autre fonctionnalité pour améliorer notre déploiement.
Réaliser un déploiement sélectif
Une autre option de l’extension sera particulièrement intéressante : le déploiement sélectif. Une case de la boîte de dialogue permet de déclarer la liste des objets que l’on souhaite ou non déployer. La syntaxe est explicité sur la page GitHub de l’extension.
Par exemple, nous retirons le déploiement d’un autre service lié, qui ne sera pas utile en production.
Dans une architecture plus complète, intégrant un Data Lake, nous pouvons obtenir le schéma suivant. Chaque cluster Databricks disposera d’un secret scope, lié à un coffre-fort Azure Key Vault. Celui-ci contiendra la définition d’un principal de service (client ID et client secret) permettant de définir un point de montage vers la ressource Azure Data Lake gen2 de l’environnement.
Pour remplacer certains paramètres avancés des services liés, cet article pourra servir de ressource.
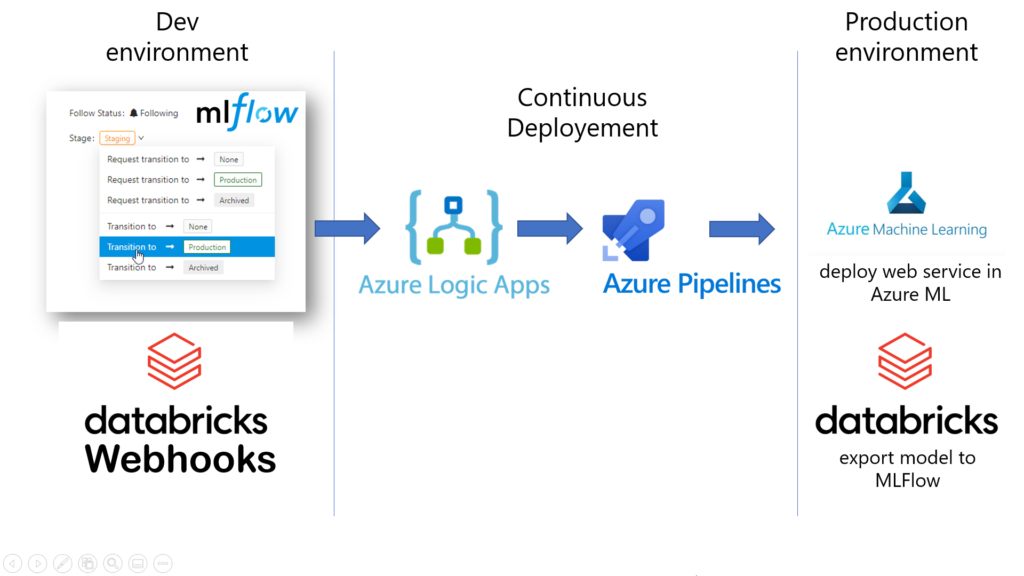
Une nouvelle fonctionnalité est disponible dans Databricks, en public preview, depuis février 2022 : les webhooks liés aux événements MLFlow. Il s’agit de lancer une action sur un autre service, déclenchable par API REST, lors d’un changement intervenant sur un modèle stocké dans MLFlow Registry (changement d’état, commentaire, etc.).
Cette fonctionnalité n’a rien d’anecdotique car elle vient mettre le liant nécessaire entre différents outils qui permettront de parfaire une approche MLOps. Mais avant d’évoquer un scénario concret d’utilisation, revenons sur un point de l’interface MLFlow Registry qui peut poser question. Nous disposons dans cette interface d’un moyen de faire évoluer le “stage” d’un modèle entre différentes valeurs :
None
Staging
Production
Archived
Ces valeurs résument le cycle de vie d’un modèle de Machine Learning. Mais “dans la vraie vie”, les étapes de staging et de production se réalisent sur des environnements distincts. Les pratiques DevOps de CI/CD viennent assurer le passage d’un environnement à un autre.
MLFlow étant intégré à un workspace Azure Databricks, ce service se retrouve lié à un environnement. Bien sûr, il existe quelques pistes pour travailler sur plusieurs environnements :
utiliser un workspace Azure Databricks uniquement dédié aux interactions avec MLFlow (en définissant les propriétés tracking_uri et registry_uri)
exporter des experiments MLFlow Tracking puis enregistrer les modèles sur un autre environnement comme décrit dans cet article
Aucune de ces deux approches n’est réellement satisfaisante car manquant d’automatisation. C’est justement sur cet aspect que les webhooks vont être d’une grande utilité.
Déclencher un pipeline de release
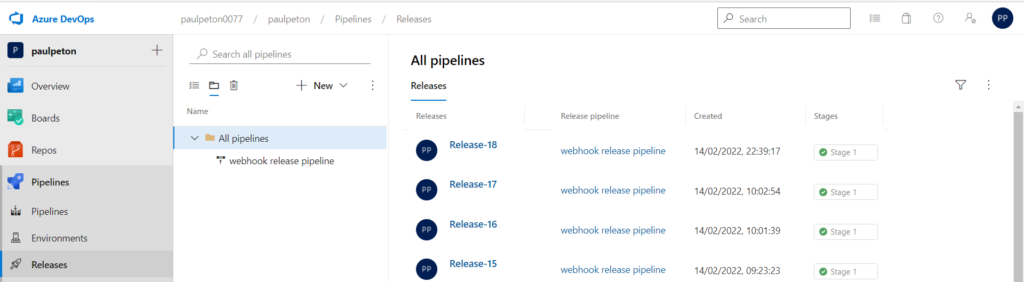
Dans Azure DevOps, l’opération correspondant au déploiement sur un autre environnement se nomme “release pipeline“.
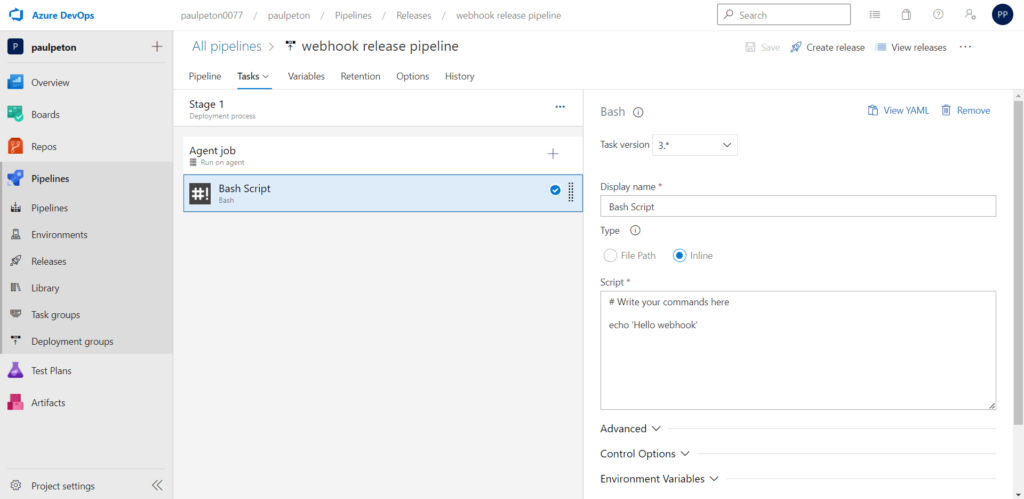
Pour simplifier la démonstration, nous définissions ici une pipeline contenant uniquement un tâche de type bash, réalisant un “hello world”.
Dans un cas d’utilisation plus réalise, nous pourrons par exemple déployer un service web prédictif contenant un modèle passé en production, grâce à une ressource comme Azure Machine Learning.
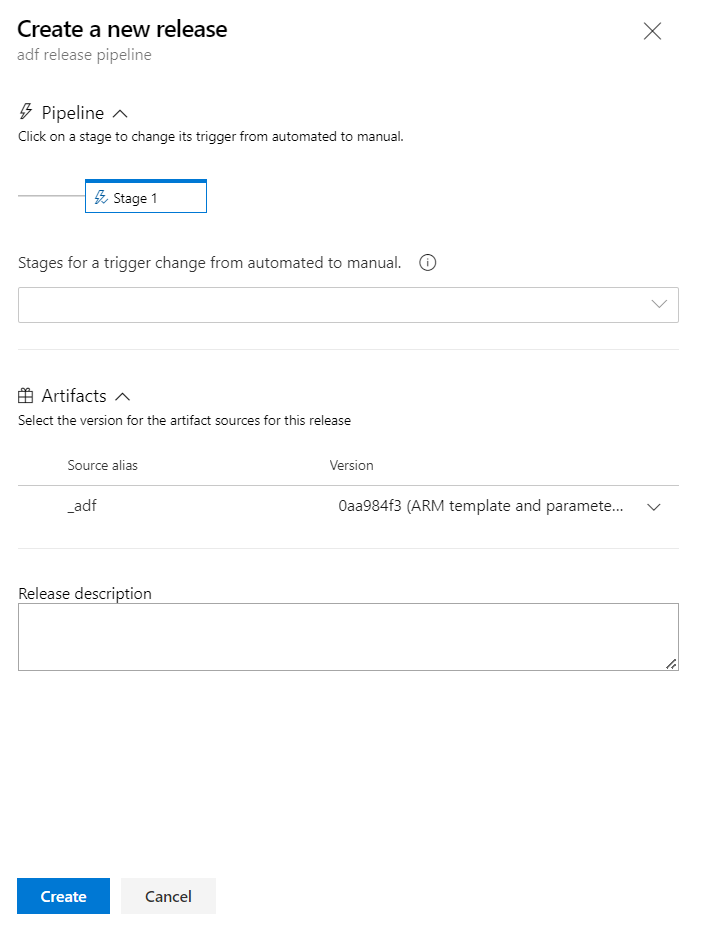
Nous vérifierons par la suite qu’une modification dans MLFlow Registry déclenche bien une nouvelle release de cette pipeline.
