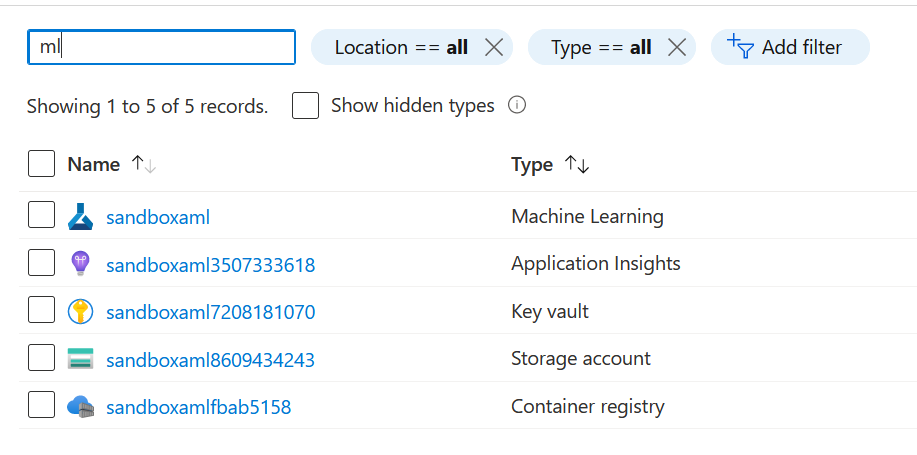
Si vous avez provisionné un service Azure Machine Learning, vous vous êtes certainement aperçu que celui-ci ne venait pas seul au sein du resource group.
Il est en effet accompagné par un compte de stockage qui servira à enregistrer des éléments comme des datasets ou bien les artefacts liés aux modèles. Le container registry servira quant à lui à conserver les images Docker générées pour les services web prédictifs. Le Key Vault jouera son rôle de stockage des clés, secrets ou passphrases. Reste le service Application Insights.
Application Insights, pour quoi faire ?
Application Insights est une branche du service Azure Monitor qui permet de réaliser le monitoring d’applications comme des applications Web, côté front mais aussi back. De nombreux services Azure (Azure Function, Azure Databricks dans sa version enterprise, etc.) peuvent être surveiller grâce à Application Insights.
La manière la plus concrète d’obtenir un résultat avec ce service est sans doute d’utiliser l’interface Log Analytics. Celle-ci se lance en cliquant sur le bouton logs.
L’interface de Log Analytics nous invite à écrire une nouvelle requête dans le langage KustoQL, dont la syntaxe est disponible ici. Ce langage est aussi utilisé dans l’outil Azure Data Explorer.
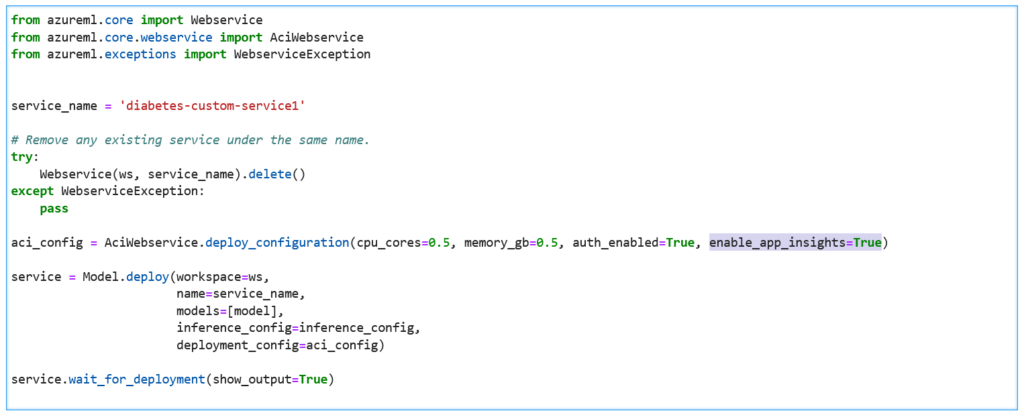
Mais avant de pouvoir obtenir des résultats, nous devons déployer un service web prédictif sur lequel App Insights a été activé. Nous le faisons en ajoutant la propriété enable_app_insights=True dans la définition de la configuration d’inférence.
Il faut également que du texte soit “imprimé” au moment de l’exécution de la fonction run(), tout simplement à l’aide de la fonction print().
Quelques exemples de notebooks sont disponibles dans ce dépôt GitHub.
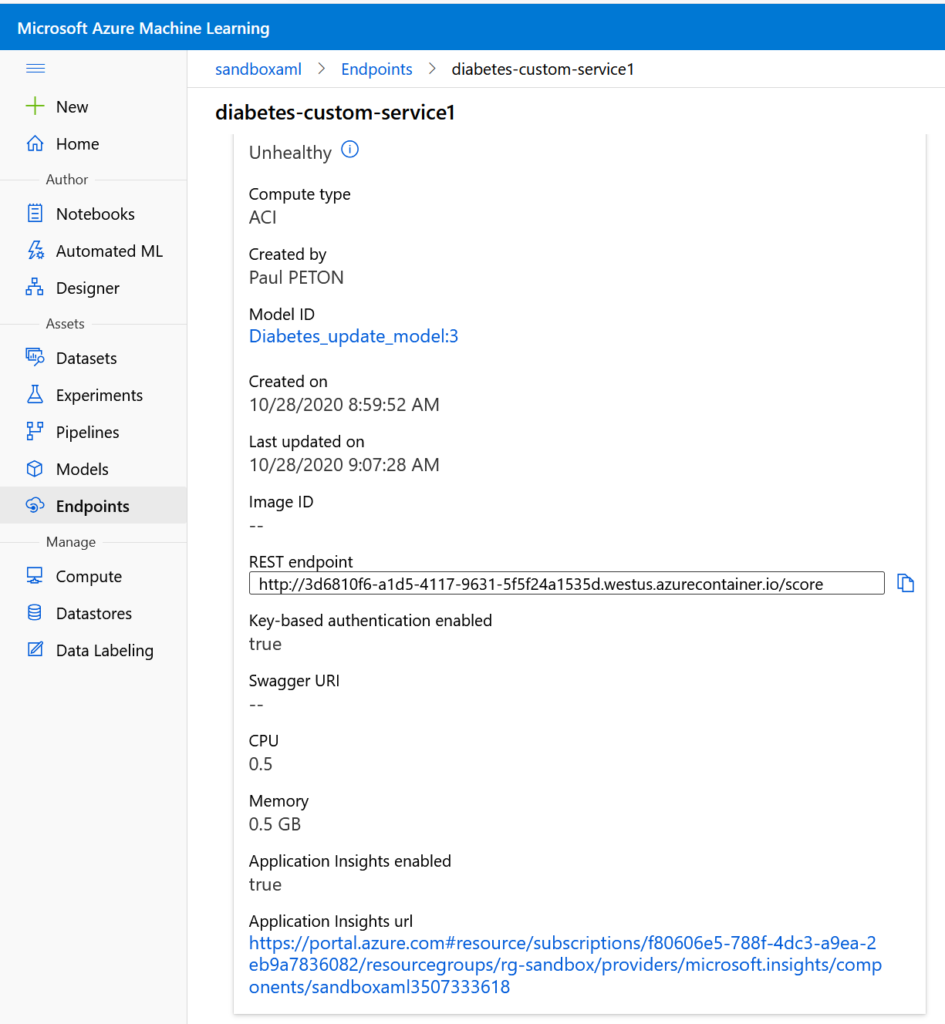
Après publication ou mise à jour du service web, une URL apparaît dans l’interface et donne accès au service App Insights correspondant.
