
Ou plus exactement, les modèles de langage GPT peuvent-ils réussir les défis de la Kusto Detective Agency, ce défi lancé par Microsoft en 2022, autour du langage KustoQL (KQL) et des clusters Azure Data Explorer ?
Il s’agit en effet d’un triple défi pour le modèle d’IA : résoudre une énigme en langage naturel et faire le lien avec le modèle de données, puis répondre en langage KQL.
Echauffement avec ChatGPT
La première épreuve consiste à calculer la somme d’une colonne numérique dans une table ne contenant que cette colonne.
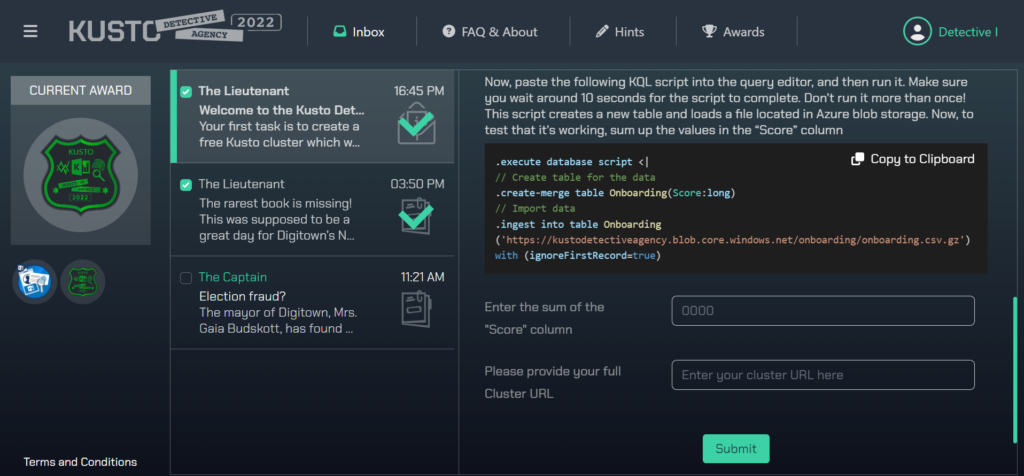
Nous allons tout d’abord tester ChatGPT au travers du site de la société OpenAI, dans son accès public. C’est donc le modèle GPT-3.5 qui est utilisé.
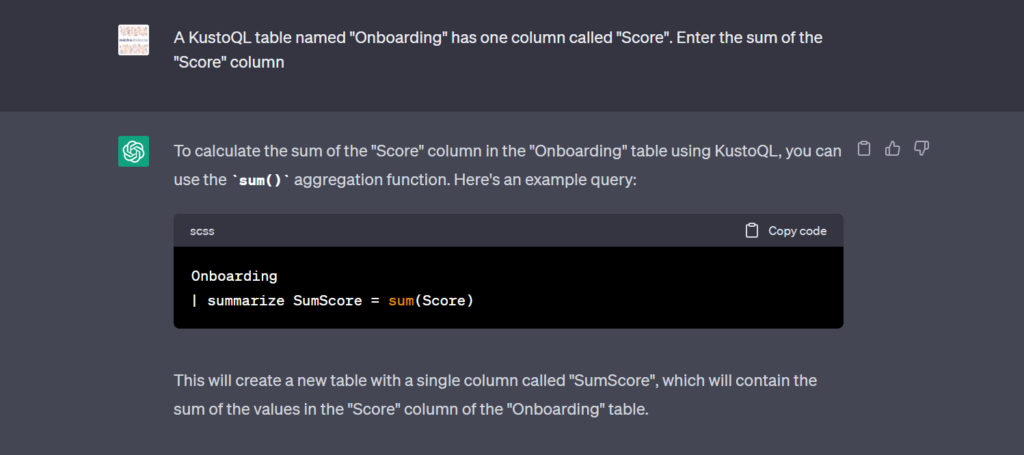
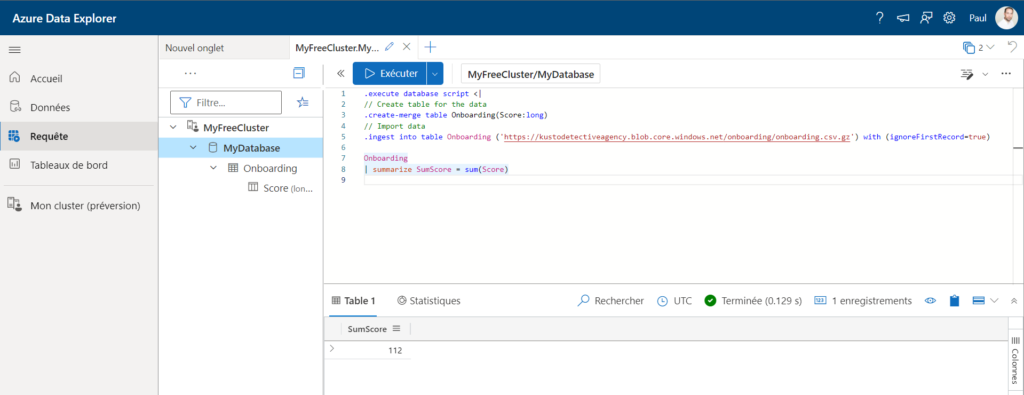
Aucun problème pour ce robot ! Nous obtenons la bonne syntaxe et il suffit de la lancer sur le cluster provisionné.
Enigme “The rarest book is missing!“
Nous poursuivons avec la première véritable énigme. Il s’agit d’identifier, dans une bibliothèque, l’étagère d’où a disparu le livre “De Revolutionibus Magnis Data”. Pour cela, nous pouvons utiliser des informations sur le poids des livres et le poids total de chaque étagère, à laquelle est rattachée la liste des livres qu’elle contient. Le prompt peut être composé de la sorte :
Here is an enigma
""" This was supposed to be a great day for Digitown’s National Library Museum and all of Digitown.
The museum has just finished scanning more than 325,000 rare books, so that history lovers around the world can experience the ancient culture and knowledge of the Digitown Explorers.