Précisons ici un point important : les webhooks Databricks attendent une URL dont l’appel sera fait par la méthode POST. Il existe une API REST d’Azure DevOps qui permettrait de piloter la release mais le paramétrage de celle-ci s’avère complexe et verbeux.
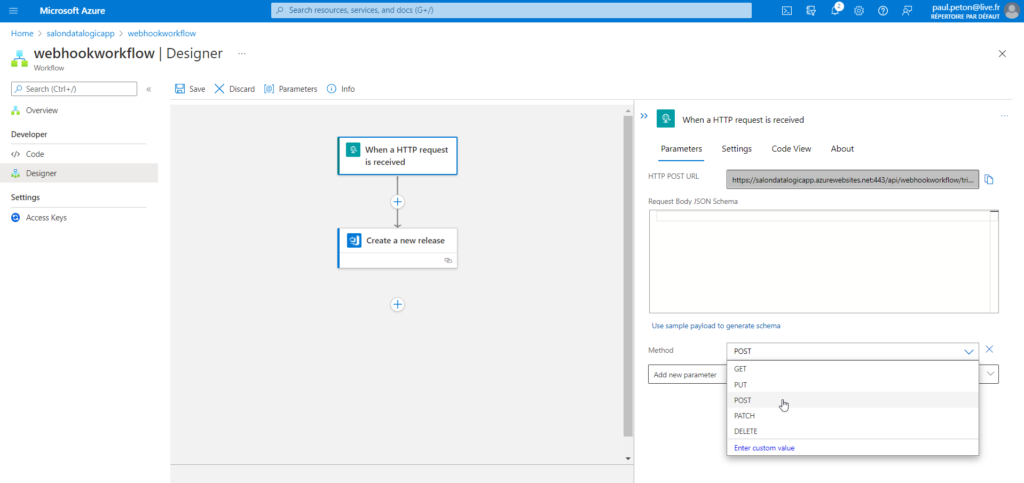
Nous passons donc un ordonnanceur intermédiaire : Azure Logic App. En effet, cette ressource Azure nous permettra d’imaginer des scénarios plus poussés et bénéficie également d’une très bonne intégration avec Azure DevOps. Nous définissons le workflow ci-dessous comprenant deux étapes :
When a HTTP request is received
Create a new release
Veillez à bien sélectionner la méthode POST.
Le workflow nous fournit alors une URL que nous utiliserons à l’intérieur du webhook. Il ne nous reste plus qu’à définir celui-ci dans Databricks. La documentation officielle des webhooks se trouve sur ce lien.
Il existe deux manières d’utiliser les webhooks : par l’API REST de Databricks ou bien par unpackage Python. Nous installons cette librairie databricks-registry-webhooks sur le cluster.
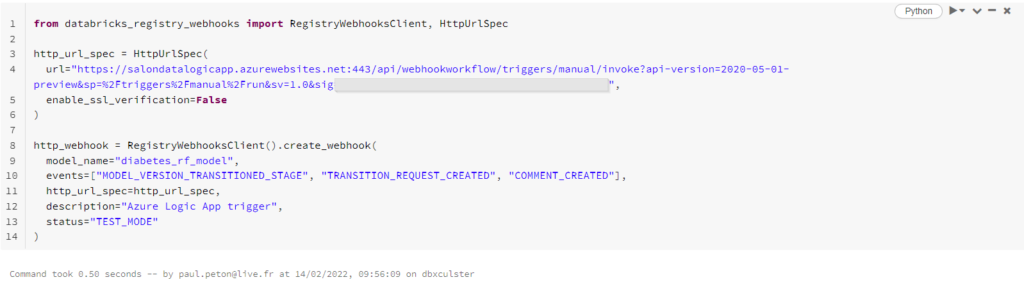
Depuis un nouveau notebook, nous pouvons créer le webhook, tout d’abord dans un statut “TEST_MODE”, en l’associant à un modèle déjà présent dans MLFlow Registry.
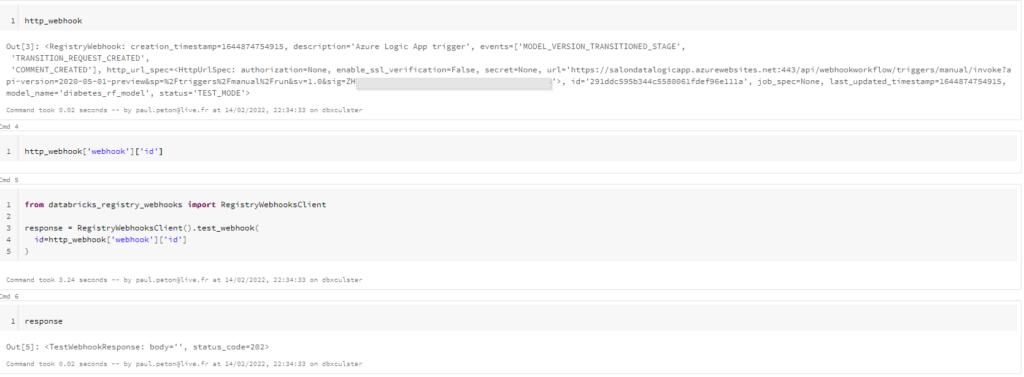
Ceci nous permet de tester un appel par la commande .test_webhook() qui attend en paramètre l’identifiant du webhook préalablement créé. Une réponse 202 nous indique que cette URL est acceptée (bannissez les réponses 305, 403, 404, etc.).
Le webhook peut se déclencher sur les événements suivants :
MODEL_VERSION_CREATED
MODEL_VERSION_TRANSITIONED_STAGE
TRANSITION_REQUEST_CREATED
COMMENT_CREATED
MODEL_VERSION_TAG_SET
REGISTERED_MODEL_CREATED
Le webhook peut ensuite être mis à jour au statut ACTIVE par la commande ci-dessous.
Il ne reste plus qu’à réaliser une des actions sélectionnées sur le modèle stocké dans MLFlow Registry et automatiquement, une nouvelle release Azure DevOps se déclenchera.
Maintenant, il n’y a plus qu’à laisser libre cours à vos scénarios les plus automatisés !
Ci-dessous, le schéma résumant les différentes interactions mises en œuvre.
Si vous travaillez à plusieurs sur Azure Databricks, vous vous êtes sûrement déjà confronté.e.s à des réflexions sur les droits à accorder à chacun.e, selon les profils : data analyst, data scientist, data engineer, ML engineer… Rappelons qu’une gestion fine des droits ne sera possible qu’en licence dite Premium.
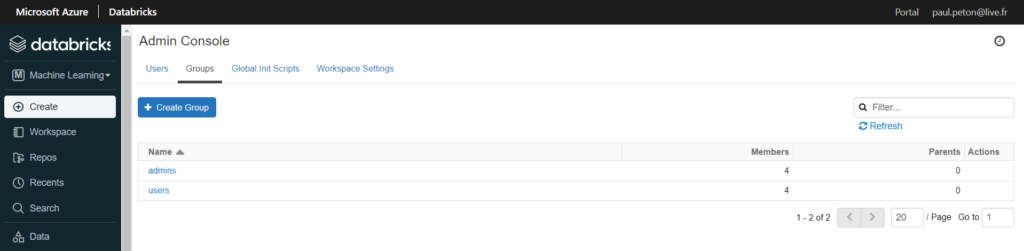
Il est évident qu’un administrateur de l’espace de travail ne souhaitera pas gérer des autorisations nominatives et ainsi, devoir reprendre la gestion à droits à chaque arrivée ou départ sur un projet ! Nous souhaitons donc nous référer à des groupes et c’est justement une notion bien intégrée dans l’annuaire Azure Active Directory (AAD).
Databricks dispose également d’une gestion de groupes d’utilisateurs dans sa console d’administration.
