Nous avons vu dans cet article d’introduction la dualité de Synapse Analytics entre SQL et Spark. Nous développons ici les aspects liés à Apache Spark, framework Open Source de calcul distribué, et recommandé pour le traitement de la Big Data (volume mais aussi vélocité et variété).
Apache Spark pool
L’exploration des données dans un notebook va requérir l’utilisation d’un pool Apache Spark pour exécuter les commandes, comme l’annonce le message d’alerte ci-dessous.
Please select a Spark pool to attach before running cell!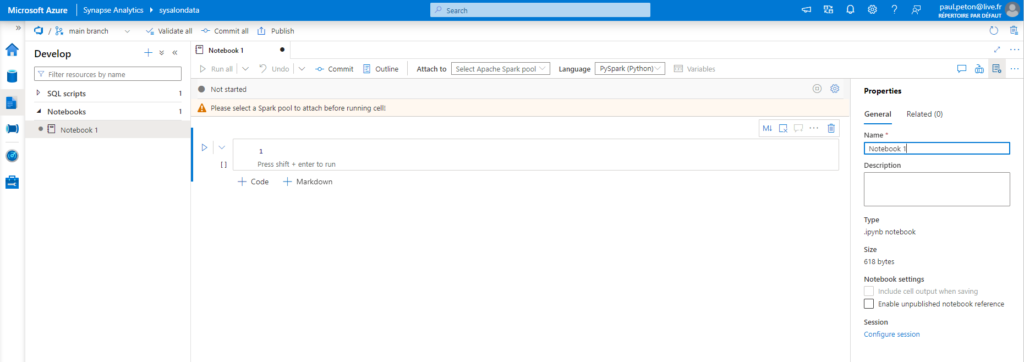
Nous naviguons dans le menu Manage pour créer un nouveau pool ou retrouver les pools existants.
Un pool correspond à un cluster (grappe) de plusieurs nodes (nœuds) pour lequel nous définissons le nombre de nœuds et leur “taille” (size) correspondant aux propriétés RAM, CPU des machines virtuelles.
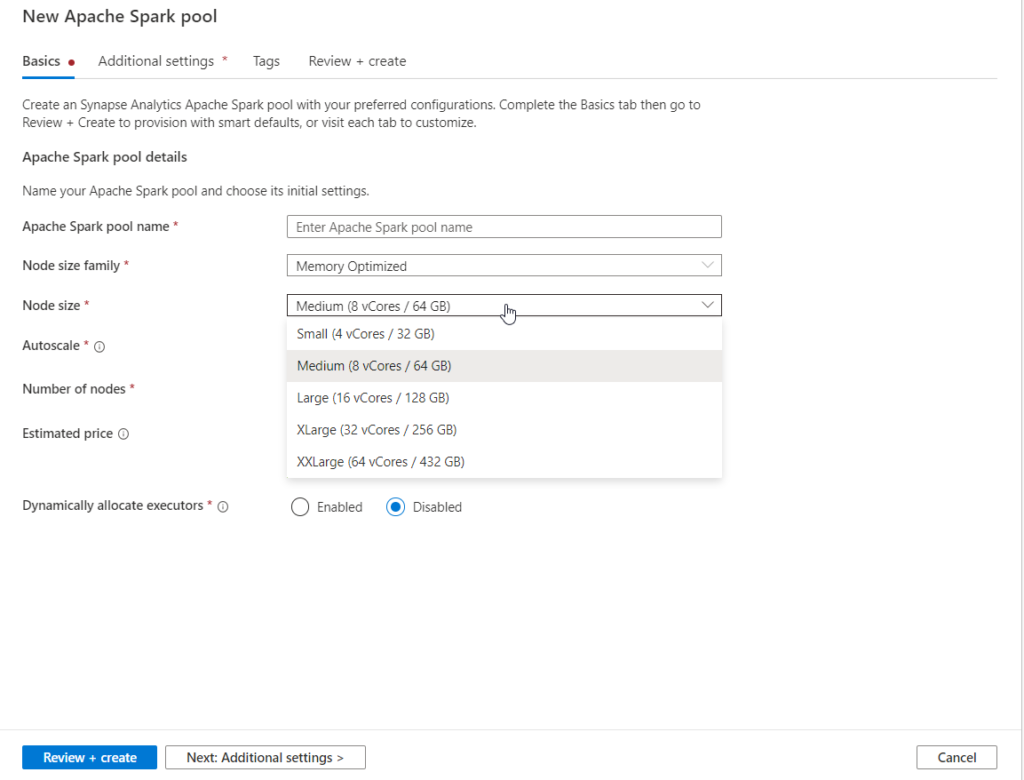
La facturation de ce service dépend bien évidemment de ces deux paramètres, qui pourront être modifiés une fois le pool créé.