Exploiter Log Analytics
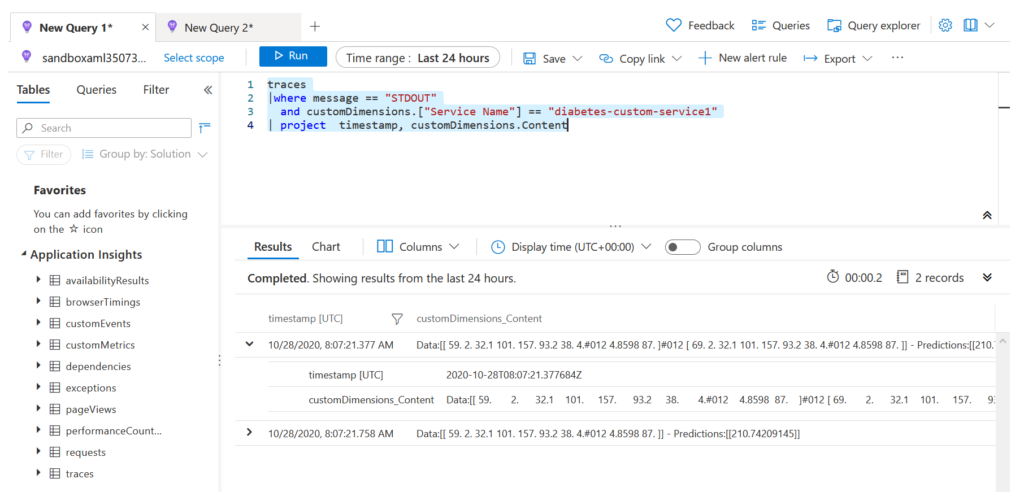
Il est maintenant possible de lancer une première requête dans l’interface Log Analytics, avec la syntaxe suivante :
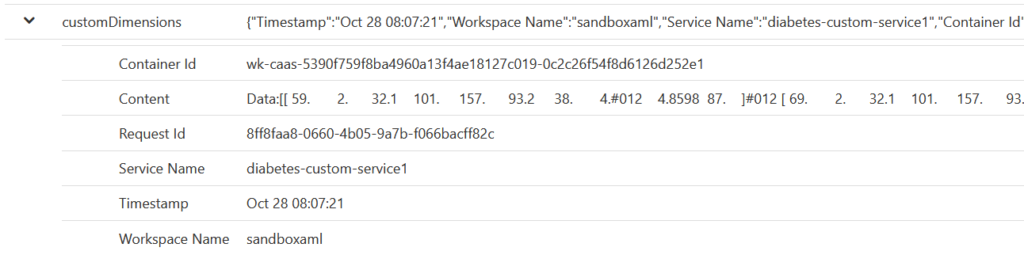
Le service Azure Machine Learning a créé une “custom dimension“, nouvel objet au format JSON, interrogeable par le langage KustoQL. Celui-ci contient des informations comme l’identifiant du container associé, le nom de l’espace de travail ainsi que du service déployé.
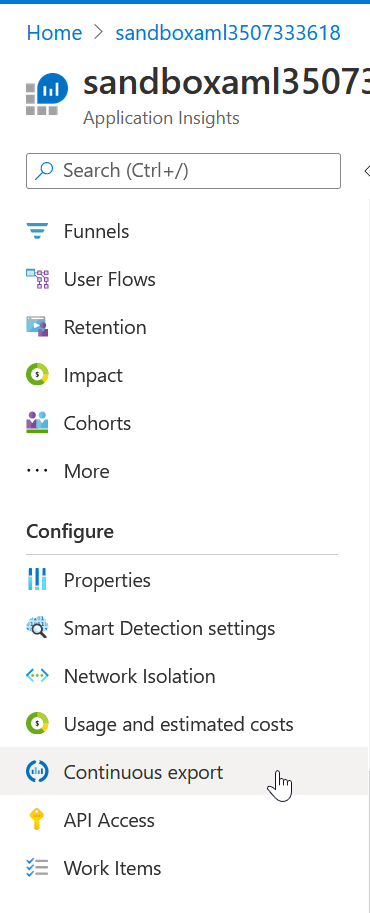
Afin de conserver les logs sur la durée, un mécanisme d’export continu pourra être mis en œuvre et stockera les informations sur un compte de stockage.