Malheureusement, il n’est pas possible d’utiliser un alias de groupe AAD dans Databricks et ces deux notions de groupes ne sont pas synchronisées entre elles !
Nous pourrions aussi imaginer un déploiement Terraform qui viendrait décortiquer un groupe AD et ajouter chaque utilisateur au moyen d’une boucle (voir ce post Medium) mais cette démarche semble vraiment trop lourde à mettre en œuvre et à maintenir…
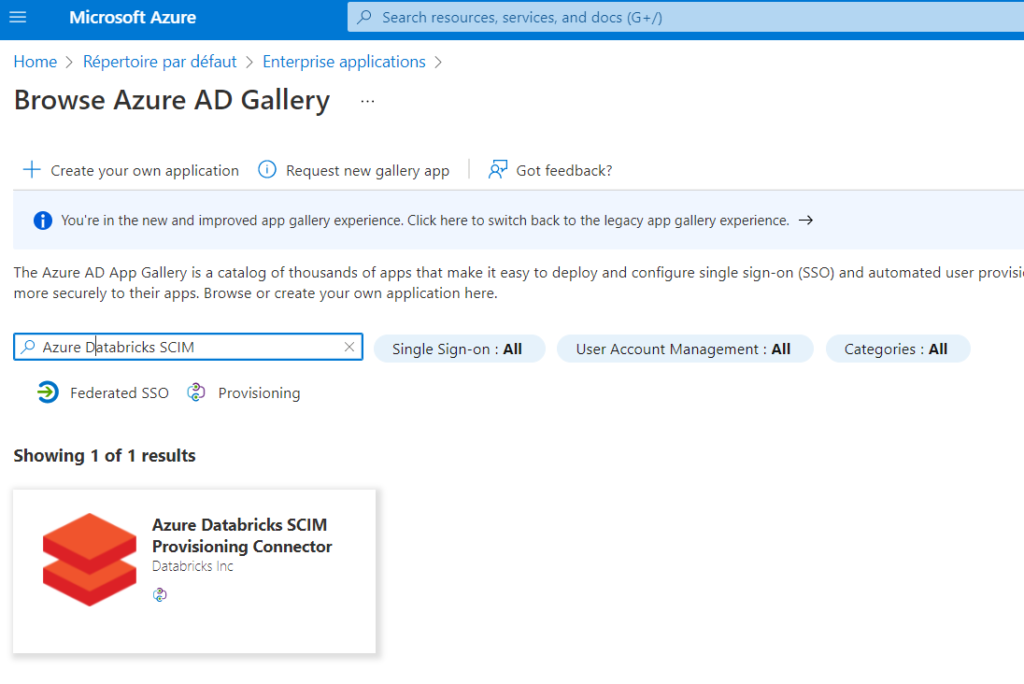
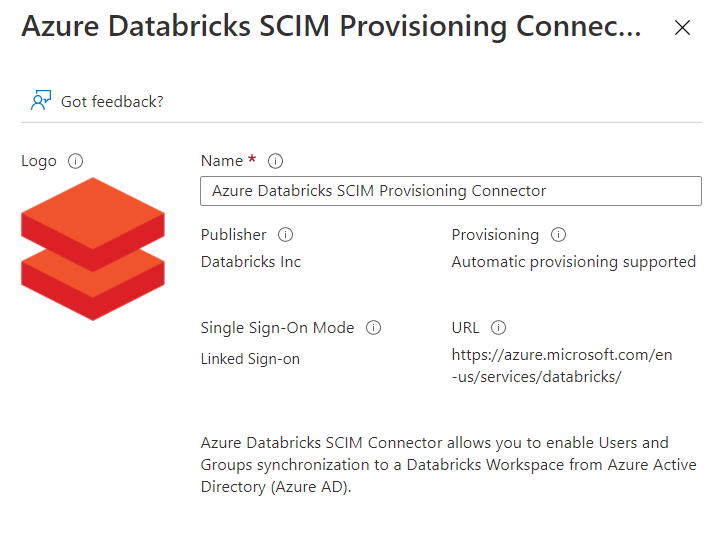
Un outil vient à notre secours : Azure Databricks SCIM Provisioning Connector et c’est mon collègue Hamza BACHAR qui me l’a soufflé.
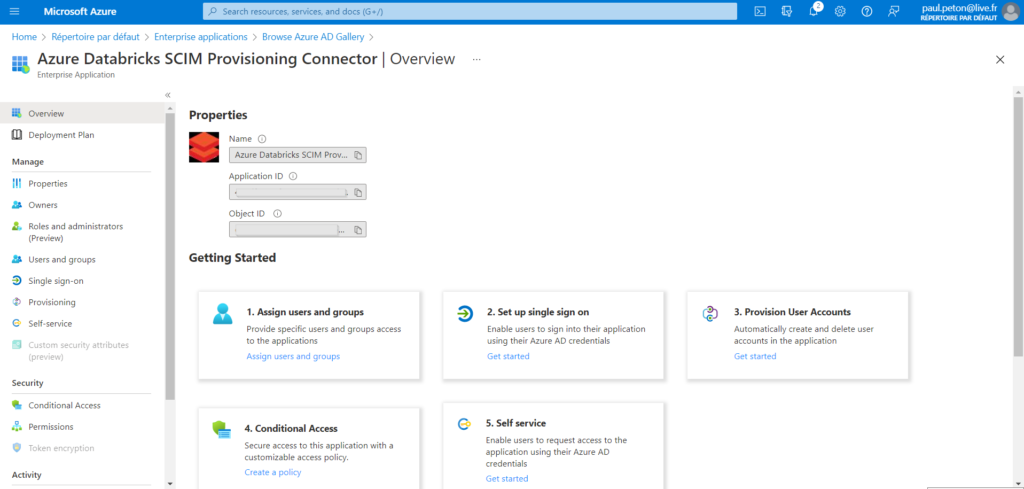
Nous commençons par enregistrer cet outil en tant qu’enterprise application dans Azure AD.
Il s’agit d’un produit développé par la société Databricks Inc, ce qui est plutôt rassurant.
Il est recommandé de renommer l’application en intégrant le nom de la ressource Databricks car il faudra autant d’enregistrements d’applications que de workspaces.
L’application est maintenant enregistrée dans notre abonnement Azure et dispose de deux identifiants : application ID et object ID.
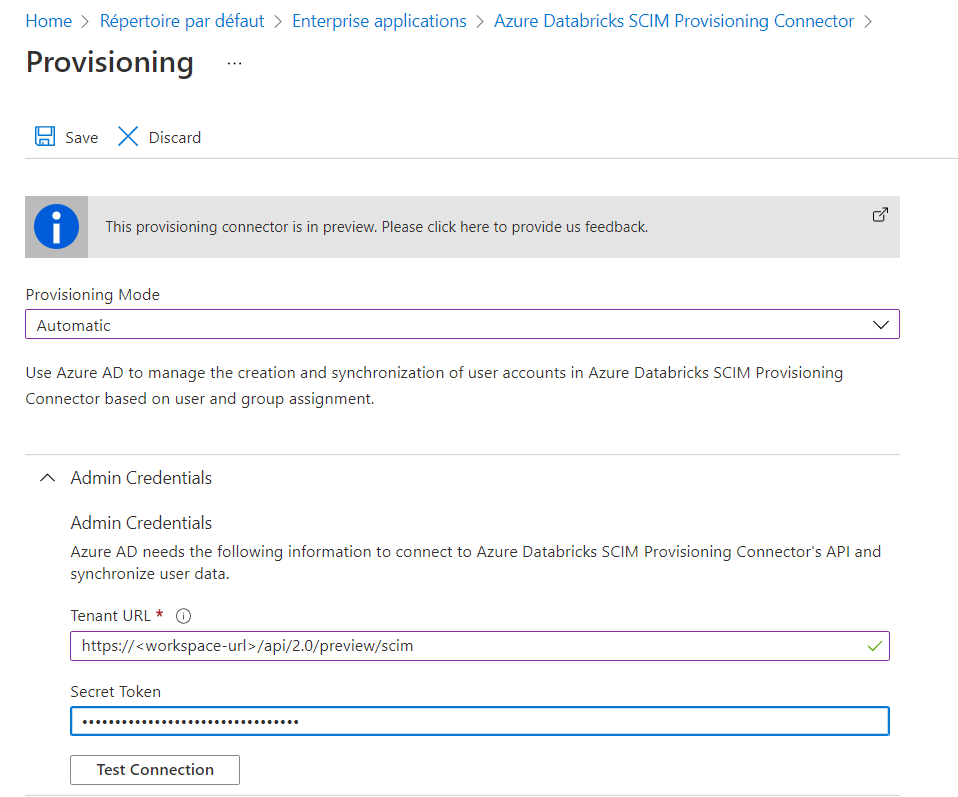
Nous cliquons maintenant sur le menu Provisioning qui va nous permettre d’associer l’application avec un workspace Databricks. Le mode de provisioning doit être basculé sur Automatic.