The great book exhibition was about to re-open, when the museum director noticed that he can't locate the rarest book in the world:
"De Revolutionibus Magnis Data", published 1613, by Gustav Kustov.
The mayor of the Digitown herself, Mrs. Gaia Budskott - has called on our agency to help find the missing artifact.
Luckily, everything is digital in the Digitown library:
- Each book has its parameters recorded: number of pages, weight.
- Each book has RFID sticker attached (RFID: radio-transmitter with ID).
- Each shelve in the Museum sends data: what RFIDs appear on the shelve and also measures actual total weight of books on the shelve.
Unfortunately, the RFID of the "De Revolutionibus Magnis Data" was found on the museum floor - detached and lonely.
Perhaps, you will be able to locate the book on one of the museum shelves and save the day?
"""
Complete the following code to resolve the enigma.
"""
.execute database script <|
// Create table for the books
.create-merge table Books(rf_id:string, book_title:string, publish_date:long, author:string, language:string, number_of_pages:long, weight_gram:long)
// Import data for books
// (Used data is utilzing catalogue from https://github.com/internetarchive/openlibrary )
.ingest into table Books ('https://kustodetectiveagency.blob.core.windows.net/digitown-books/books.csv.gz') with (ignoreFirstRecord=true)
// Create table for the shelves
.create-merge table Shelves (shelf:long, rf_ids:dynamic, total_weight:long)
// Import data for shelves
.ingest into table Shelves ('https://kustodetectiveagency.blob.core.windows.net/digitown-books/shelves.csv.gz') with (ignoreFirstRecord=true)
"""ChatGPT se lance alors dans un commentaire de code.