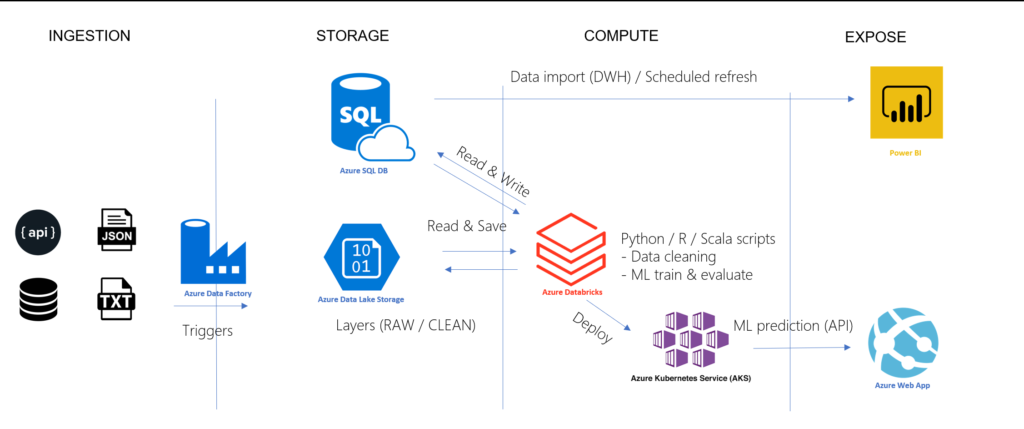
Dans une architecture cloud Azure, la ressource de “compute” Databricks va bien souvent être utilisée pour transformer la donnée brute en donnée dite nettoyée ou enrichie. Cette donnée peut bien sûr être stockée sur un Data Lake, par exemple dans un format Parquet (nous y reviendrons en fin d’article) mais les outils d’exploration et de visualisation de données comme Microsoft Power BI présentent de nombreux avantages à s’appuyer sur une base de données relationnelle (actualisation incrémentielle, DirectQuery…).
Nous partirons ainsi de l’architecture Azure ci-dessous :
Architecture Azure hybride pour des projets data de visualisation et de prévision
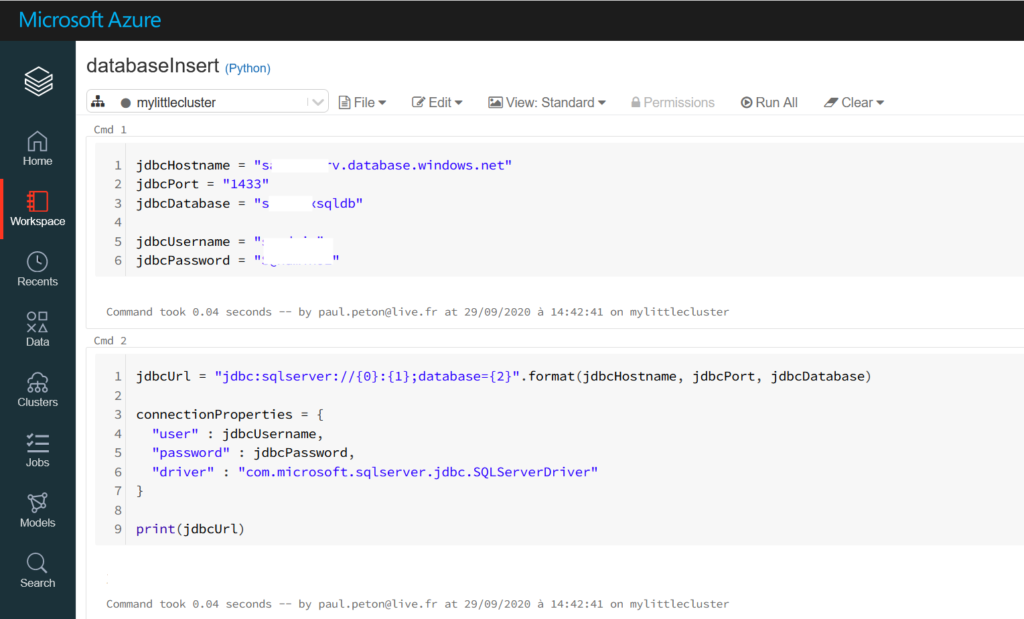
Nous lançons tout d’abord un notebook Python où nous définissons la chaîne de connexion. Il sera bien sûr très judicieux d’utiliser ici le secret scope de Databricks pour stocker toutes ces informations.
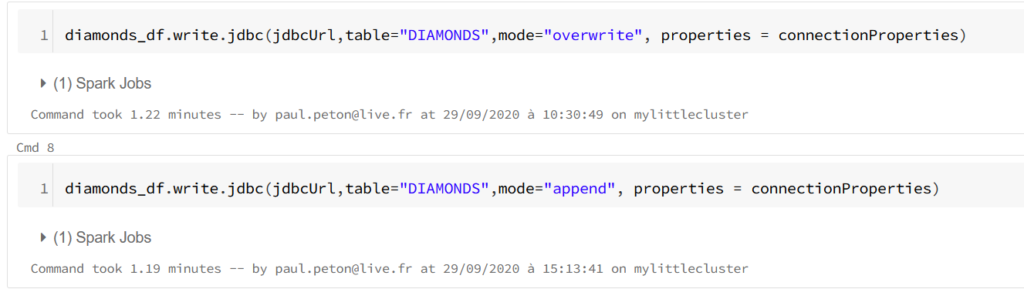
Il s’agit maintenant d’écrire un jeu de données nettoyées et travaillées en mémoire sous forme de Spark dataframe dans une table de la base de données. Cette opération se fait tout simplement au moyen de la méthode write associée aux informations de connexion : URL JDBC et propriétés de connexion.
Le paramètre de mode permet de choisir entre un “annule et remplace” de la table au moyen de la valeur overwrite ou une insertion à l’aide du mot clé append.
Il n’y a donc ici pas de mode prévu pour la suppression ou la mise à jour. Il faudra penser ce scénario de manière différente et peut-être au travers du format de fichier Delta, basé sur le format Parquet et sur lequel existent des méthodes delete et upsert. Pour autant, ce fichier restera en dehors de la base de données.