Nous devons fournir ici deux informations :
l’URL du workspace à laquelle sera ajoutée le point de terminaison de l’API SCIM
un Personal Access Token qui aura été généré depuis les user settings de Databricks
Nous testons la connexion puis clic sur “Save” pour conserver le paramétrage.
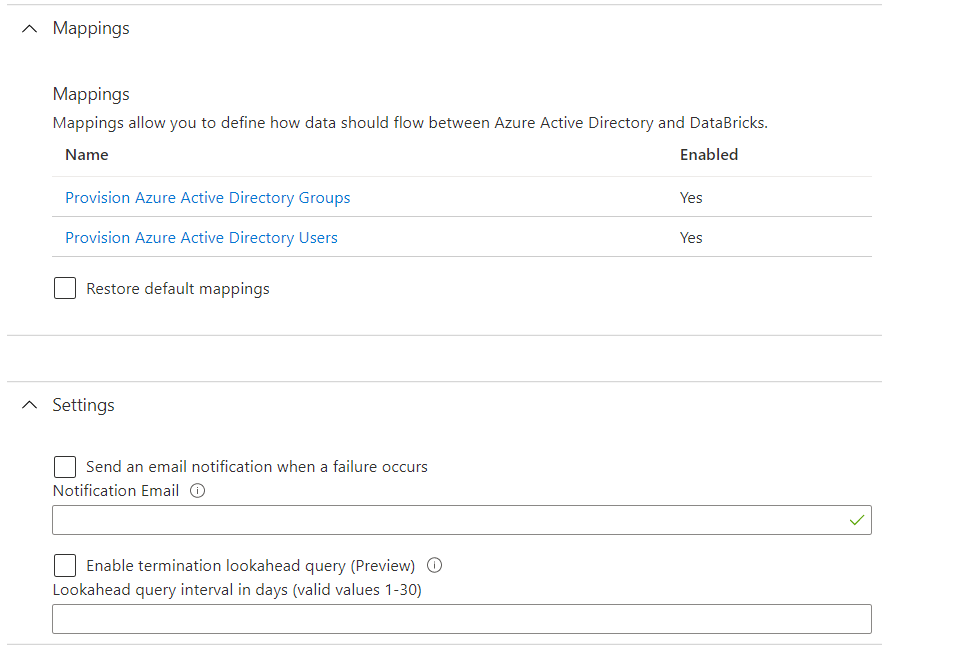
Nous laissons par défaut les autres options disponibles.
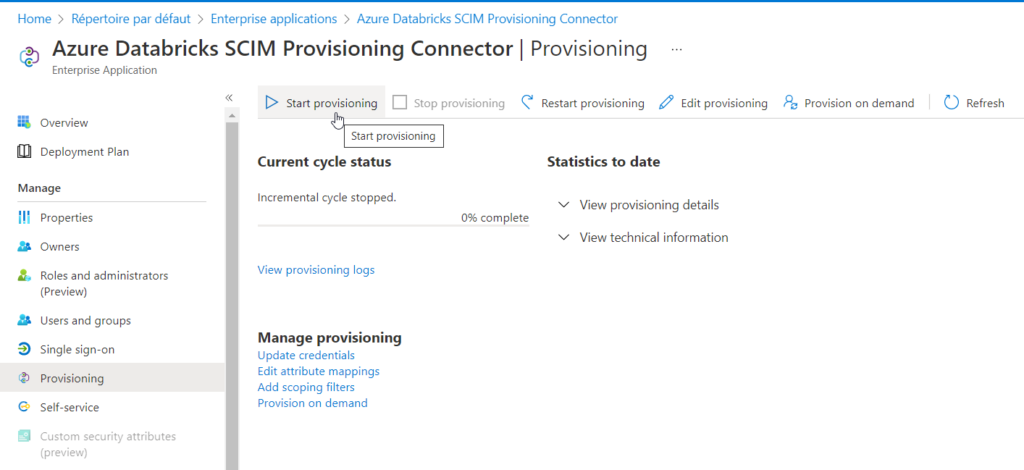
Le provisioning peut maintenant être démarré.
Il ne reste plus qu’à positionner des users ou groups directement dans cette application pour qu’ils soient automatiquement synchronisés avec la console d’administration Databricks ! Il est toutefois nécessaire d’attendre quelques minutes (cela peut aller jusqu’à 40 minutes). On privilégiera les “groupes de sécurité” plutôt que de type “M365” et les “nested groups” ne sont pas aujourd’hui supportés.
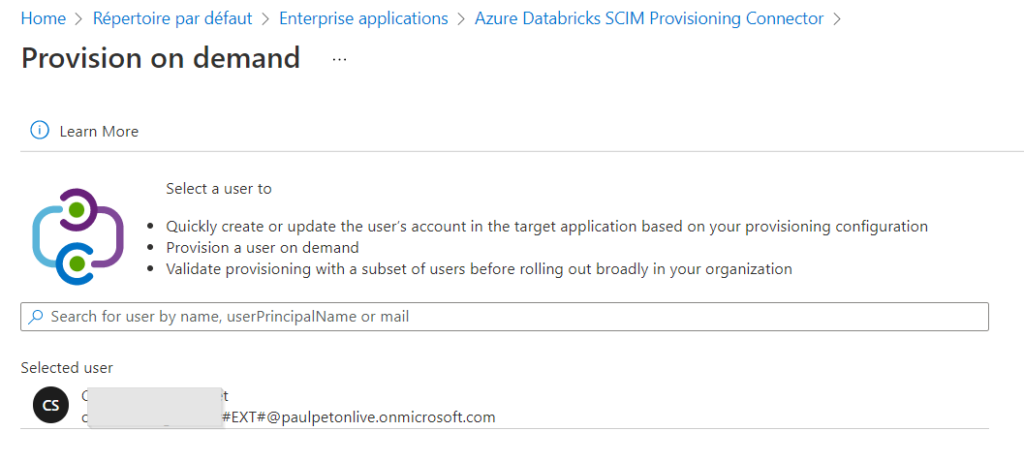
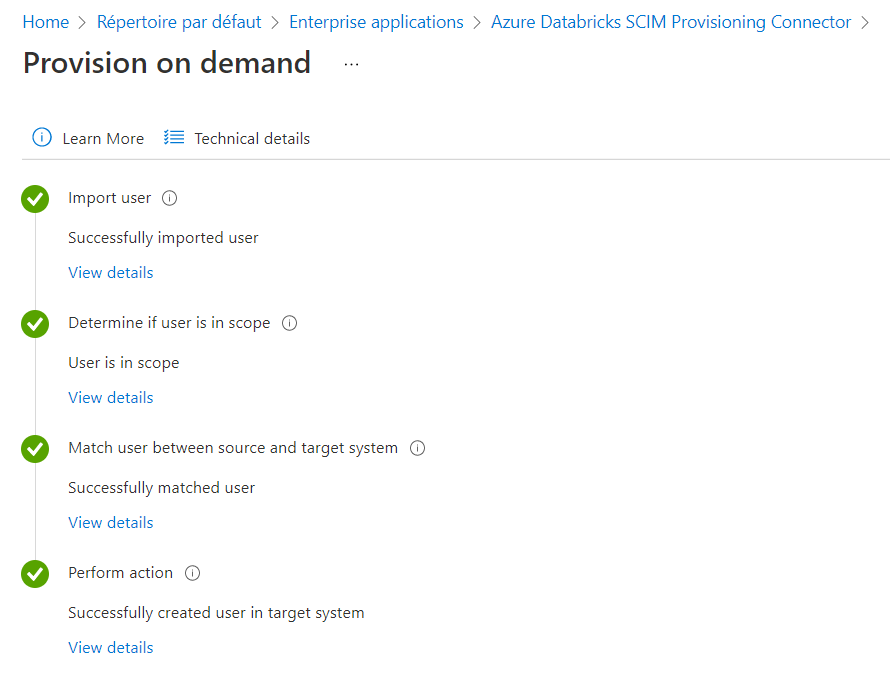
Il est aussi possible de “provisionner à la demande” un utilisateur.
Un écran vient ensuite confirmer que l’action a bien été réalisée et l’utilisateur est directement ajouté au workspace.
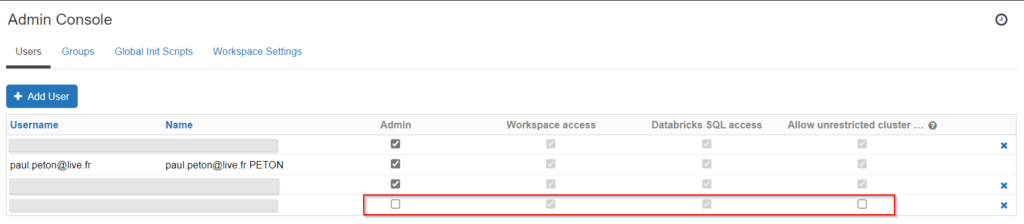
A noter que le nouvel utilisateur est restreint sur ses droits, par défaut.
