
La stratégie “Lakehouse” de Databricks vise à fusionner les usages du Data Lake (stockage de fichiers) et du Data Warehouse (modélisation de données dans un but analytique). Il semble donc évident de trouver des connecteurs vers les principaux outils de Business Intelligence Self Service dans la partie “SQL” de l’espace de travail Databricks.
Nous allons détailler ici le processus de création de dataset et de mise à jour pour Power BI. Mais avant tout, résumons en quoi consiste la fonctionnalité “SQL” de Databricks.
Le constat est fait qu’aujourd’hui (comme depuis plus de 30 ans…), le langage SQL reste majoritairement utilisé pour travailler les données, en particulier pour effectuer des opérations de transformations, d’agrégats ou encore de fusions. Nous pouvions d’ores et déjà utiliser des notebooks Databricks s’appuyant sur l’API Spark SQL et définir des tables ou des vues dans le metastore Hive associé à un cluster (tables visibles uniquement lorsque le cluster est démarré).
Nous pouvons créer une table à partir de la syntaxe suivante, en s’appuyant sur des fichiers de type CSV, parquet ou encore Delta :
CREATE TABLE diamonds USING CSV LOCATION '/databricks-datasets/Rdatasets/data-001/csv/ggplot2/diamonds.csv' options (header = true, inferSchema = true)
La requête est exécutée par un “SQL endpoint” qui n’est autre qu’un cluster de machines virtuelles du fournisseur Cloud (ici le cloud Azure de Microsoft).
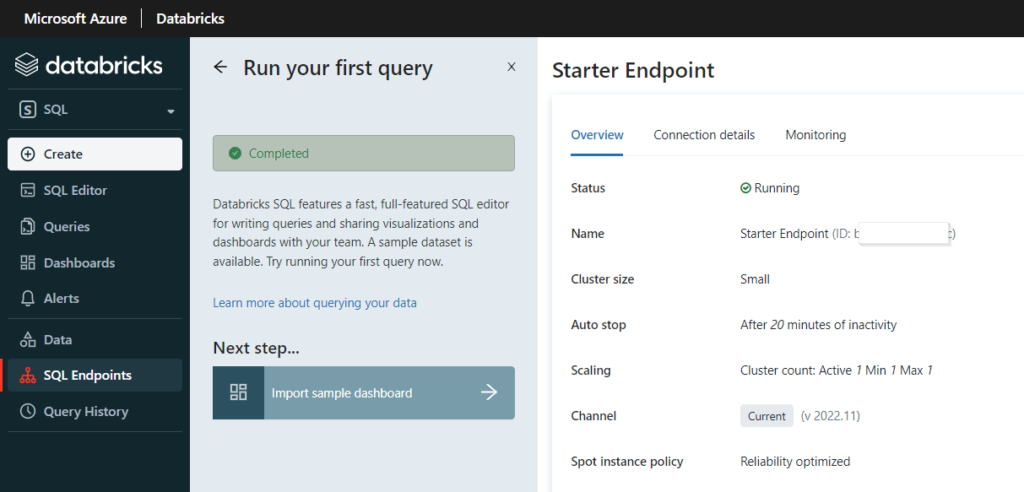
Différentes tailles prédéfinies de clusters sont disponibles et correspondent à des niveaux de facturation exprimés en Databricks Units (DBU).

A termes, nous espérons profiter d’une capacité “serverless” qui serait mise à disposition par l’éditeur, conjointement au fournisseur de cloud public.
La table précédemment créée est ensuite “requêtable” au moyen des syntaxes SQL traditionnelles.
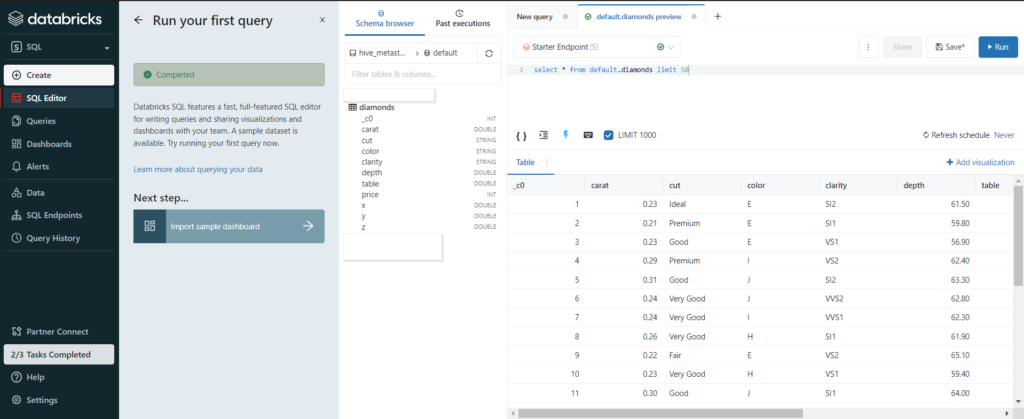
Il serait alors possible de créer un dashboard dans l’interface Databricks mais nous allons profiter de la puissance d’un outil comme Power BI pour exploiter visuellement les données.