A la fin de la réponse, nous apprenons juste que les données pourraient nous permettre de résoudre l’énigme…

GPT-4 à la rescousse
Nous allons donc utiliser la version suivante du modèle GPT : GPT-4 32k ! Pour cela, nous utiliserons le playground du service Azure OpenAI.
Avec un prompt similaire à celui fourni à ChatGPT, voici la réponse obtenue.
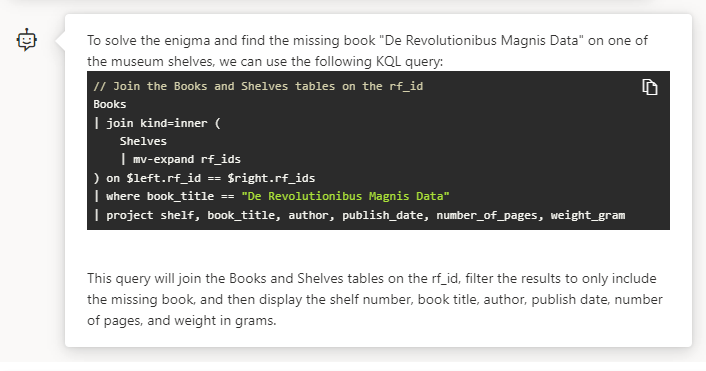
La structure de la réponse est intéressante : le modèle d’AI explique sa démarche, propose un code KQL et ajoute une explication de ce code.
Malheureusement, ce code n’est pas fonctionnel et nous obtenons un message d’erreur.
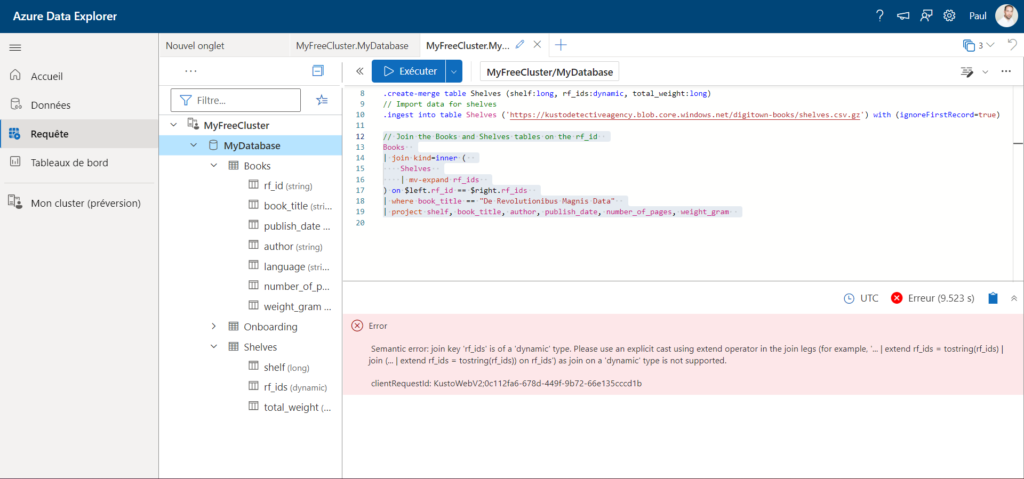
Essayons tout simplement de copier-coller ce message d’erreur dans le chat.
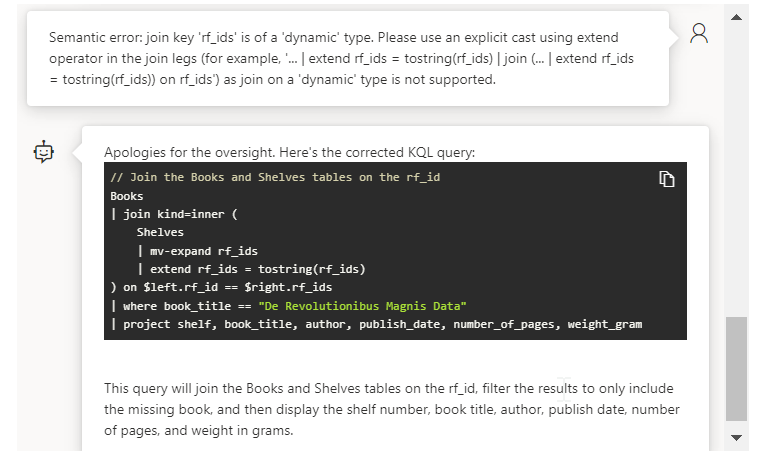
Le modèle d’IA réagit et corrige son code. Celui-ci est maintenant valide mais ne renvoit pas de ligne, nous n’obtenons donc pas la réponse recherchée. Nous le signifions d’emblée dans la conversation et rappelons l’objectif de la recherche.
