En quelques années de l’ère “big data”, le format de fichier orienté colonne Parquet s’est imposé comme l’un des standards du stockage sur les lacs de données (data lake) grâce à ses performances de compression, sa gestion des partitions et son intégration avec des frameworks distribués comme Spark. Il s’agit d’un projet porté par la fondation Apache qui héberge la documentation officielle.
Avant d’obtenir un fichier Parquet, le format initial est bien souvent un format texte classique structuré comme du CSV ou semi-structuré comme le JSON. Nous sommes également dans le scénario de réalisation d’un couche “clean” au sein d’un data lake, à partir de nombreux fichiers de la couche “raw“, nécessitant d’être agrégés et optimisés pour des outils d’analyse.
Dans cet article, nous allons dérouler un cas pratique allant de la constitution de ces fichiers Parquet jusqu’à leur utilisation dans un rapport Power BI.
Partons d’une année de fichiers zip issus de vélos en location de la ville de New York, soit un total de 828Mo, atteignant 3,45Go une fois décompressés (CSV).
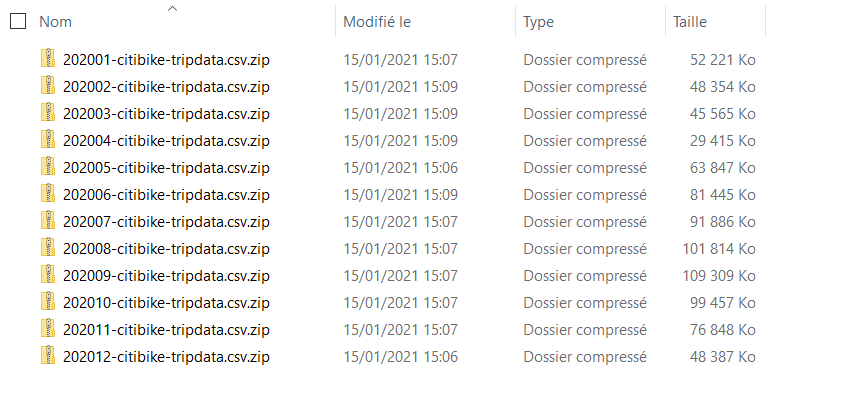
Nous disposons ainsi en tout de 19 506 857 lignes pour l’année 2020.
Avec un peu de script Python, nous pouvons décompresser automatiquement ces fichiers.
import os
import zipfile
def unzip_files(path_to_zip_file) -> None:
directory_to_extract_to = "datasets"
with zipfile.ZipFile(path_to_zip_file, 'r') as zip_ref:
zip_ref.extractall(directory_to_extract_to)
for file in os.listdir("zip"):
print(f"Unzipping : {file}")
unzip_files("zip/"+file)
Ensuite, depuis un environnement Spark comme Azure Databricks, nous pouvons lire tous les CSV, qui auront été déposés au préalable sur un compte de stockage Azure.
file_location = "/mnt/nycitibike/datasets/*"
file_type = "csv"
df = spark.read.format(file_type).option("inferSchema", "true").option("header","true").load(file_location)
display(df)
Notez qu’il faudra renommer les colonnes comportant un ou plusieurs espaces, interdits en entêtes dans le format Parquet, ce que nous faisons avec le script ci-dessous.
df = df \
.withColumnRenamed("start station id","start_station_id") \
.withColumnRenamed("start station name","start_station_name") \
.withColumnRenamed("start station latitude","start_station_latitude") \
.withColumnRenamed("start station longitude","start_station_longitude") \
.withColumnRenamed("end station id","end_station_id") \
.withColumnRenamed("end station name","end_station_name") \
.withColumnRenamed("end station latitude","end_station_latitude") \
.withColumnRenamed("end station longitude","end_station_longitude") \
.withColumnRenamed("birth year","birth_year")
L’enregistrement au format Parquet est alors possible, toujours à l’aide de l’API PySpark.