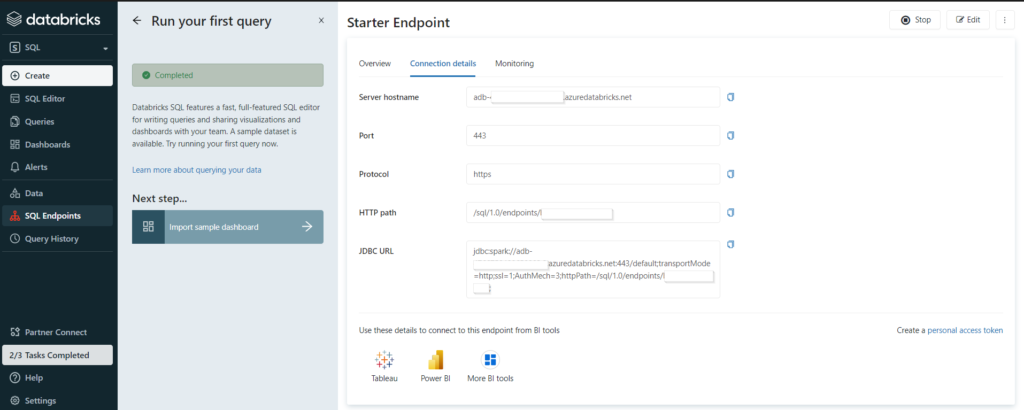
Nous récupérons donc les informations de connexion au SQL endpoint avant de lancer le client Power BI Desktop.
Databricks SQL endpoint comme source de données
Nous recherchons Azure Databricks dans les sources de données de Power BI Desktop.
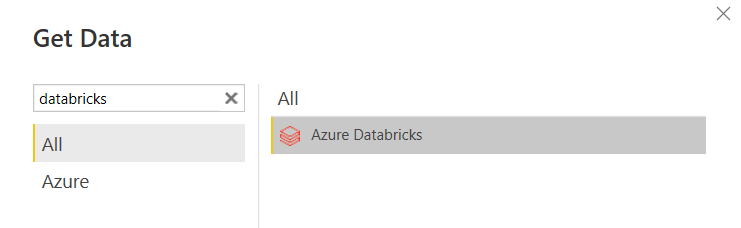
Nous retrouvons ici les informations décrivant le SQL endpoint :
- server hostname : l’URL (sans htpps) de l’espace de travail Databricks
- HTTP path
- le catalogue (par défaut hive_metastore)
- le database (ou schéma)
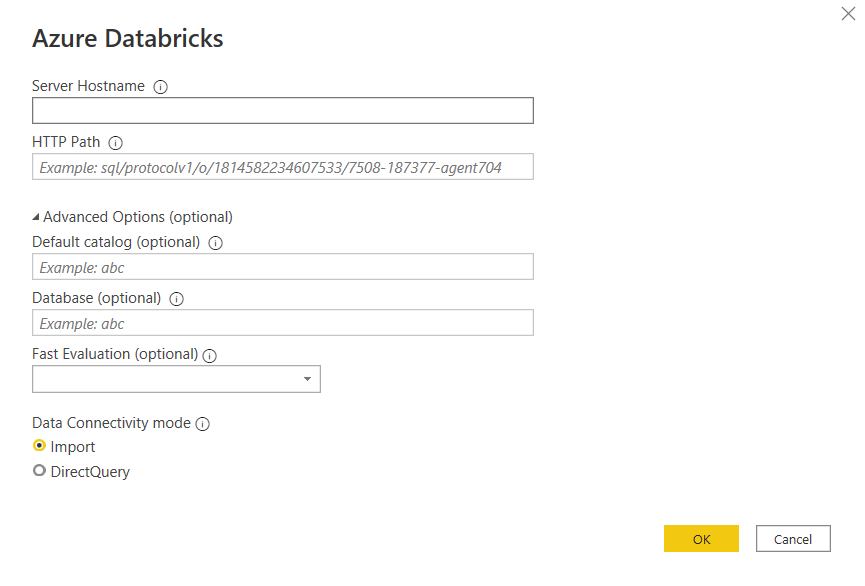
A noter que les deux modes de connexion de Power BI sont disponibles : import et DirectQuery. Pour ce dernier, il faudra prendre en compte le nécessaire “réveil” du SQL endpoint lors de la première requête. Quelques minutes peuvent être nécessaires.