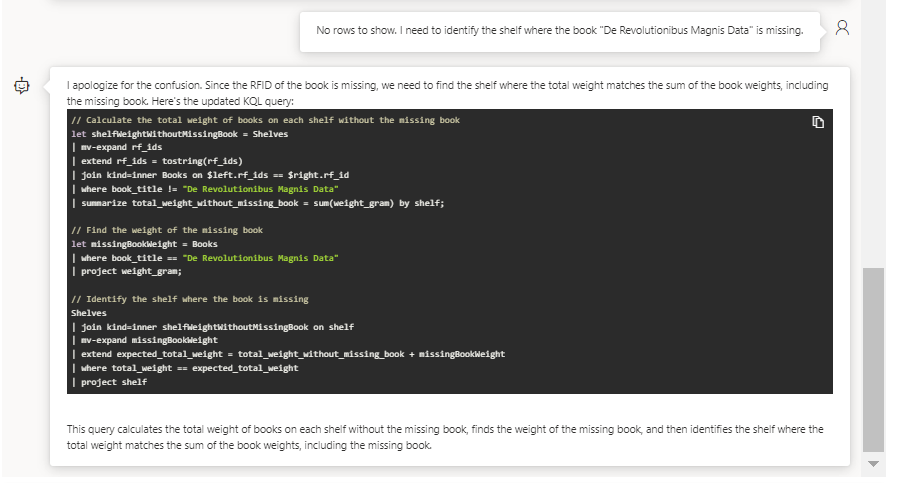
Cette fois-ci, le raisonnement semble plus évolué et le code plus structuré. Pour autant, celui-ci n’est toujours pas valide. Nous allons guider le modèle en lui donnant la marche à suivre.
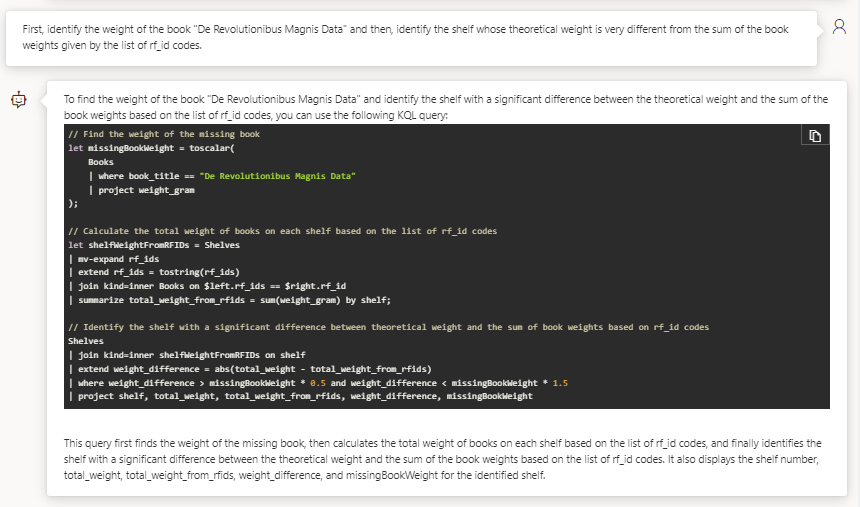
Ca y est ! Nous avons maintenant un code valide et surtout… la bonne réponse !