Je vous recommande de n’activer que l’autoscaling que si les charges de travail sont très variables, dans un sens comme dans l’autre. Débutez sur un petit nombre de nœuds que vous augmenterez au fur et à mesure, en vous assurant que le code écrit est bien en capacité de se distribuer sur les différents nœuds.
Dans le paramétrage additionnel, nous allons trouver la version principale du framework Spark et les différentes versions des langages associés.
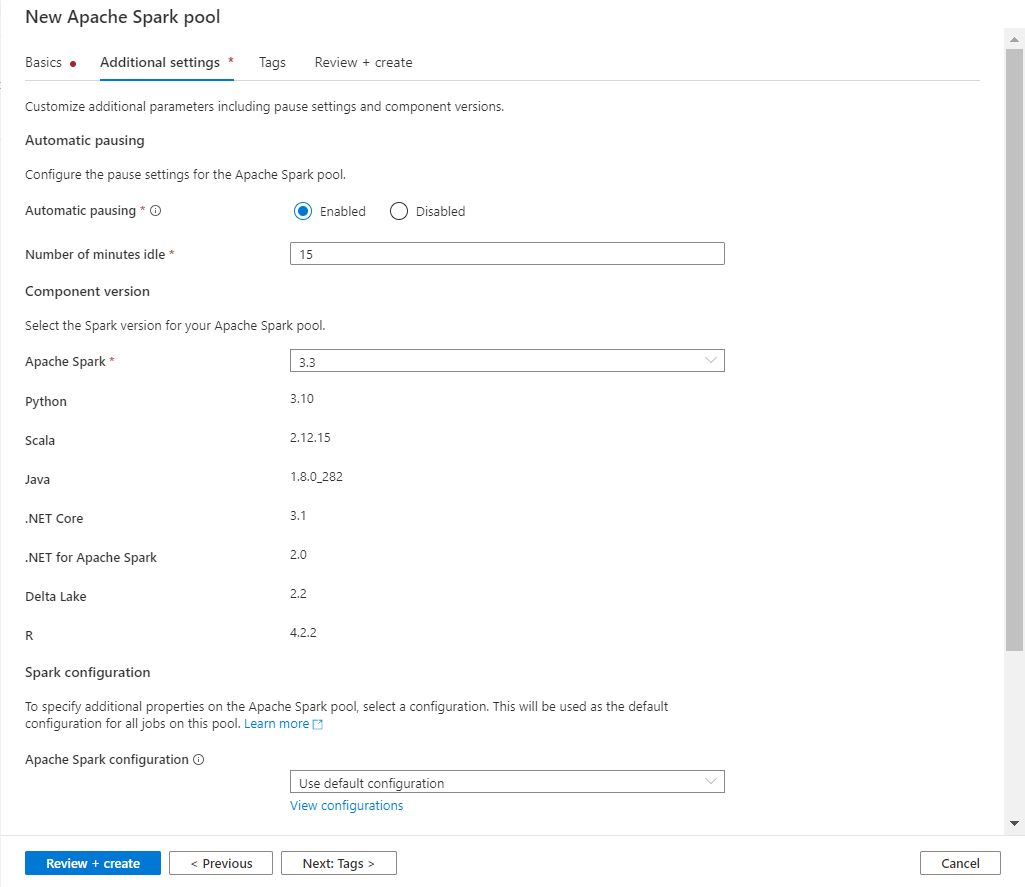
Sur cette boîte de dialogues, nous retrouvons aussi la configuration de pause automatique, enclenchée par défaut et paramétrée pour un arrêt au bout d’une inactivité (aucun job en exécution) de 15 minutes.
