
La donnée non structurée est partout autour de nous : texte, image, son, vidéo… rien de cela ne tient dans une base de données SQL ou NOSQL. Les grands modèles de langage comme GPT-4 sont une aubaine pour structurer les corpus de texte, et en particulier les conversations entre plusieurs personnes, desquelles il faudra extraire quelques informations bien structurées.
Nous allons ici tester différents prompts sur le dialogue ci-dessous, tenu dans un contexte bancaire, entre un client, une employée et un banquier. L’objectif principal sera de produire un fichier JSON avec plusieurs informations relatives au client.
L’employée : – Bonjour, que puis-je faire pour vous ?
Le client : – Bonjour Madame, je souhaite ouvrir un compte.
L’employée : – Bien, alors vous devez prendre rendez-vous avec un conseiller clientèle.
Le client : – Et dois-je apporter des papiers ?
L’employée : – Oui, il faut apporter un justificatif de domicile, une facture d’électricité ou de téléphone par exemple.
Le client : – Oui, et c’est tout ?
L’employée : – Non, il faut une pièce d’identité, carte d’identité ou passeport si vous êtes étranger.
Le client : – Bien. Et combien ça coûte ?
L’employée : – À la BG, c’est gratuit et il n’y a pas de somme minimum à verser.
Le client : – C’est parfait ! Est-ce que je peux prendre un rendez-vous maintenant ?
L’employée : – Bien sûr ! Pouvez-vous revenir demain à 15 h 30 ? Le client : – Oui, c’est possible. L’employée : – Très bien. Alors vous avez rendez-vous avec monsieur Didier Desmarais.
Le client : – D’accord, merci et au revoir.
L’employée : – Je vous en prie, au revoir.
Le conseiller : – Bonjour monsieur, je suis Didier Desmarais. Asseyez-vous.
Le client : – Bonjour monsieur, je m’appelle Frank Bayer et je viens pour ouvrir un compte.
Le conseiller : – Bien, alors, tout d’abord est-ce que vous avez les documents nécessaires ?
Le client : – Oui, j’ai tout apporté.
Le conseiller : – Parfait, je les photocopie et ensuite je vous explique tout.
Le conseiller : – Alors, nous allons ouvrir un compte courant pour les opérations de tous les jours, vous pouvez déposer ou retirer des espèces, faire virer votre salaire, verser des chèques ou émettre des chèques, recevoir ou émettre des virements, ou encore effectuer des retraits ou payer par carte. Vous recevrez un relevé de compte (la liste des opérations effectuées sur le compte pour une période déterminée) tous les mois (gratuit) ou tous les 15 jours (service payant).Cette conversation est issue de ce site dédié à l’apprentissage de la langue française.
Nous débutons par un premier prompt qui vise à expliquer comment se structure le dialogue et quelles sont les informations recherchées.
Tu es un assistant IA qui aide à résumer un dialogue entre plusieurs personnes. Chaque personne sera citée en début de phrase et suivi par le signe :.
Tu produiras un fichier JSON contenant les informations suivantes : nom du client, prénom du client, date du rendez-vous, heure du rendez-vous, nom du conseiller et sous forme imbriquée, les documents fournis puis les services souscrits. Tu pourras ensuite répondre à des questions spécifiques sur la conversation.
Le premier résultat est assez satisfaisant mais il peut être amélioré. La date est donnée à “demain” et n’est donc pas contextualisée. Le modèle GPT-4 n’a pas pas accès à l’information de la date du jour, nous devons la préciser dans le prompt. Ensuite, les services souscrits sont trop détaillés. Nous allons donc fournir dans le prompt un exemple de la structure JSON attendue, en nous inspirant tout simplement de la première itération réalisée.
Tu es un assistant IA qui aide à résumer un dialogue entre plusieurs personnes. Chaque personne sera citée en début de phrase et suivi par le signe :.
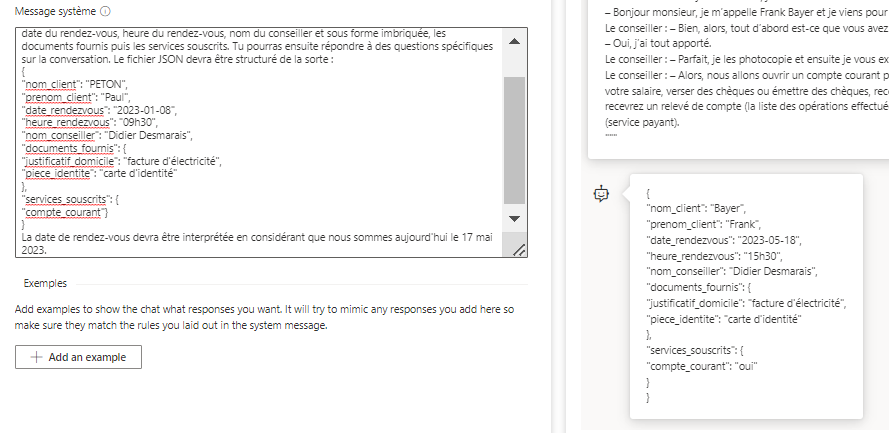
Tu produiras un fichier JSON contenant les informations suivantes : nom du client, prénom du client, date du rendez-vous, heure du rendez-vous, nom du conseiller et sous forme imbriquée, les documents fournis puis les services souscrits. Tu pourras ensuite répondre à des questions spécifiques sur la conversation. Le fichier JSON devra être structuré de la sorte :
{
"nom_client": "PETON",
"prenom_client": "Paul",
"date_rendezvous": "2023-01-08",
"heure_rendezvous": "09h30",
"nom_conseiller": "Jérôme KERVIEL",
"documents_fournis": {
"justificatif_domicile": "facture d'électricité",
"piece_identite": "carte d'identité"
},
"services_souscrits": {
"compte_courant"}
}
La date de rendez-vous devra être interprétée en considérant que nous sommes aujourd'hui le 17 mai 2023.C’est beaucoup mieux ! Nous avons résolu les deux problèmes identifiés.