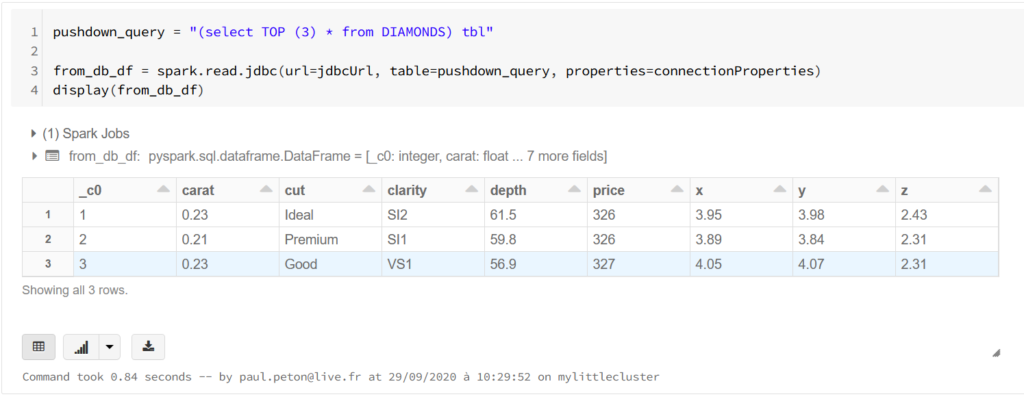
La méthode read de Spark est également possible et se fait en soumettant une requête SQL au travers du driver JDBC. Nous utilisons ici la syntaxe SQL propre à la base de données, ici le Transac-SQL de Microsoft.
L’alias de table sur la requête est indispensable pour être interpréter par le paramètre table de la méthode read.
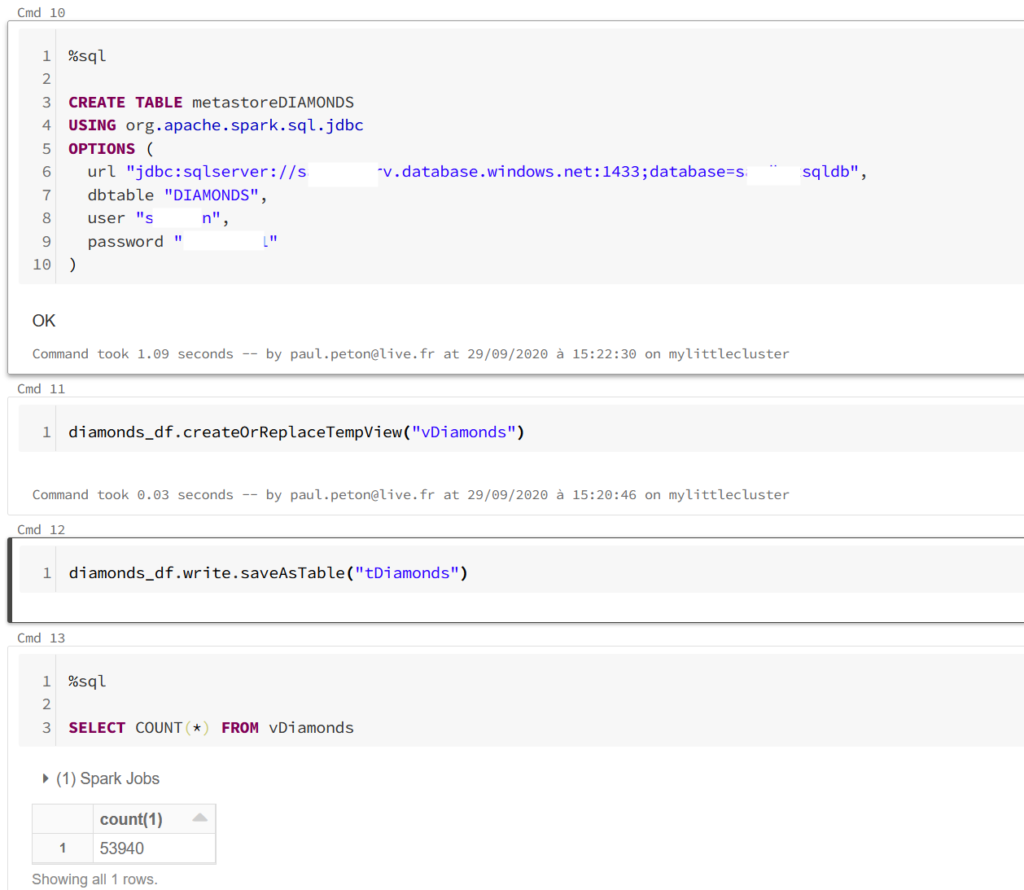
Pour aller un peu plus loin dans l’exploitation de ce driver JDBC, nous pouvons créer une table dans le métastore du cluster, copie d’une table de la base de données.
Il est alors possible de créer des interactions en Spark SQL entre des vues créées à partir de dataframes Spark (ou Pandas en les convertissant au préalable) et la table du métastore. Ce scénario ne réalise qu’une lecture des données de la base et des opérations d’écriture sur cette table ne seront bien sûr pas répercutées sur la base de données.
Nous avons ici utilisé le driver JDBC de manière simple avec une ressource de type SQL Database. Vous retrouverez ici une autre manière de procéder au travers de Polybase pour Azure SQL Datawarehouse. Ce service Azure étant maintenant renommé Azure Synapse Analytics et disposant de nouvelles fonctionnalités, de prochains articles décriront les modes d’interaction entre fichiers, dataframes et tables. En attendant, je vous recommande cet épisode du podcast Big Data Hebdo autour de Synapse.
Suite à mon premier article sur le nouveau programme 2020 de cette certification Microsoft, je continue à décrire les différents outils présents dans le nouveau studio Azure Machine Learning, en suivant le plan donnée par le programme de la certification. Attention, le contenu peut ne pas être exhaustif comme le rappelle la mention “may include but is not limited to“.
Run experiments and train
models
Create models by using
Azure Machine Learning Designer
Le Concepteur (ou Designer en anglais) n’est accessible qu’avec la licence Enterprise et correspond à l’ancien portail Azure Machine Learning Studio. La documentation complète est disponible ici.
Nous cliquons ensuite sur le bouton « + » pour démarrer une nouvelle expérimentation. Mais il sera très intéressant regarder les différents exemples disponibles, en cliquant sur « afficher plus d’échantillons ».