Langages disponibles
Dans le notebook, nous pourrons utiliser plusieurs langages.
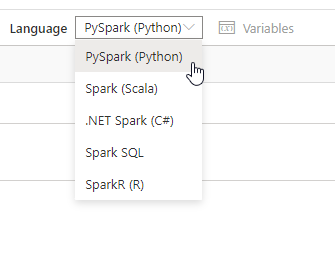
Il est même possible de changer de langage selon les cellules du notebook, à l’aide des commandes magiques comme %%sql, %%csharp, etc. mais cela ne doit pas être une pratique à pérenniser dans le cadre de travaux de production.
Au lancement de la première commande Spark, une nouvelle session débute et cela peut prendre quelques minutes.
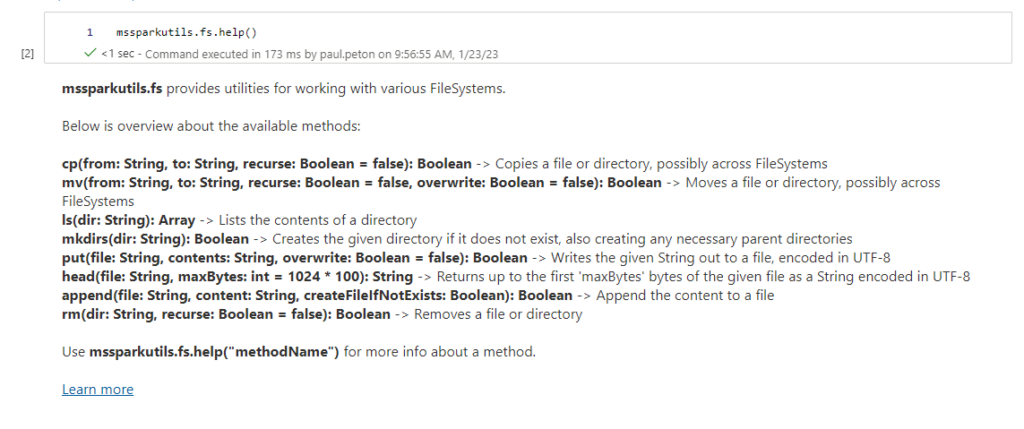
La librairie mssparkutils
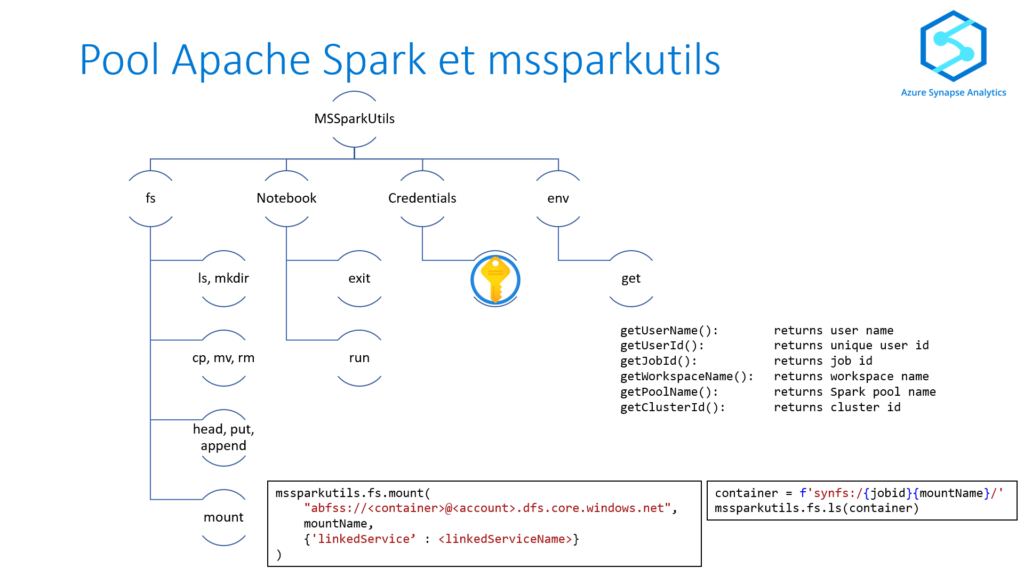
Un des premiers besoins va être de communiquer avec les services du workspace comme les bases SQL et les systèmes de fichiers de type data lake. Pour accéder à des services liés comme un data lake, nous allons nous appuyer sur une librairie pré-installée : mssparkutils pour Microsoft Spark Utilities. La documentation officielle est disponible sur ce lien. Cet outil est très proche de dbutils de Databricks.
Nous allons nous concentrer en particulier sur les commandes liées au file system (fs) : list, copy, move, rm, put…
Nous commençons par “monter” le data lake par défaut afin d’accéder aux fichiers. Nous utilisons pour cela le modèle de code ci-dessous.
mssparkutils.fs.mount(
"abfss://<containername>@<accountname>.dfs.core.windows.net",
"</mountname>",
{"linkedService":<linkedServiceName>}
)
A noter que le nom attribué au point de montage doit débuter par un caractère /.
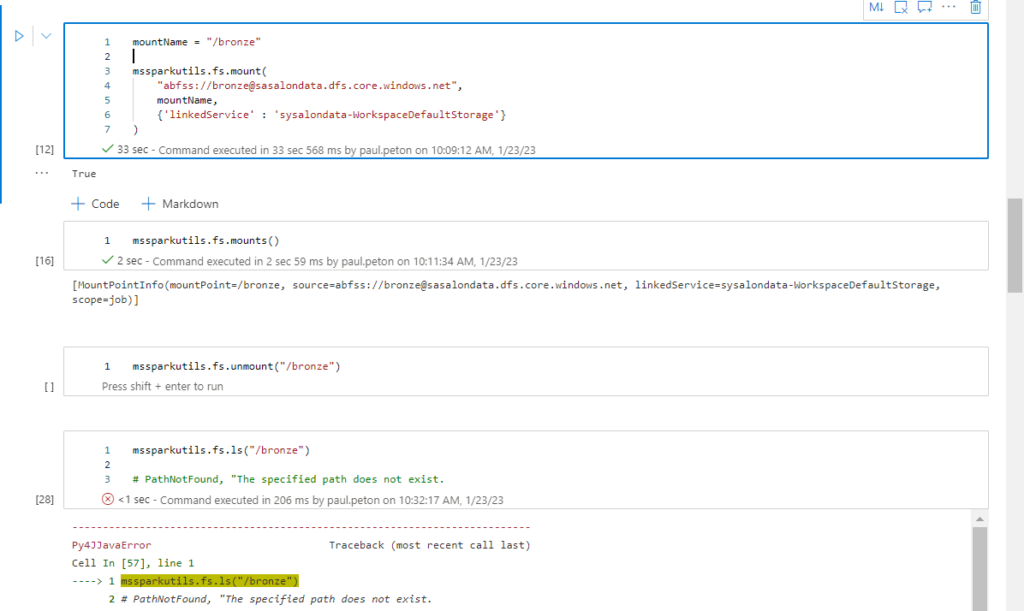
La commande mounts() permet de vérifier les points de montage existants et si besoin, unmount(<mountname>) s’utiliserait pour “démonter” ce point.