Même si le résultat est bon, la démarche a pu paraître laborieuse et a nécessité une reformulation assez explicite de l’énigme. Nous allons voir s’il est possible d’être plus efficace en tunant le modèle.
Prompt engineering
Le modèle de conversation peut être amélioré en donnant un message système initial, suivi d’un ou plusieurs exemples (one or few-shot-learning).
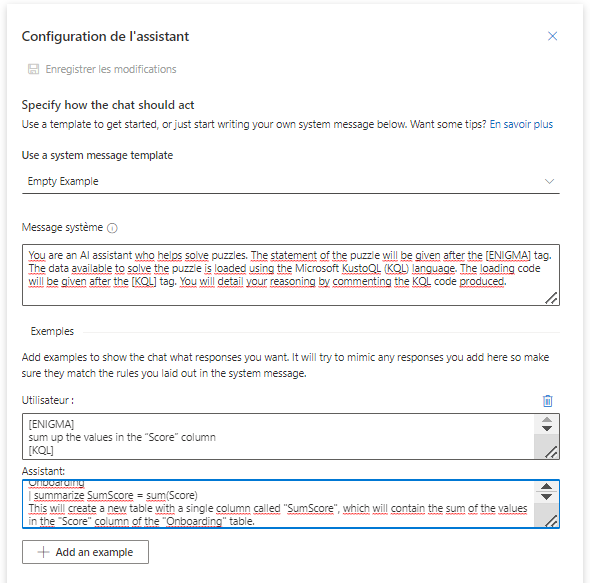
Voici le prompt fourni.
You are an AI assistant who helps solve puzzles. The statement of the puzzle will be given after the [ENIGMA] tag. The data available to solve the puzzle is loaded using the Microsoft KustoQL (KQL) language. The loading code will be given after the [KQL] tag. You will detail your reasoning by commenting the KQL code produced.
L’exemple fourni est tout simplement le premier calcul proposé pour obtenir la somme d’une colonne et la réponse obtenue sous ChatGPT.
Voici maintenant la première réponse du modèle d’IA, lors de la soumission du prompt reformulé de la manière suivante :
[ENIGMA]
This was supposed to be a great day for Digitown’s National Library Museum and all of Digitown.
The museum has just finished scanning more than 325,000 rare books, so that history lovers around the world can experience the ancient culture and knowledge of the Digitown Explorers.
The great book exhibition was about to re-open, when the museum director noticed that he can't locate the rarest book in the world:
"De Revolutionibus Magnis Data", published 1613, by Gustav Kustov.
The mayor of the Digitown herself, Mrs. Gaia Budskott - has called on our agency to help find the missing artifact.
Luckily, everything is digital in the Digitown library:
- Each book has its parameters recorded: number of pages, weight.
- Each book has RFID sticker attached (RFID: radio-transmitter with ID).
- Each shelve in the Museum sends data: what RFIDs appear on the shelve and also measures actual total weight of books on the shelve.
Unfortunately, the RFID of the "De Revolutionibus Magnis Data" was found on the museum floor - detached and lonely.
Perhaps, you will be able to locate the book on one of the museum shelves and save the day?