May include but is not limited to:
• create a training
pipeline by using Designer
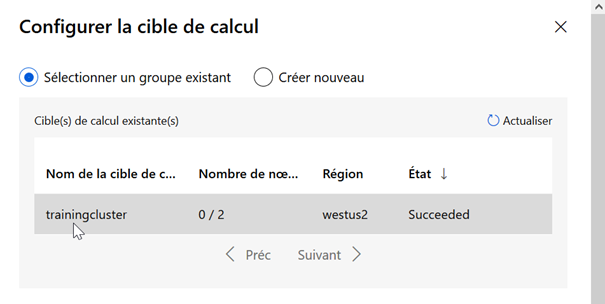
La première chose à paramétrer est l’association de l’expérience avec une cible de calcul de type « cluster d’entrainement ».
Nous utiliserons ensuite les modules disponibles dans le menu latéral de gauche.
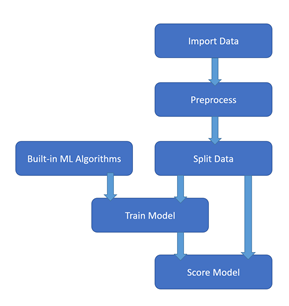
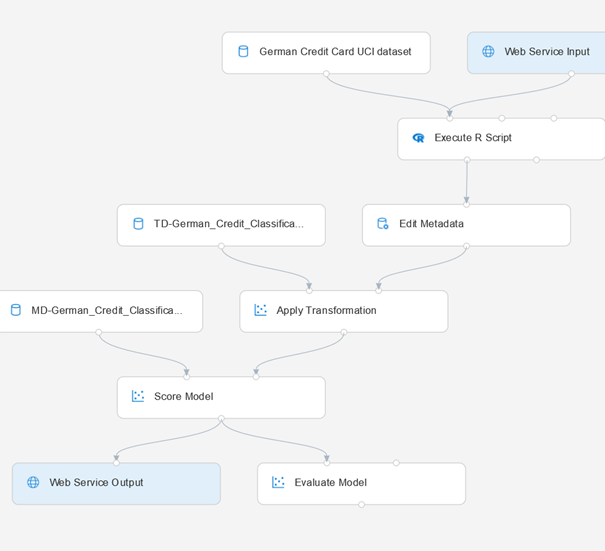
Ces modules nous permettront de construire un « pipeline » dont la structure classique est décrite par le schéma ci-dessous.
• ingest data in a
Designer pipeline
La première étape consiste à désigner les données qui
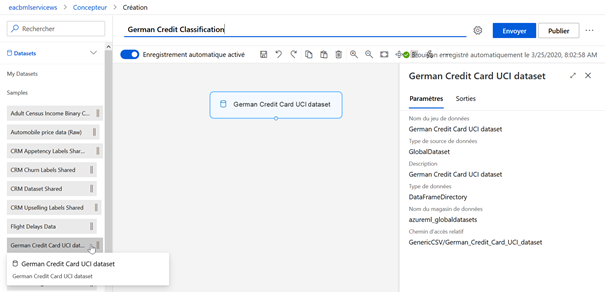
serviront à l’expérience. Nous choisissons pour cet exemple le jeu de données
« German Credit Card UCI dataset » en réalisant un
glisser-déposer du module de la catégorie Datasets > Samples.
Les jeux de données préalablement chargés à partir des magasins de données sont quant à eux disponibles dans Datasets > My Datasets.
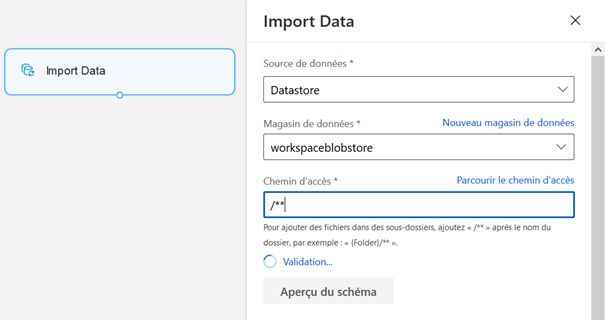
Le module « Import Data » permet de se connecter directement à une URL via HTTP ou bien à un magasin de données.
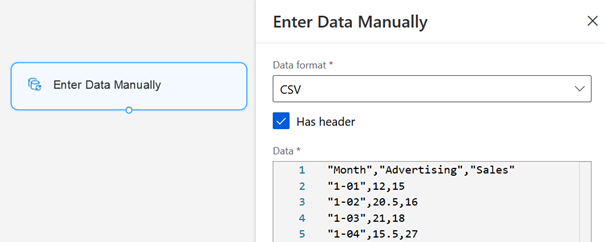
Il est enfin possible de charger des données manuellement à l’aide du module « Enter Data Manually ».
Ces deux dernières méthodes ne
sont pas recommandées, il est préférable de passer par la création propre d’un
jeu de données dans le menu dédié.
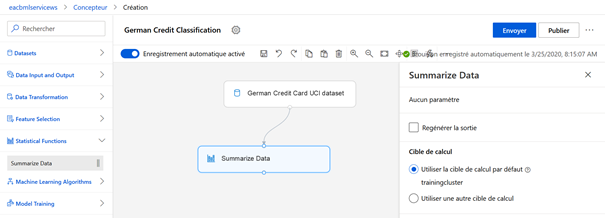
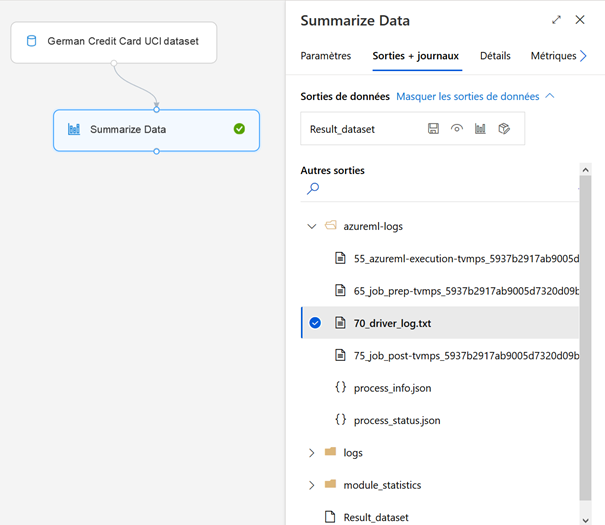
Afin de bien appréhender le jeu de données, nous ajoutons temporairement un composant « Summarize Data », de la catégorie Statistical Functions. Les deux modules doivent être reliés l’un à l’autre, en glissant la sortie du précédent vers l’entrée du suivant.