Attention, si nous utilisons la syntaxe seule du point de montage pour faire une lecture, nous obtenons une erreur de type PathNotFound. En effet, une première différence apparait ici pour les utilisateurs habitués au dbutils de Databricks.
Nous devons constituer un chemin débutant par le mot clé synfs, suivant de l’identifiant du job, qui se trouve être une variable d’environnement.
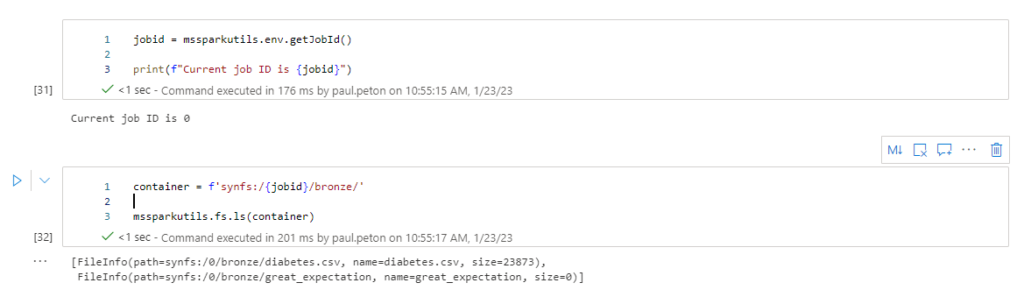
Prenez soin de variabiliser ces éléments car le job id changera à chaque démarrage d’une nouvelle session !
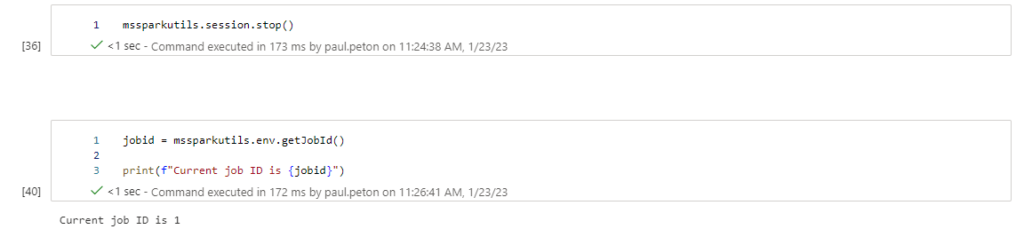
Les points de montage ne sont malheureusement pas pérennes ! A chaque nouvelle session, il sera nécessaire de relance la commande mount.
Le résultat de la commande fs est une liste et les différentes propriétés des fichiers peuvent être isolées par du code :
for file in files:
print(file.name, file.isDir, file.isFile, file.path, file.size)
Les commandes Python de la librairie os peuvent également utiliser ce point de montage. Attention, la syntaxe du path change légèrement avec la disparition du symbole : et l’ajout d’un / avant synfs.
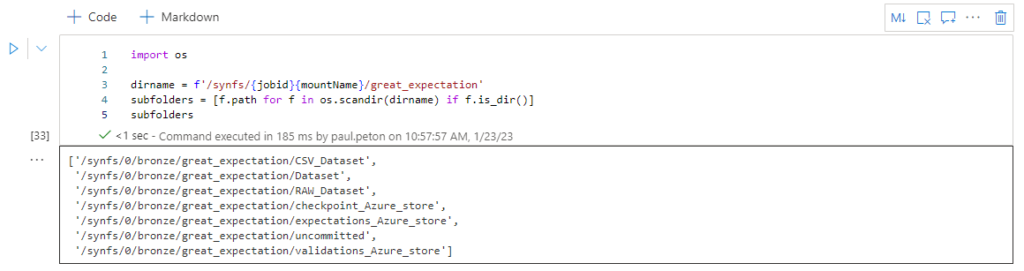
Réalisons maintenant quelques tâches courantes.