Précisions qu’il est possible de créer un catalogue autre que celui par défaut (hive_metastore) et il serait alors pertinent de rédiriger le stockage des métadonnées vers une partie du Data Lake ou vers un compte de stockage dédié, comme expliqué dans cet article.
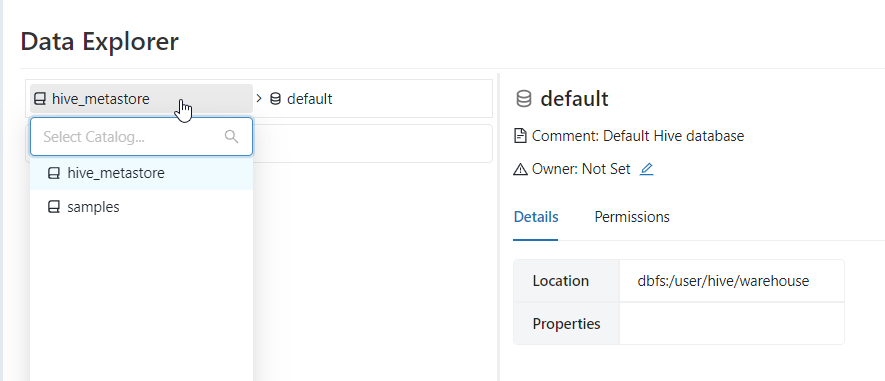
Pour voir les données du metastore, il faudra choisir une méthode d’authentification parmi les trois disponibles.
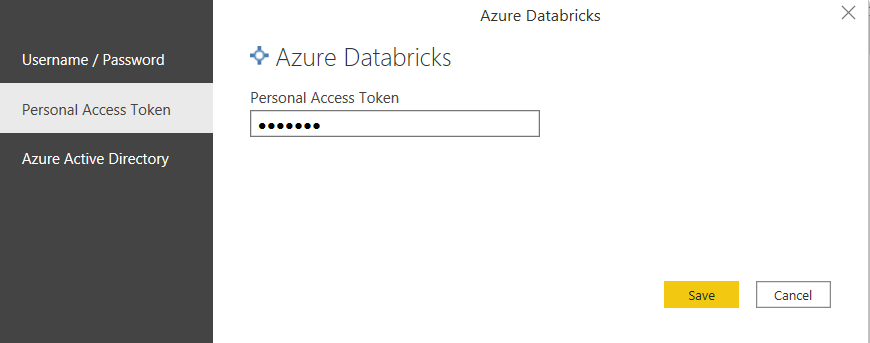
Le jeton d’accès personnel (Personal Access Token) semble simplifier les choses mais attention, sa validité est lié au compte qui l’a généré. Un utilisateur retiré de l’espace Databricks disparaît avec ses jetons ! Le périmètre associé à un PAT est très large : utilisation du CLI et de l’API Databricks, accès aux secret scopes, etc.
Nous allons donc préférer la connexion au travers de l’annuaire Azure Active Directory.
Pour gagner du temps, nous pouvons télécharger un fichier au format .pbids qui est un fichier contenant déjà les informations de connexion renseignées.

La vue des tables disponibles s’ouvre alors directement si nous disposons déjà d’une authentification définie dans notre client Power BI Desktop.