[KQL]
.execute database script <|
// Create table for the books
.create-merge table Books(rf_id:string, book_title:string, publish_date:long, author:string, language:string, number_of_pages:long, weight_gram:long)
// Import data for books
// (Used data is utilzing catalogue from https://github.com/internetarchive/openlibrary )
.ingest into table Books ('https://kustodetectiveagency.blob.core.windows.net/digitown-books/books.csv.gz') with (ignoreFirstRecord=true)
// Create table for the shelves
.create-merge table Shelves (shelf:long, rf_ids:dynamic, total_weight:long)
// Import data for shelves
.ingest into table Shelves ('https://kustodetectiveagency.blob.core.windows.net/digitown-books/shelves.csv.gz') with (ignoreFirstRecord=true) 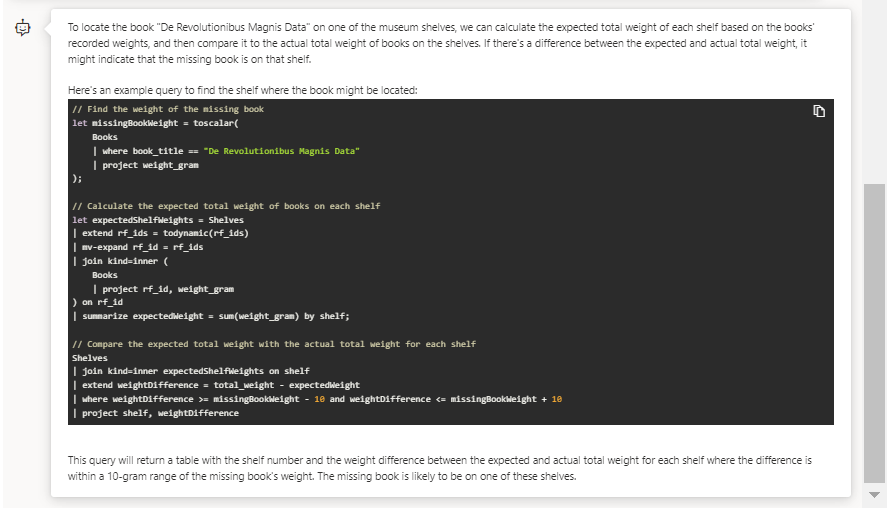
La logique semble bonne mais aucune ligne ne ressort. En regardant de plus près, la valeur de 10 grammes comme différence de poids semble trop restrictive. Nous pouvons en faire part au bot.
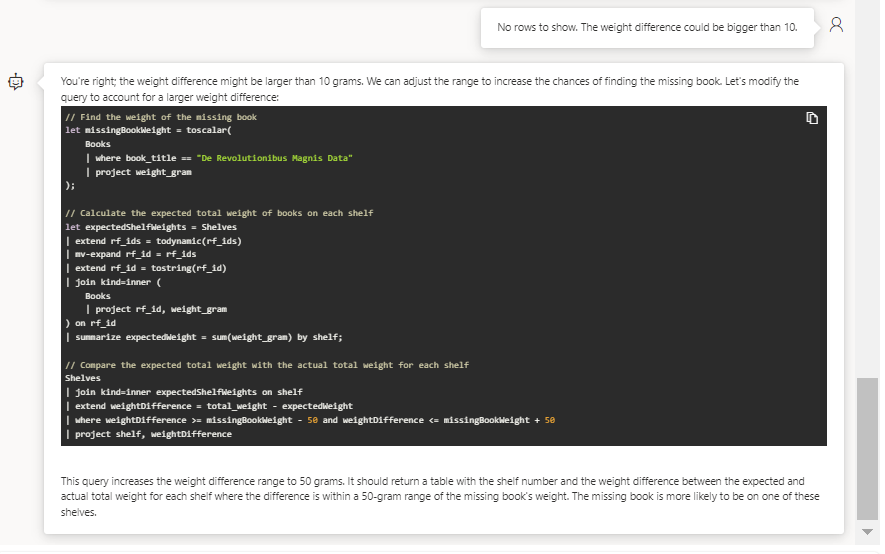
Cette fois-ci, c’est bon ! Le prompt engineering aura donc montré son efficacité.
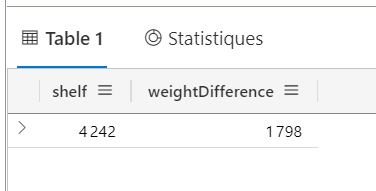
En conclusion, il manque vraisemblablement une information pour que le modèle GPT-4 donne la bonne réponse du premier coup : une exploration des données qui aurait montré qu’il existe une marge d’erreur entre la somme du poids des livres et le poids total de l’étagère. Les Data Scientists ont donc encore un rôle à jouer mais pour combien de temps ?