Lister et compter tous les fichiers des sous-répertoires
Une simple recherche Google nous montre que la première problématique avec cette librairie mssparkutils est la recherche récursive dans les répertoires !
Heureusement, la recherche nous amène rapidement à découvrir cet excellent repository GitHub : Recursively listing Data Lake files with `display` implemented · GitHub (donnez-lui une étoile :)).
L’exécution imbriquée des deux fonctions deep_ls et convertfiles2df permet d’obtenir un dataframe Pandas avec la liste des fichiers, leur path et la taille en octets.
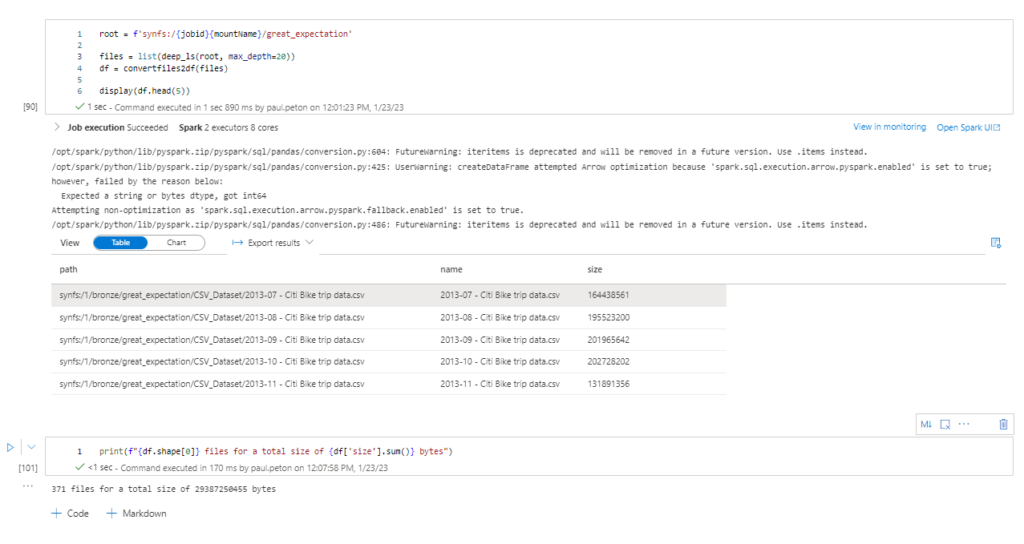
Nous affichons une synthèse à l’aide du print ci-dessous.
print(f"{df.shape[0]} files for a total size of {df['size'].sum()} bytes")
Afficher les premières lignes d’un fichier .csv ou .parquet
La commande mssparkutils.fs.head() répond à ce besoin.

Toutefois, il est difficile d’interpréter les sauts de ligne et de faire par exemple la différence entre les noms de colonne et les valeurs.
Nous allons nous faire aider ici par la génération automatique de syntaxe, en clic droit sur un nom de fichier ou de dossier.