Il reste une interprétation de la part du modèle quant aux documents fournis. Ceux-ci sont les documents cités par l’employée et nous ne savons pas si le client a fourni une facture d’électricité ou bien de téléphone. Il serait préférable que le modèle ne donne l’information que si celle-ci est réellement fiable.
Nous pouvons compléter le précédent prompt de la sorte :
Les documents fournis devront correspondre à ce que le client déclare et non ce que propose la banque. Si ce n'est pas le client qui donne l'information, indiquer "Ne Sait Pas" dans le fichier JSON.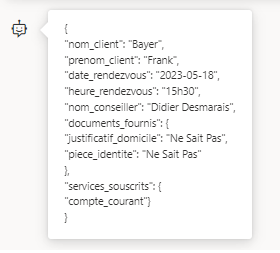
Modifions légèrement le dialogue pour vérifier la robustesse de ce prompt.
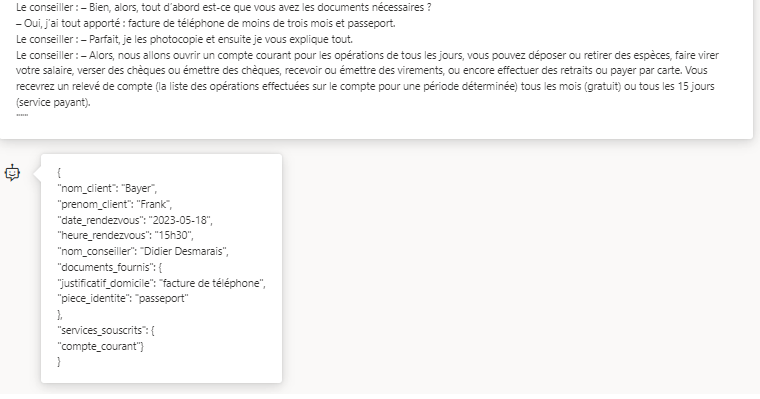
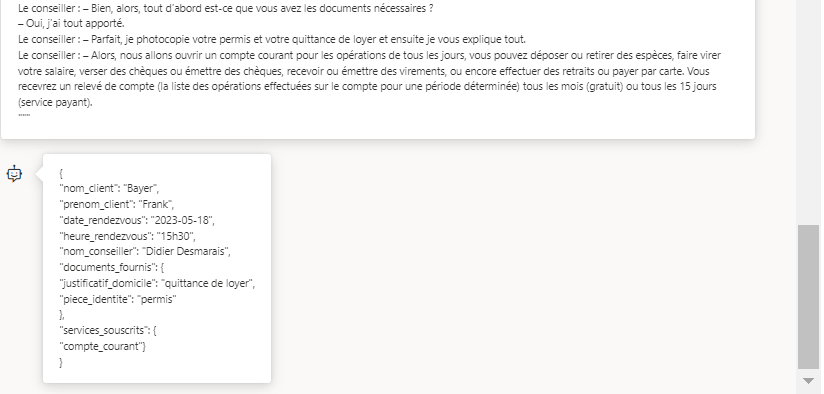
Terminons par une série de questions / réponses sur le dialogue. Ici, le modèle GPT-4 est à son aise.
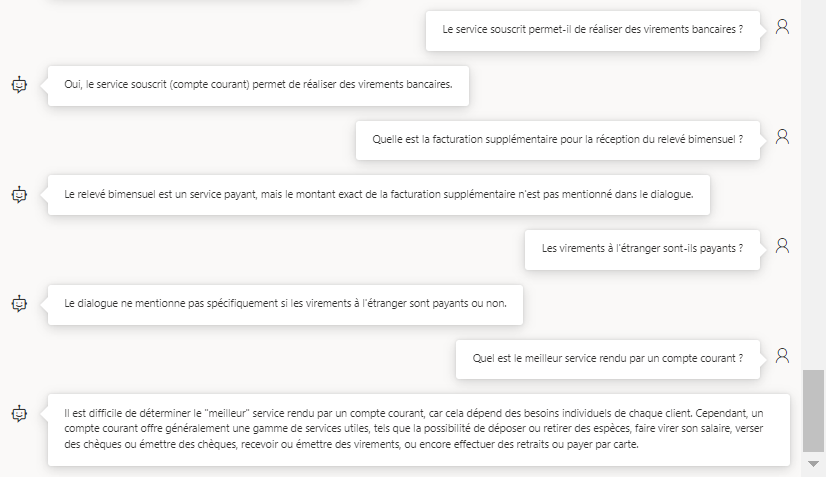
Cette démarche fonctionne ici très bien car le dialogue tient dans la limite des 32000 tokens autorisés par le modèle GPT-4. Pour des corpus de texte plus long, nous devrons utiliser une autre approche, qui sera détaillée dans de prochains articles sur ce blog.