Il n’est pas administrateur du workspace et se trouve restreint sur la création de nouveaux clusters.
EDIT
Il est nécessaire qu’une personne ayant le droit d’enregistrement d’applications réalise la première manipulation. Mais ensuite, d’autres personnes pourront avoir besoin d’utiliser cette interface.
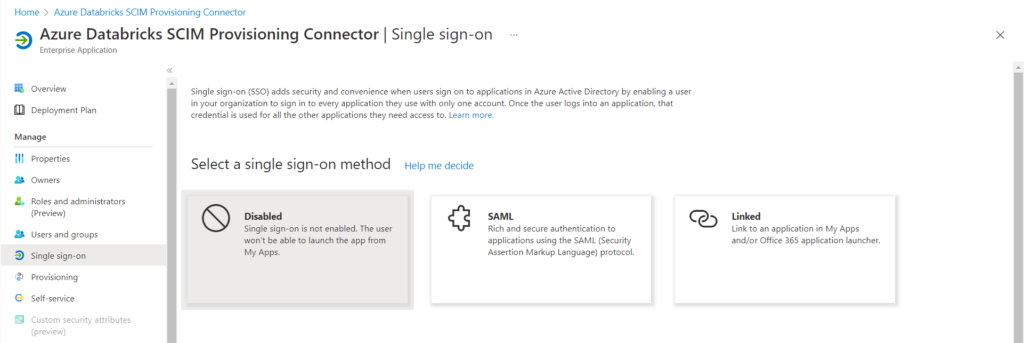
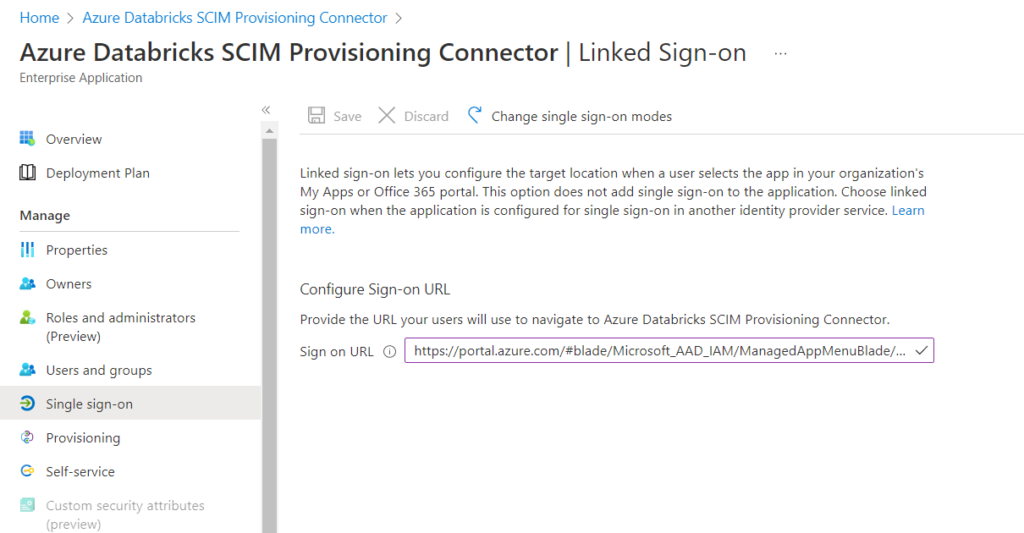
Nous allons donc autoriser d’autres utilisateurs au “self-service” de cette application. Il faut tout d’abord activer le “single sign-on”, en mode “linked”.
Fournir pour cela l’URL de connexion.
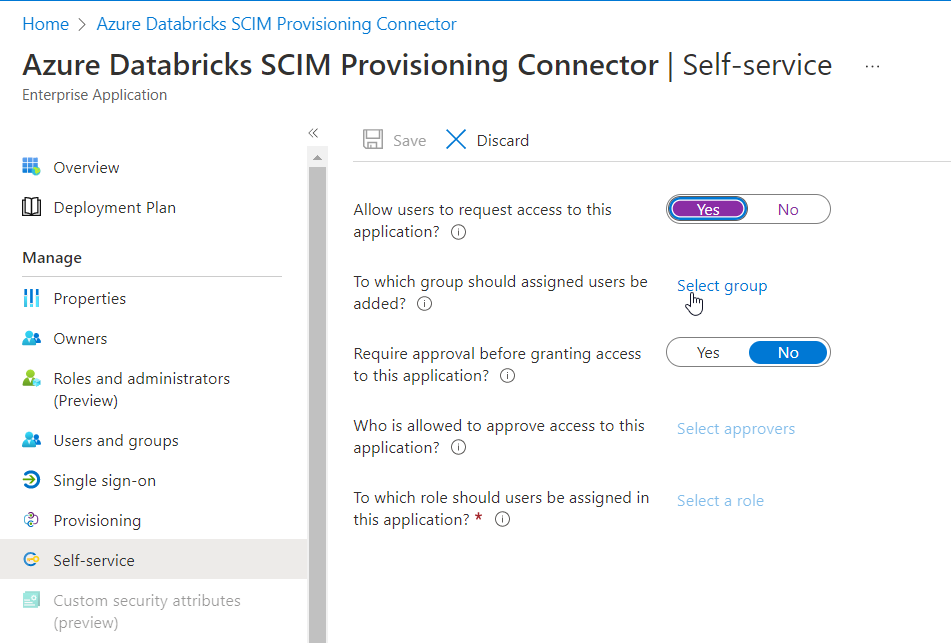
On paramètre enfin le menu Self-service.
Si l’on souhaite plutôt ajouter des users ou des groups de manière programmatique, on pourra se pencher sur ce code PowerShell.
Ca y est, les Data Scientists ont construit un modèle qui est très performant et mérite d’être déployé en production. Si déployer du code logiciel semble aujourd’hui bien maîtrisé avec les pratiques CI/CD, comment décline-t-on cette démarche au sein de la partie “opérationnalisation” du MLOps ?
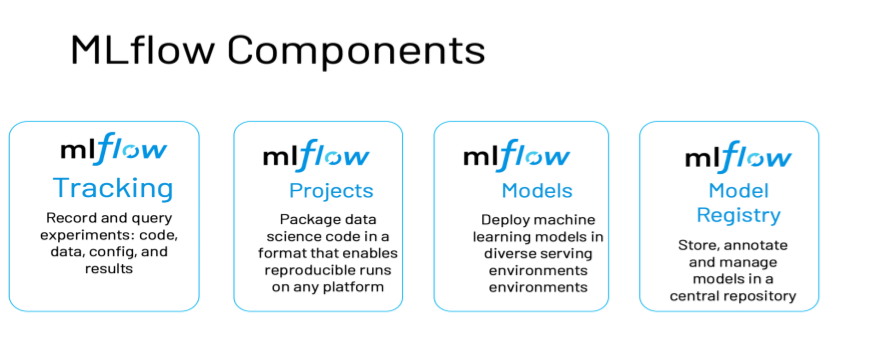
Des outils sont là pour nous aider, en particulier le produit Open Source MLFlow. Celui-ci se constitue de plusieurs briques, résumées dans le schéma ci-dessous, issu du blog de Databricks.
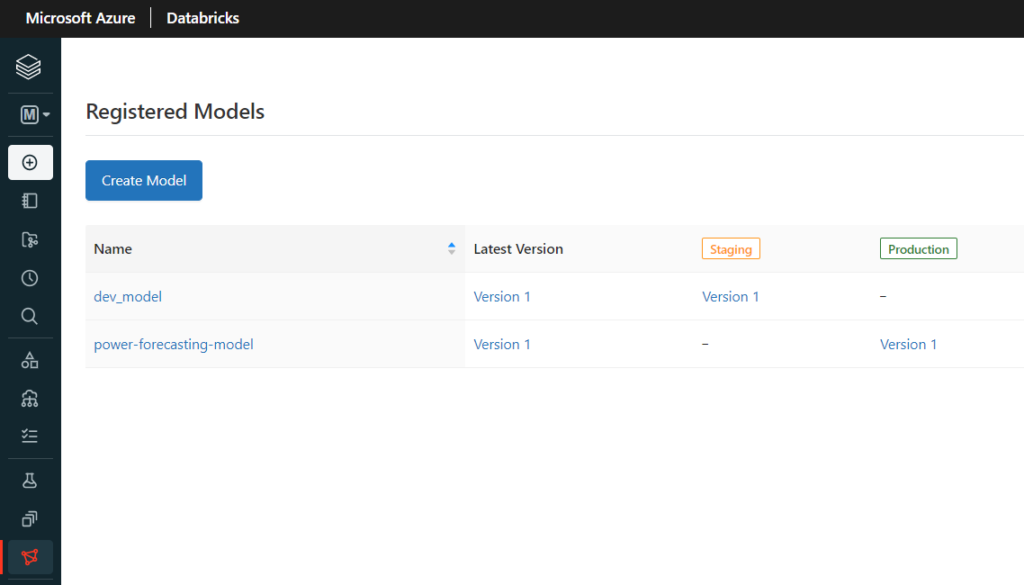
MLFlow Registry permet en particulier de préciser un “stage” pour chaque modèle et ainsi, de passer un modèle de l’étape Staging à l’étape Production.