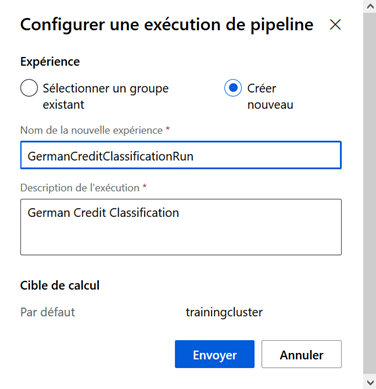
Nous cliquons sur le bouton « Envoyer » pour exécuter ce premier pipeline.
Un nom doit être donné à
l’expérience (entre 2 et 36 caractères, sans espace ni caractères spéciaux
hormis les tirets haut et bas).
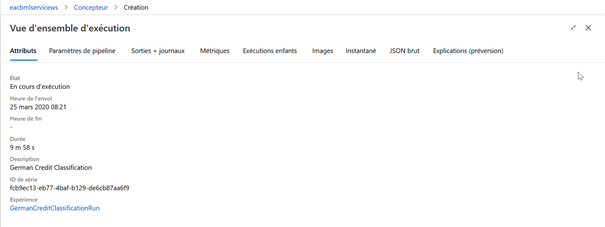
Au cours de l’exécution, une vue d’ensemble est disponible.
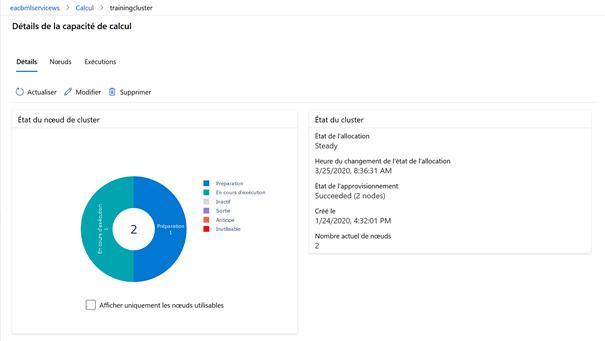
Depuis le menu Calcul, un graphique résume l’état des nœuds du cluster d’entrainement.
Une fois les étapes validées (coche verte sur chaque module), les sorties et journaux d’exécution sont accessibles. Le symbole du diagramme en barres donne accès aux indicateurs de centrage et de dispersion sur les différentes variables.
• use Designer modules to
define a pipeline data flow
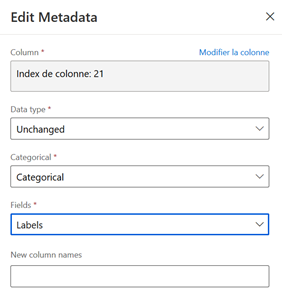
Nous recommandons d’utiliser l’édition des métadonnées pour identifier la variable jouant le rôle de label. Cette astuce permettra par la suite de conserver un paramétrage des modules utilisant la colonne de type « label ». Il sera également possible de désigner toutes les autres colonnes du jeu de données par « all features » dans les boîtes de dialogue de sélection.
Pour une variable binaire dans la cadre d’une classification, la variable est également déclarée comme catégorielle.
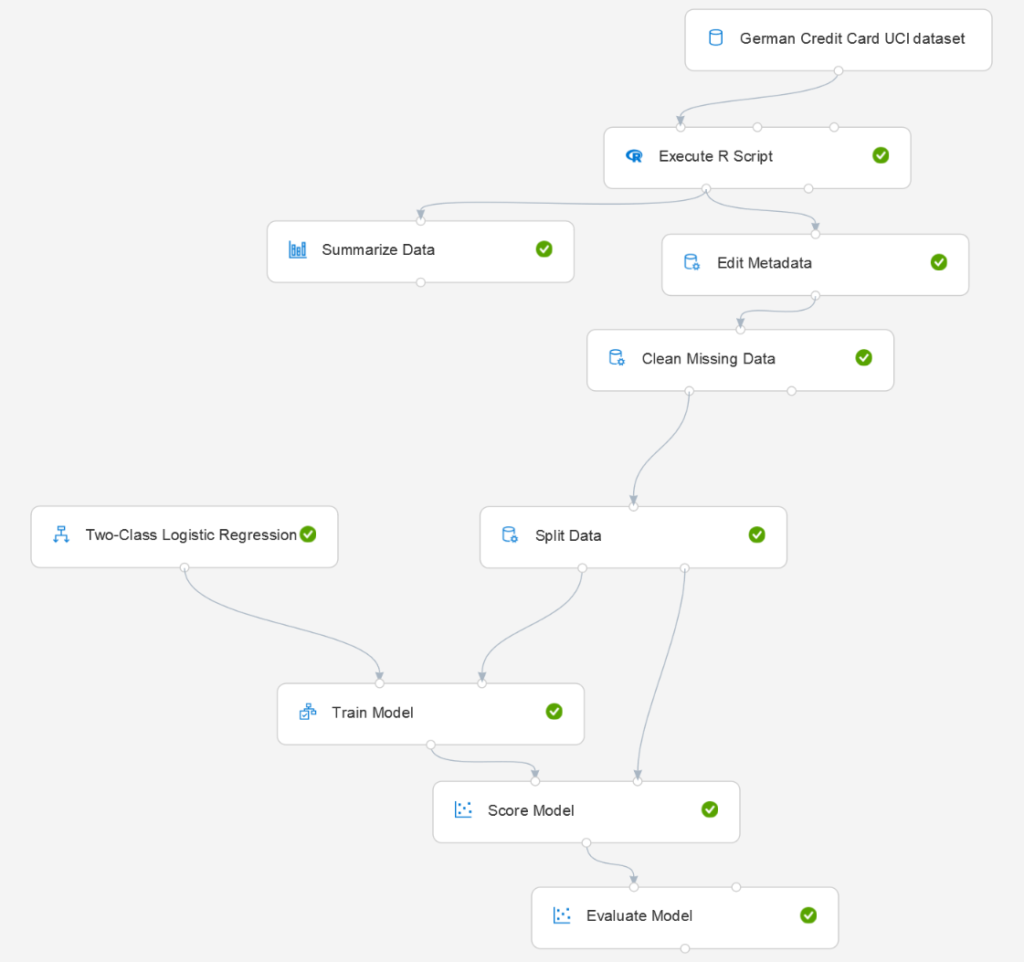
Nous construisons ensuite un pipeline classique de la sorte :
Une fois un modèle entrainé avec succès, un nouveau bouton apparaît en haut à droite de l’écran.