df.write.format("parquet").mode("overwrite").save("/mnt/nycitibike/dbx_parquet")
Les données sont automatiquement partitionnées (il est possible d’avoir la main sur ce mécanisme, comme nous le verrons plus tard) et quelques fichiers spécifiques à Databricks sont ajoutés :
– ficher “commited” qui liste les différentes parties
– fichier vide “started”
– fichier vide _SUCCESS
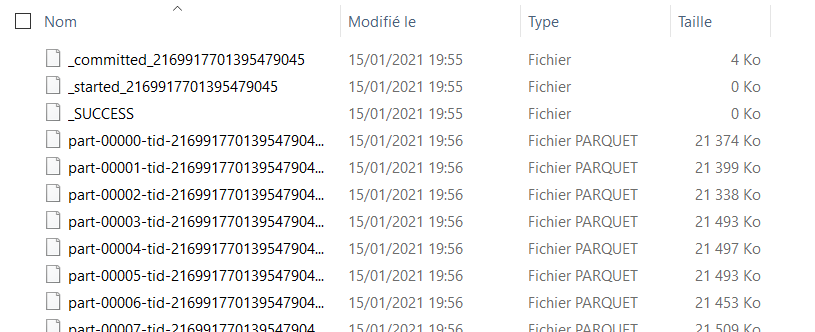
Ces fichiers qui tracent la transaction réalisées vont nous gêner pour une usage dans Power BI. Nous pourrions éviter leur génération en définissant les options suivantes dans notre script Spark comme l’indiquent ces échanges sur le forum Databricks.
Il est possible de prendre la main sur le nombre de fichiers obtenus, ainsi que sur la clé qui aidera au partitionnement. Nous ajoutons deux fonctions que sont repartition() et partitionBy() dans la syntaxe d’écriture du Parquet.
df.repartition(1).write.partitionBy("YearMonth").format("parquet").mode('overwrite').save("/mnt/nycitibike/dbx_parquet")
Dans Power BI Desktop, nous disposons d’un type de source Parquet, à partir du menu “Obtenir les données”.
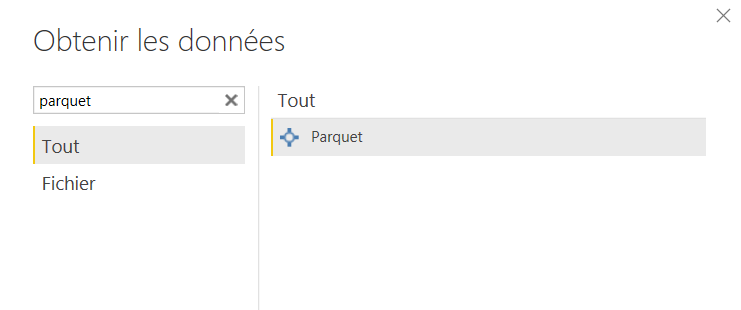
Ce connecteur attend le chemin d’un fichier Parquet et non d’un répertoire contenant les partitions sous forme de fichiers distincts. Nous découvrons ainsi la fonction du langage M qui réalise la lecture du fichier : Parquet.Document().
= Parquet.Document(File.Contents("C:\Users\PaulPeton\Documents\Python Scripts\Parquet\my_to_parquet.parquet"))
Cette fonction est documentée depuis juin 2020 mais elle n’a pas fait l’objet d’une grande communication jusqu’à présent (janvier 2021) et la roadmap Power BI indique un (nouveau ?) connecteur Parquet pour mars 2021.
Pour lire le contenu d’un dossier, nous pouvons sans problème appliquer la technique de connexion à un dossier sur un compte de stockage Azure, puis lire chaque fichier à l’aide du bouton “expand” de la colonne “Content” contenant tous les binaries. Cette manipulation crée automatique une fonction d’import contenant le code suivant.
= (Paramètre1) => let
Source = Parquet.Document(Paramètre1)
in
Source
Attention, pour réaliser cette opération, il faut au préalable filtrer les fichiers ne correspondant pas à des partitions (commit, started, SUCCESS pour un dossier Parquet généré par Databricks), qui débutent tous par un caractère underscore.
= Table.SelectRows(Source, each not Text.StartsWith([Name], "_"))
Les données se chargent alors en mettant bout à bout toutes les partitions !
Il est maintenant tentant d’essayer une actualisation incrémentielle de notre dataset, sur une période d’un mois. Pour autant, celle-ci n’est pas garantie comme nous l’indique le message d’alerte dans la pop-up de paramétrage du rafraichissement.