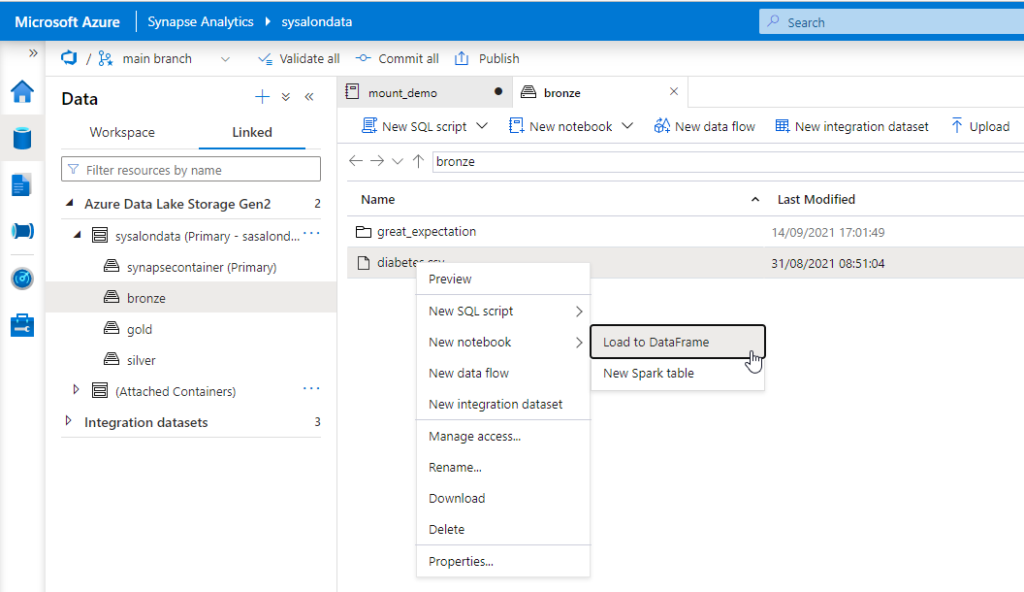
Nous savons que la première ligne constitue les entêtes du fichier.
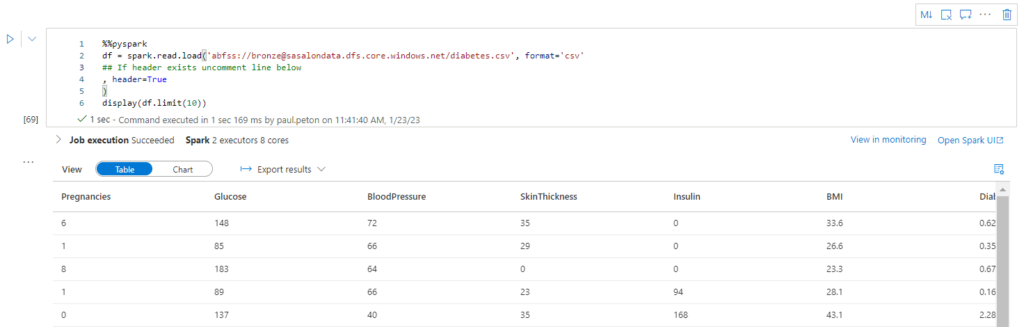
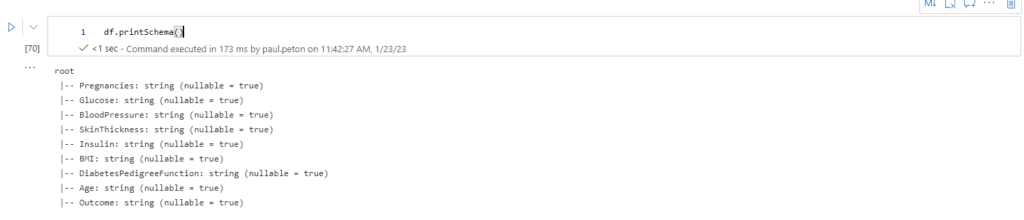
La commande df.printSchema() va nous montrer les types de colonnes. Venant d’un fichier .csv, il n’est pas étonnant de ne retrouver que des chaines de caractères (string).
En appliquant l’option inferSchema = True, nous pouvons demander au moteur de déterminer le type le plus probable de chaque colonne.