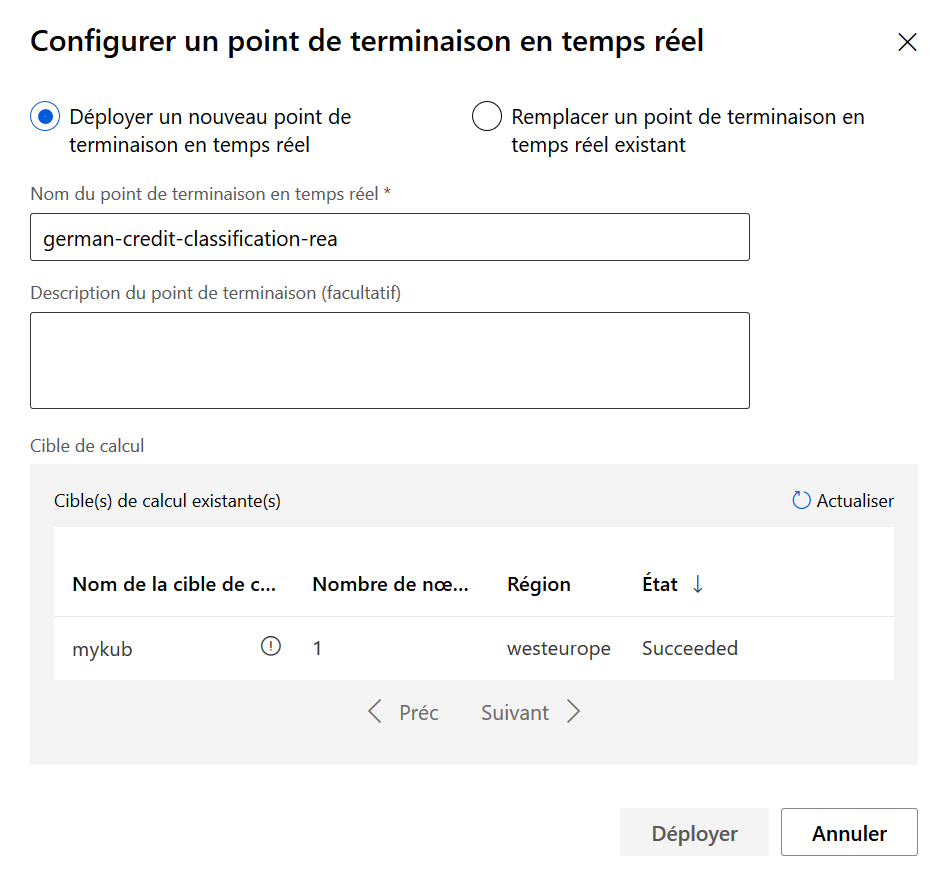
Nous créons un pipeline d’inférence en temps réel pour obtenir un service Web prédictif à partir de notre modèle. Des modules d’input ou d’output sont automatiquement ajoutés.
Il est alors nécessaire d’exécuter une nouvelle fois le pipeline pour ensuite publier le service d’inférence. Le bouton « déployer » est ensuite accessible.
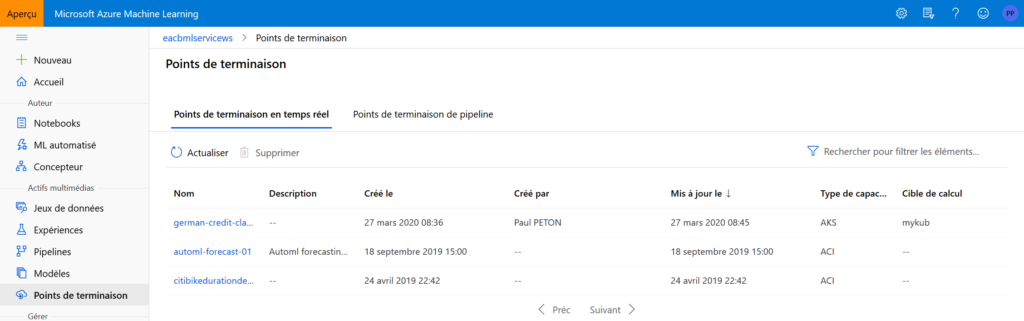
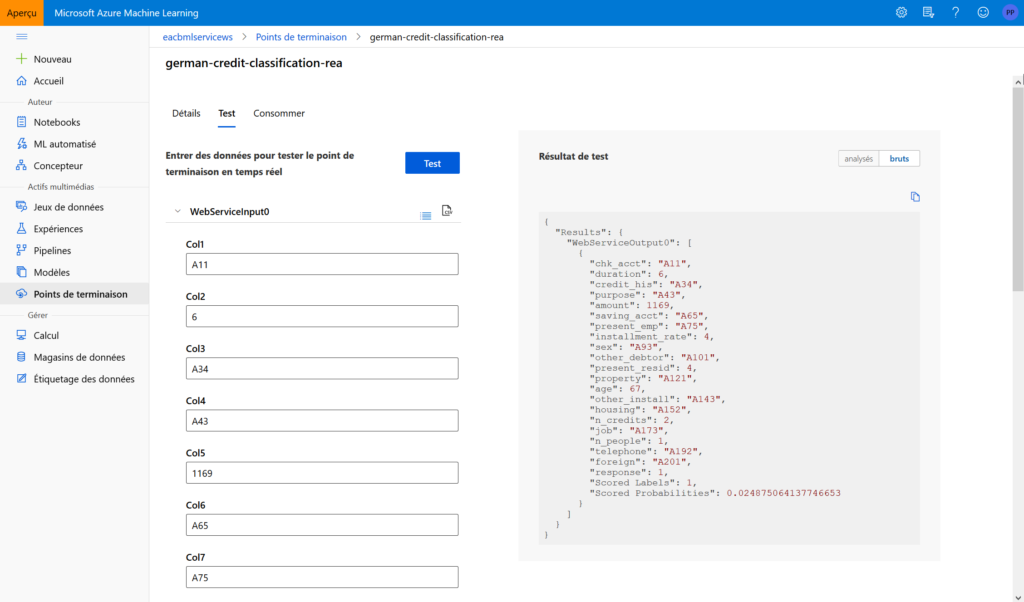
Une fois le déploiement réussi avec succès, le point de terminaison (“endpoint“) est visible dans le menu dédié.