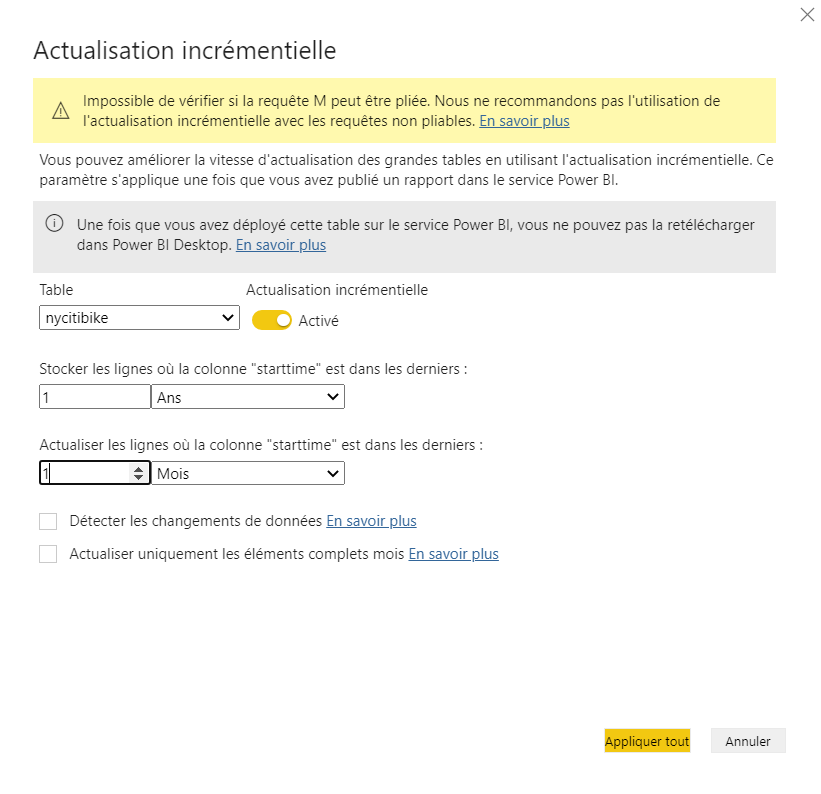
Une traduction approximative annonce que la requête “ne peut être pliée”, il s’agit ici du concept de query folding : la requête ne pourrait appliquer un filtre (de dates) en amont du chargement complet des données. Ceci signifie tout simplement de le mécanisme incrémentiel ne se réaliserait pas.
Afin de tester ce fonctionnement, nous publions le rapport sur un espace de travail Premium du service Power BI. Il sera alors possible d’ouvrir une connexion à l’espace à partir du client lourd SQL Server Management Studio.
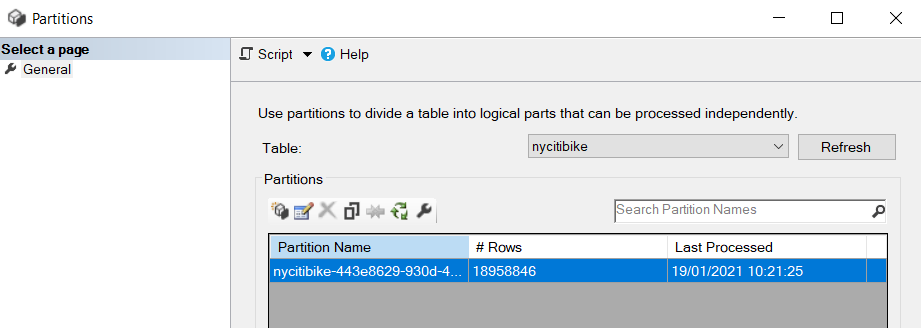
Au premier chargement, nous n’aurons qu’une seule partition.
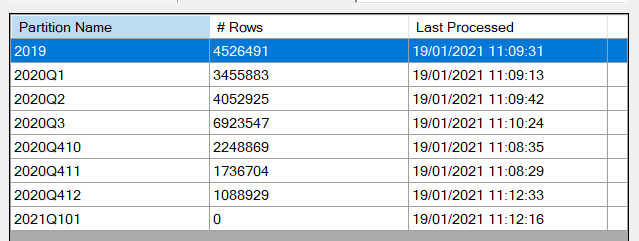
Mais en actualisant le dataset depuis le service, les partitions apparaissent.
Nous observons bien qu’une nouvelle actualisation du jeu de données n’affecte pas toutes les partitions. C’est gagné !
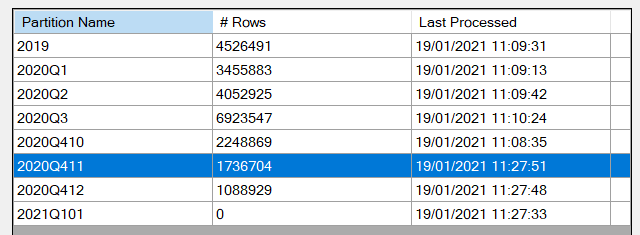
En ajoutant des fichiers supplémentaires, nous observons aussi que le paramètre de stockage de lignes (ici, sur un an) fonctionne et cela permet donc de créer un dataset actualisé sur une période glissante.
Pour terminer, précisons que la requête réalisée ici peut tout à fait être exécutée au sein d’un dataflow Power BI et servir ainsi à la création de différents rapports.
[EDIT du 23/01/2021 : cette approche fonctionne aussi avec le format Delta Lake créé depuis Azure Databricks, et c’est tant mieux car ce format apporte beaucoup d’avantages, qui seront sûrement abordés dans un prochain article.]