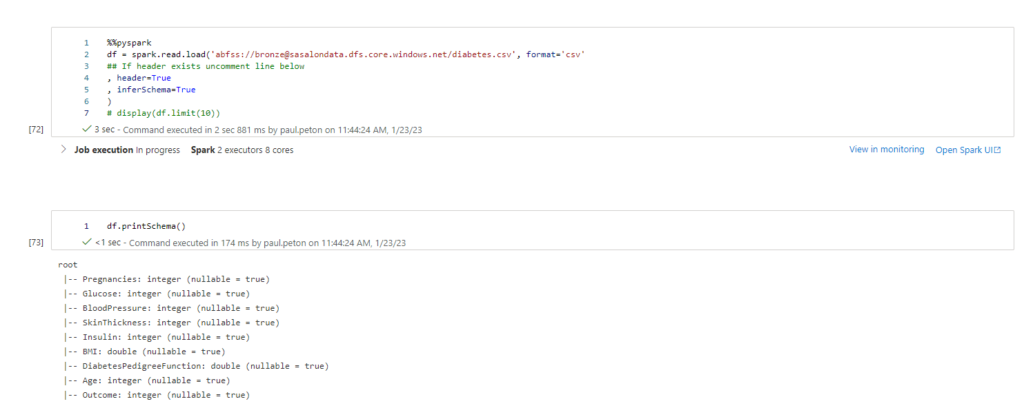
Il est important de rappeler que le format de fichier .parquet conserve les types de colonnes, nous privilégierons donc ce format pour le stockage de données dite “raffinées”.
Utiliser des packages supplémentaires
Les packages disponibles par défaut ne sont généralement pas suffisants pour traiter tous les aspects d’un projet de Data Engineering ou de Data Science. Nous allons donc charger de nouvelles librairies au moyen d’un fichier local requirements.txt.
Le fichier liste tout simplement les packages, avec, idéalement, leur numéro de version.
great-expectations==0.15.44 xgboost==1.7.3
Par défaut, l’installation de packages pour une session n’est pas activée.
Difficile de réaliser une vérification de l’installation autrement qu’en réalisant une commande d’import du package voulu.

Convertir le contenu d’une table SQL en un dataframe
Nous pouvons établir une connexion JDBC à toute base de données mais ici, nous allons de nouveau profiter, pour un scénario en lecture seule, générer le code Spark dans un notebook.
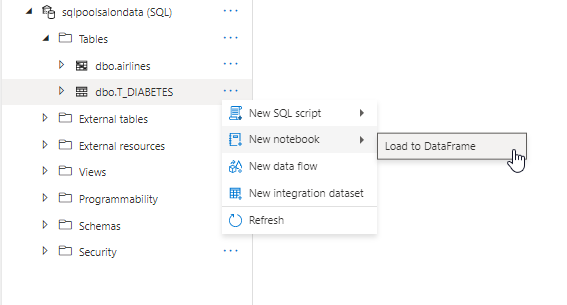
La méthode spark.read.synapsesql() est mise à profit pour créer un Spark Dataframe en mémoire. Attention, il s’agit d’une commande Scala.
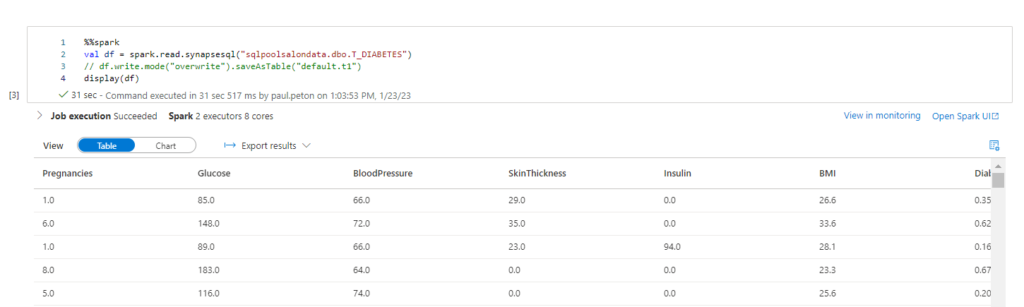
Cette ressource de formation donne également un exemple d’écriture d’un dataframe vers la base de données.
Pour utiliser au mieux Spark et l’API pyspark, je vous recommande la certification Apache Spark developer associate, décrite dans cet article.
Voici un schéma récapitulatif des commandes disponibles avec la librairie MSSparkUtilities.