Nous retrouvons dans les écrans dédiés l’URL du point qui donnera accès aux prévisions. Il s’agit d’une API REST, sous la forme suivante :
Une fenêtre de test facilite la soumission de nouvelles données.
L’onglet “consommer” donne enfin des exemples de codes prêts à l’emploi en C#, Python ou R, ainsi qu’un mécanisme de sécurité basé sur des clés ou jetons d’authentification.
• use custom code modules
in Designer
Des modules personnalisés peuvent être intégrés dans le pipeline, en langage R ou Python.
Les modules de script disposent d’entrées et de sorties, accessibles au travers de noms de variables réservés.
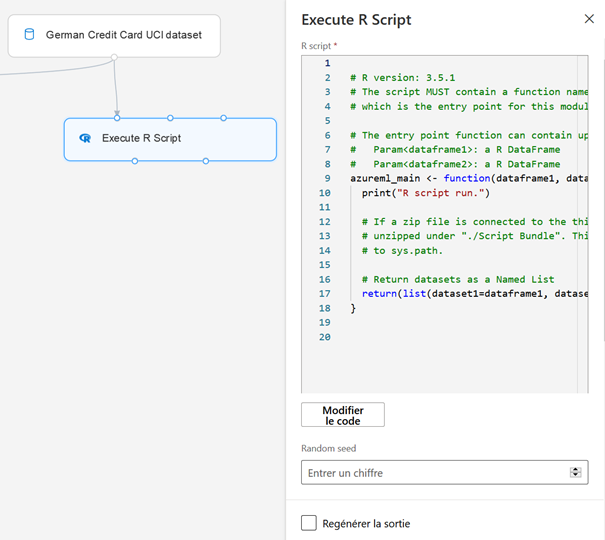
Ainsi, pour un script R personnalisé, le modèle de code généré est une structure de fonction :
# R version: 3.5.1
azureml_main <- function(dataframe1, dataframe2){
print("R script run.")
# If a zip file is connected to the third input port, it is
# unzipped under "./Script Bundle". This directory is added
# to sys.path.
# Return datasets as a Named List
return(list(dataset1=dataframe1, dataset2=dataframe2))
}
Les entrées 1 & 2 sont identifiées respectivement sous
les noms dataframe1 et dataframe2.
Les deux sorties sont par défaut nommées dataset1 et
dataset2 et retournées sous forme d’une liste de deux éléments. Il est possible
de modifier ces noms même si cela n’est pas conseillé.
Pour nommer les colonnes du jeu de données German Credit Card, nous utilisons le code R suivant :
azureml_main <- function(dataframe1, dataframe2){
print("R script run.")
colnames(dataframe1) = c("chk_acct", "duration", "credit_his", "purpose", "amount", "saving_acct", "present_emp", "installment_rate", "sex", "other_debtor", "present_resid", "property", "age", "other_install", "housing", "n_credits", "job", "n_people", "telephone", "foreign", "response")
# Return datasets as a Named List
return(list(dataset1=dataframe1, dataset2=dataframe2))
La troisième entrée du module est dédiée à un fichier zip
contenant des librairies supplémentaires. Ces packages doivent être au préalable
installer sur un poste local, généralement dans le répertoire :
C:\Users\[user]\Documents\R\win-library\3.2
Créer
un dossier contenant les sous-dossiers des packages transformés en archives
(.zip) puis réaliser une nouvelle archive .zip à partir de ce dossier. Importer
ensuite l’archive obtenu comme un jeu de données. Le module obtenu sera
raccordé à la troisième entrée du module Execute R/Python Script : Script
Bundle (Zip).
Pour les scripts Python, nous disposons également d’un module permettant de créer un modèle d’apprentissage qui sera ensuite connecté à un module « Train Model ».
Le code Python à rédiger se base sur les packages pandas et scikit-learn et doit s’intégrer dans le modèle suivant :
import pandas as pd
from sklearn.linear_model import LogisticRegression
class AzureMLModel:
# The init method is only invoked in module "Create Python Model",
# and will not be invoked again in the following modules "Train Model" and "Score Model".
# The attributes defined in the init method are preserved and usable in the train and predict method.
def init(self):
# self.model must be assigned
self.model = LogisticRegression()
self.feature_column_names = list()
# Train model
# Param: a pandas.DataFrame
# Param: a pandas.Series
def train(self, df_train, df_label):
# self.feature_column_names record the names of columns used for training
# It is recommended to set this attribute before training so that later the predict method
# can use the columns with the same names as the train method
self.feature_column_names = df_train.columns.tolist()
self.model.fit(df_train, df_label)
# Predict results
# Param: a pandas.DataFrame
# Must return a pandas.DataFrame
def predict(self, df):
# Predict using the same column names as the training
return pd.DataFrame({'Scored Labels': self.model.predict(df[self.feature_column_names])})
Le modèle utilisé peut être remplacé dans la fonction __init__.
Les variables en entrée du modèle peuvent être également listées dans cette
fonction.