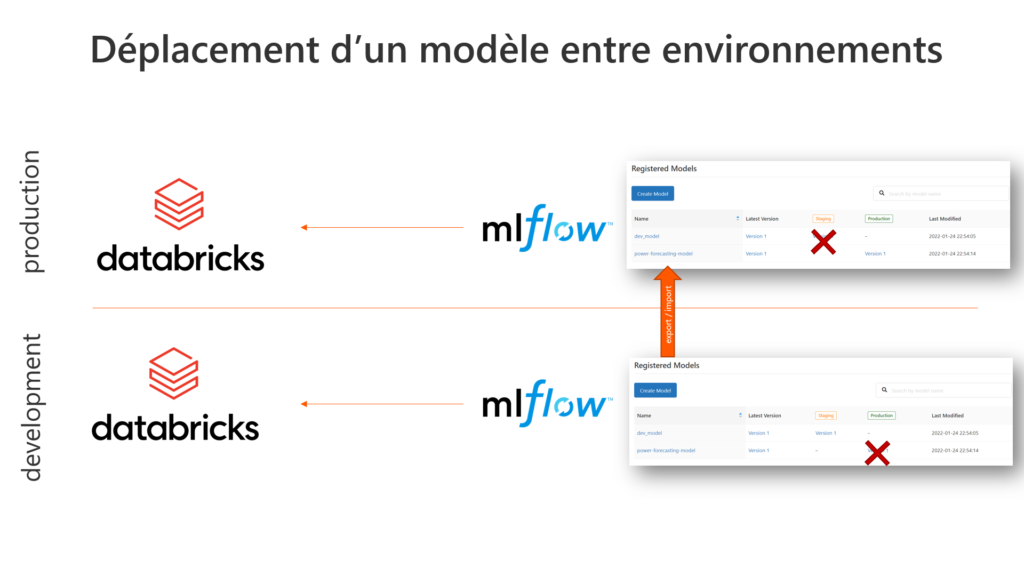
Mais la position de ce registry de modèles est liée à la ressource Azure Databricks où sont entrainés les modèles ! Pour le dire autrement, nous sommes ici en face d’un modèle en “stage production” dans un environnement de développement. Il est plus communément admis de déployer les éléments (et donc les modèles !) d’un environnement vers un autre.
L’état Staging ou Production doivent être propres à un environnement
Nous travaillerons ici pour la démonstration avec deux espaces de travail (workspaces) Databricks symbolisant les environnements de développement (DEV) et de production (PROD).
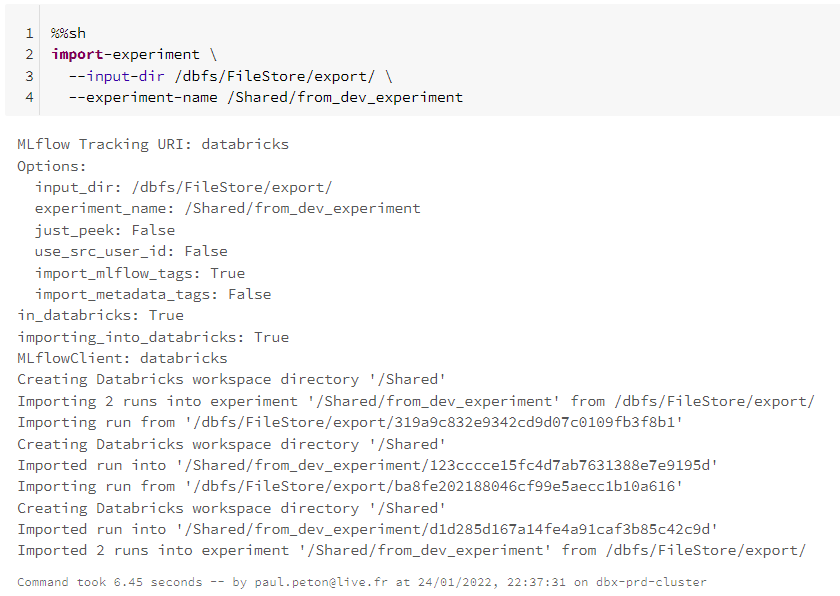
Il est possible d’enregistrer un modèle sur un workspace distant, en définissant la connexion au travers d’un secret scope. Je vous recommande pour cela l’excellent blog de Nastasia SABY. Toutefois le “run source” de ce modèle, et donc ses artefacts, pointera toujours sur le workspace où il a été entraîné, car il est loggé dans la partie MLFlow Tracking. Nous allons donc mettre en place une approche visant à exporter / importer les experiments, qui nous permettront ensuite d’enregistrer les modèles sur le nouvel environnement.
Créer une experiment et enregistrer un modèle
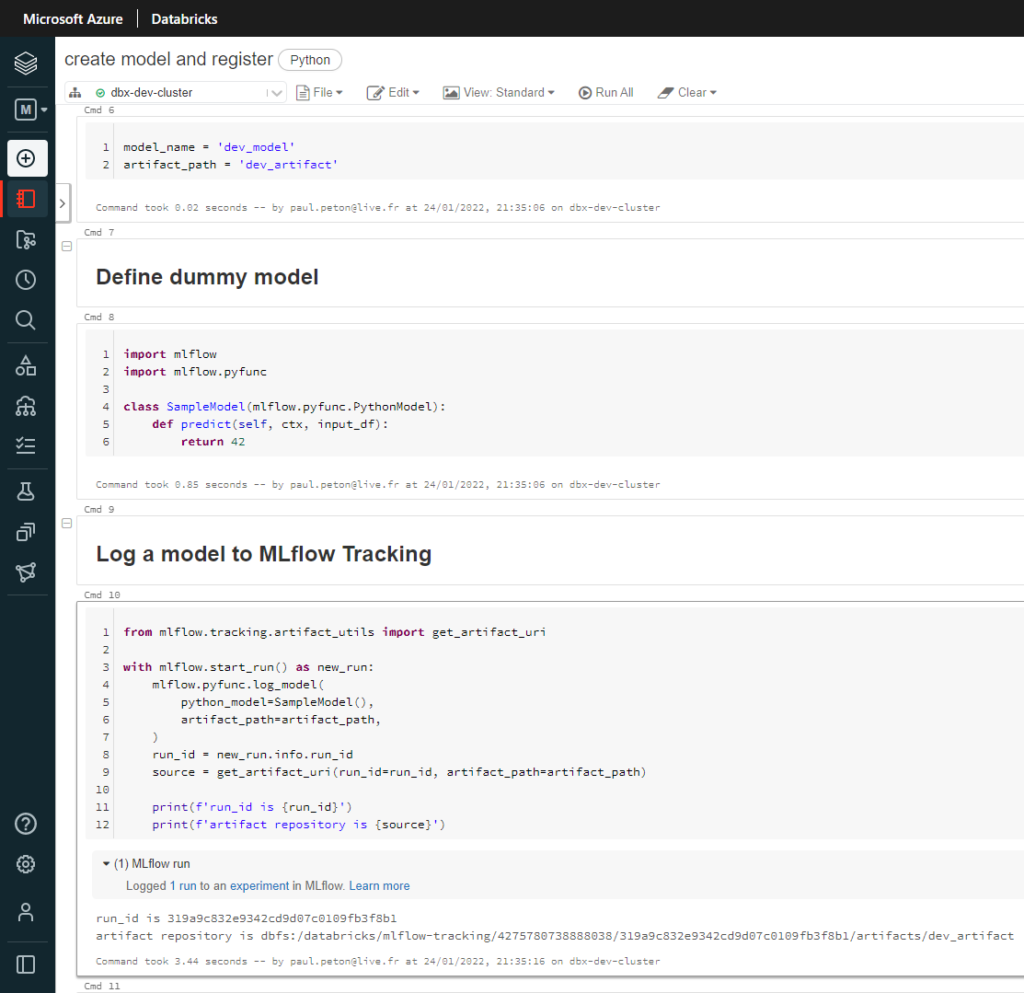
Dans l’environnement DEV, nous lançons l’entrainement d’un modèle simpliste : “dummy model“, il renvoie toujours la valeur 42.
Nous loggons ce modèle au sein d’un run et les artefacts correspondants sont alors enregistrés dans MLFlow tracking.
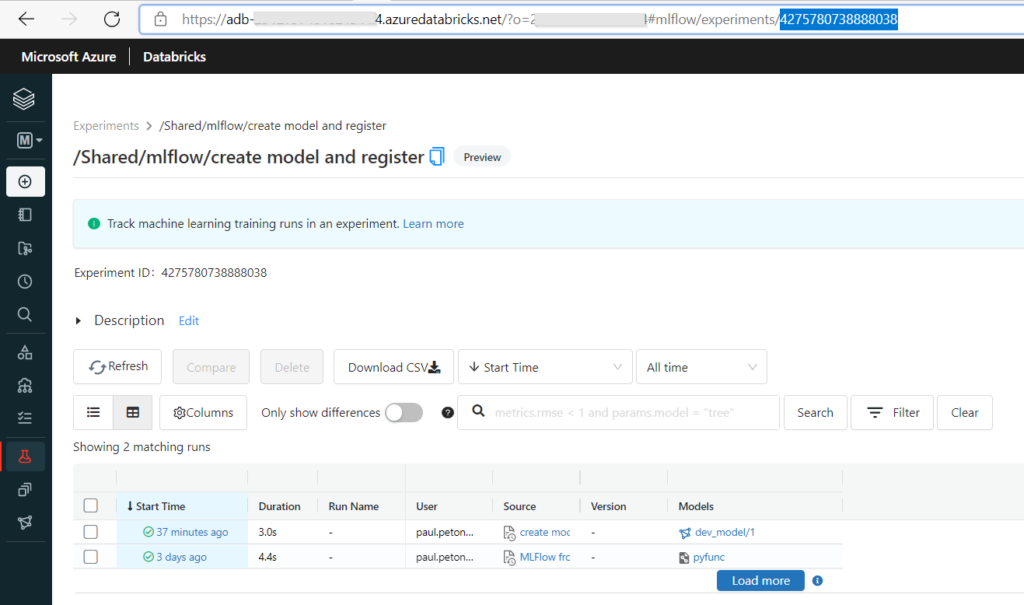
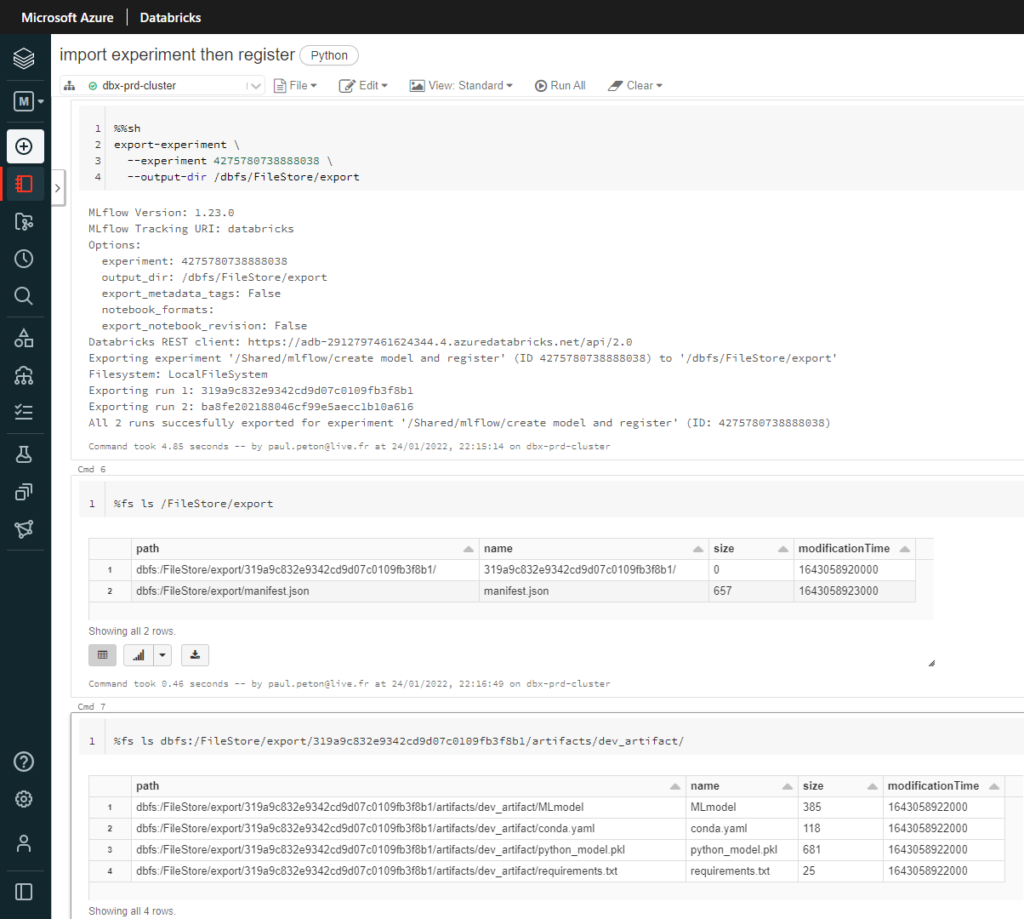
Notons ici la valeur de l’experiment ID, qui figure également dans l’URL de la page, nous en aurons besoin pour appeler à distance cette experiment.
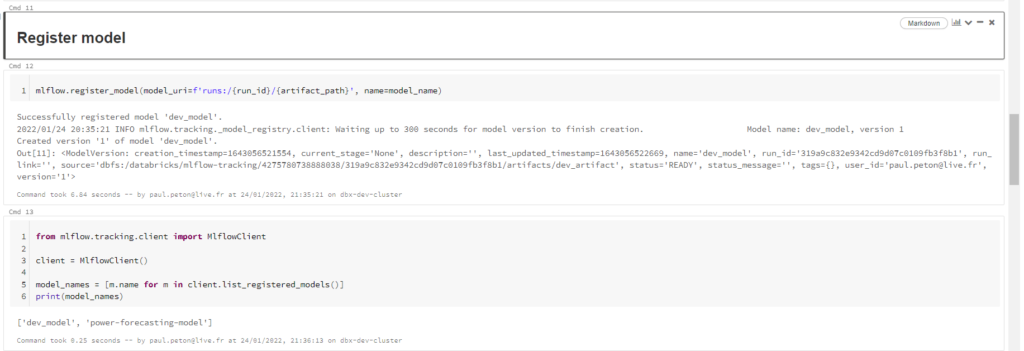
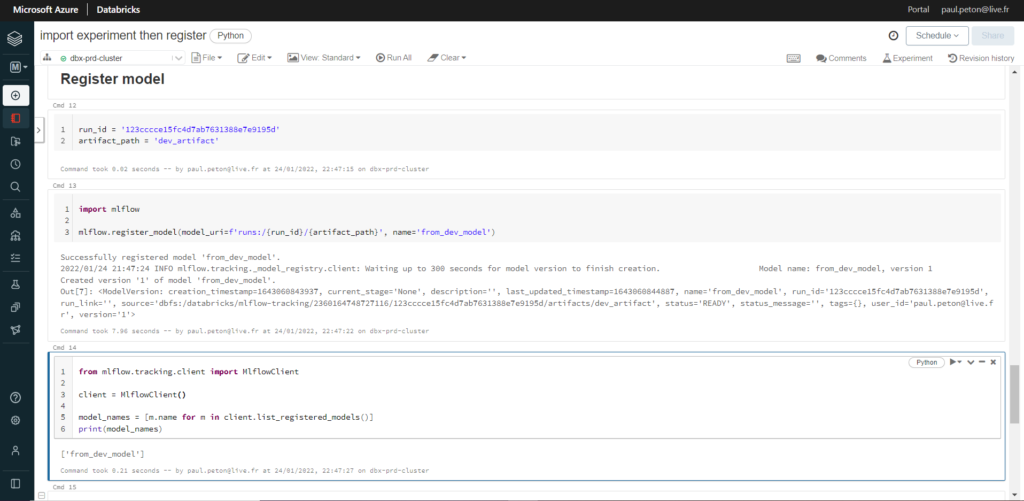
Lançons ensuite, par le code, l’enregistrement du modèle dans MLFlow Registry.
Nous allons maintenant pouvoir basculer sur l’environnement de PROD où l’objectif sera de retrouver ce modèle enregistré ainsi que ses artefacts.
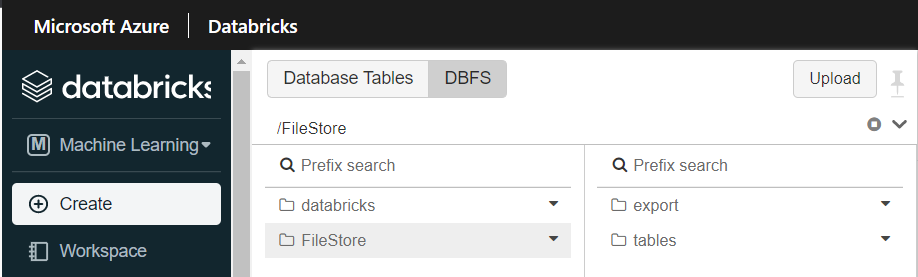
Les logs de la cellule nous indiquent un export réalisé avec succès et nous pouvons le vérifier en naviguant dans les fichiers du répertoire de destination.
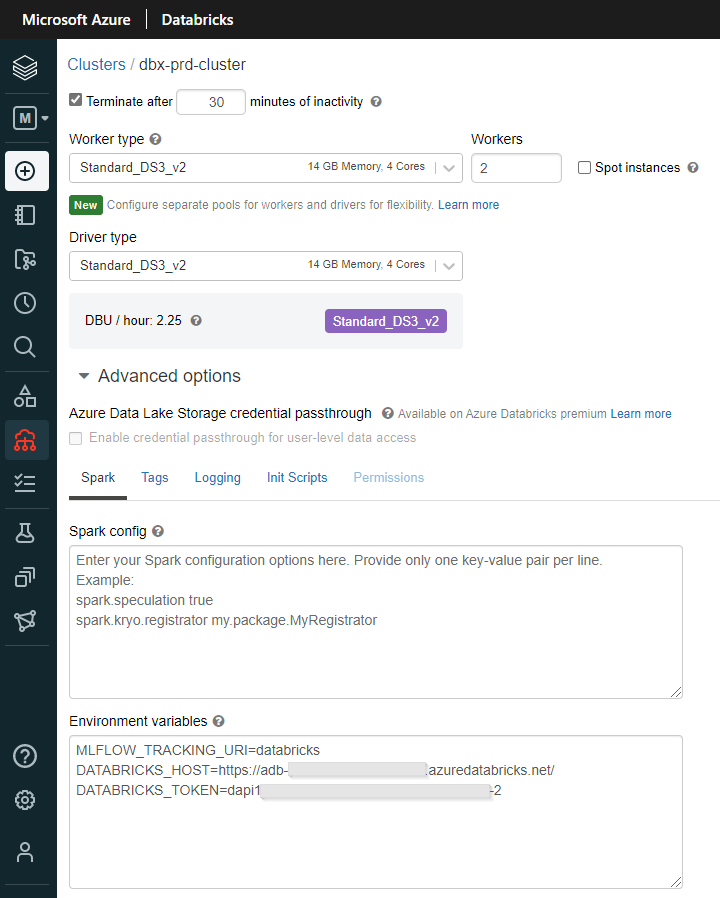
Avant de passer à la commande d’import, nous devons modifier les valeurs des variables d’environnement du clusterpour pointer cette fois-ci sur le workspace de PROD, et ceci même si nous lançons les commandes depuis celui-ci. Un nouveau redémarrage du cluster sera nécessaire. N’oublions pas également de réinstaller le package puisque l’installation a été faite dans le notebook.
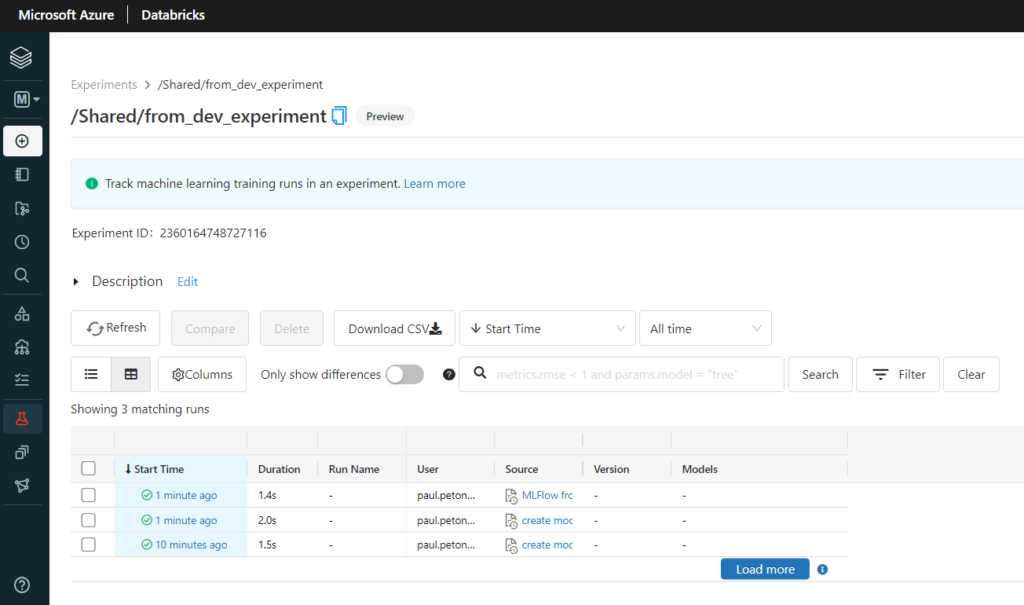
Vérifions maintenant que l’experiment s’affiche bien dans la partie MLFlow Tracking du workspace de PROD.
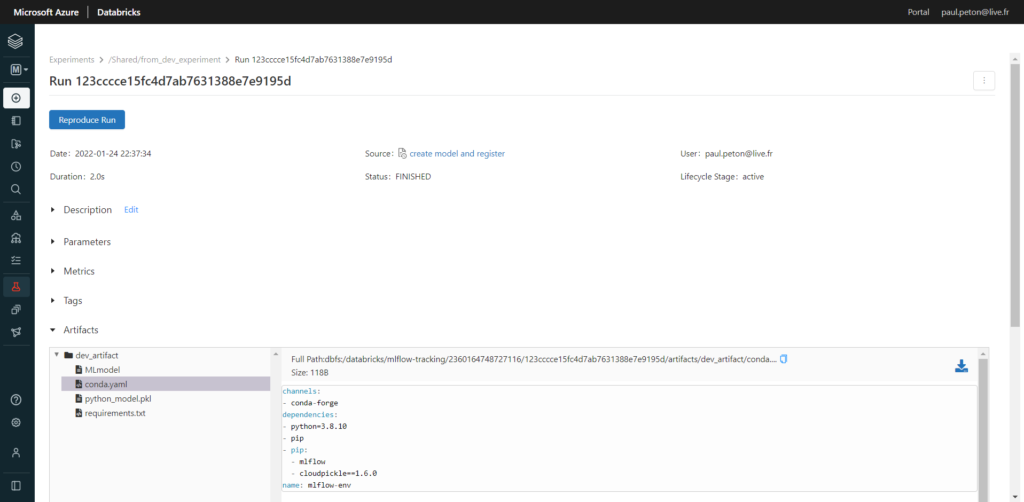
Les artefacts sont bien visibles dans MLFlow Tracking du workspace de PROD.
Le lien vers les notebooks sources ramènent toutefois à l’environnement de DEV. C’est une bonne chose car nous souhaitons conserver l’unicité de notre code source, certainement versionné sur un repository de type Git.
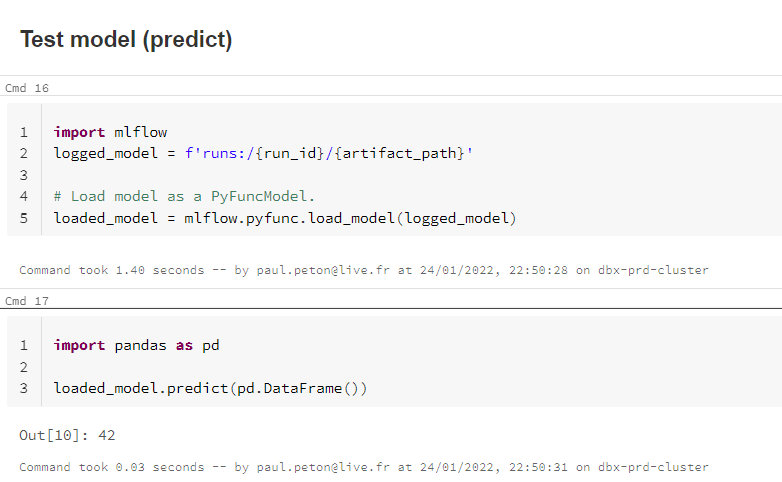
Utilisons à nouveau des commandes du package mlflow pour enregistrer le modèle. Nous aurons pour cela besoin du run_id visible dans MLFlow Tracking.
Finissions en testant le modèle chargé depuis l’environnement de PROD.
C’est gagné ! Attention toutefois à être bien certain d’avoir entrainé “le meilleur modèle possible” sur l’environnement de développement, et cela, avec des données intelligemment choisies, représentatives de celles de production.
Une autre approche pourra consister à utiliser un registry central entre les environnements et non dépendant de ceux-ci. Ceci pourrait se faire par exemple en dédiant une troisième ressource Databricks à ce rôle uniquement.