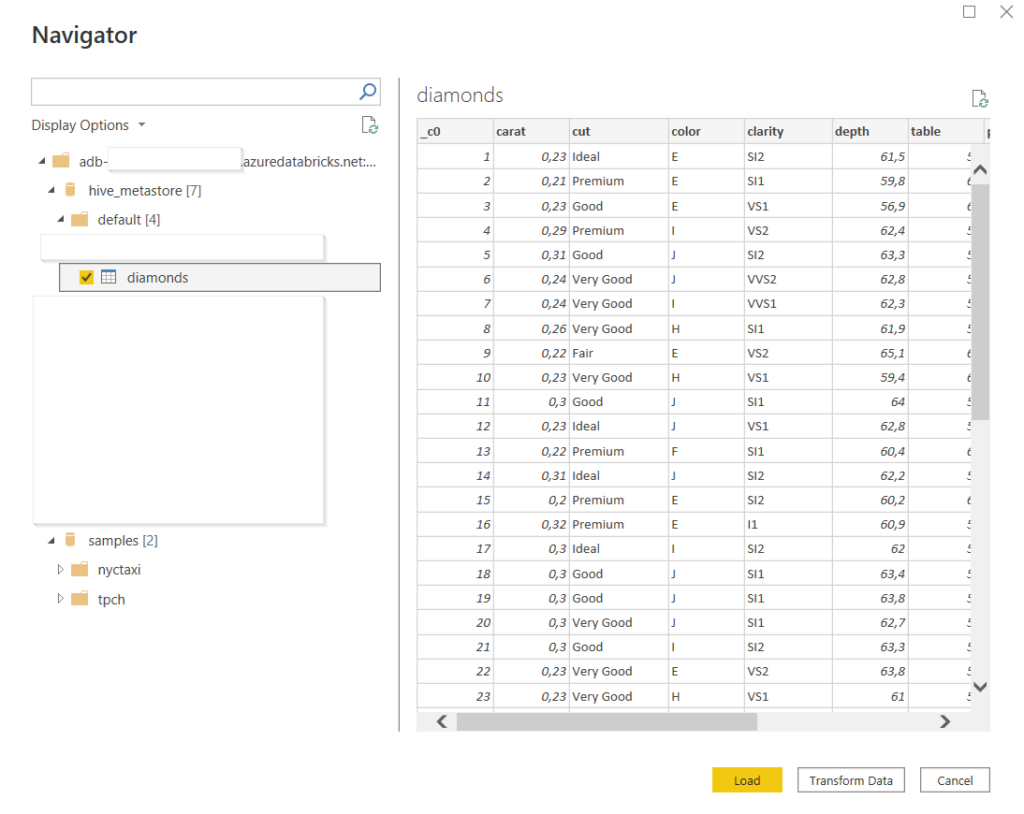
C’est alors une connexion de type DirectQuery qui est réalisée. Il sera possible de basculer en mode import en cliquant sur le message en bas à droite du client desktop.
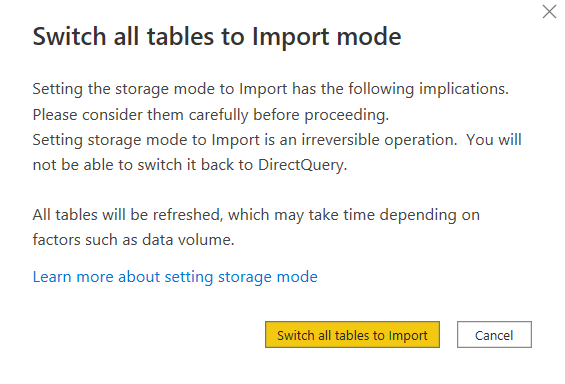
En ouvrant l’éditeur de requêtes Power Query, nous pouvons voir la syntaxe utilisée pour définir la connexion.
let
Source = Databricks.Catalogs("adb-xxx.x.azuredatabricks.net", "/sql/1.0/endpoints/xxx", []),
hive_metastore_Database = Source{[Name="hive_metastore",Kind="Database"]}[Data],
default_Schema = hive_metastore_Database{[Name="default",Kind="Schema"]}[Data],
diamonds_Table = default_Schema{[Name="diamonds",Kind="Table"]}[Data]
in
diamonds_Table
La fonction Databricks.Catalogs peut être remplacée par la fonction Databricks.Query qui permet alors de saisir directement une requête SQL dans l’éditeur.
Planifier une actualisation du dataset
Une fois le rapport publié sur l’espace de travail Databricks, nous allons pouvoir actualiser directement les données, sans passer par le client desktop. Nous nous rendons pour cela dans les paramètres du dataset, au niveau des informations d’identification.
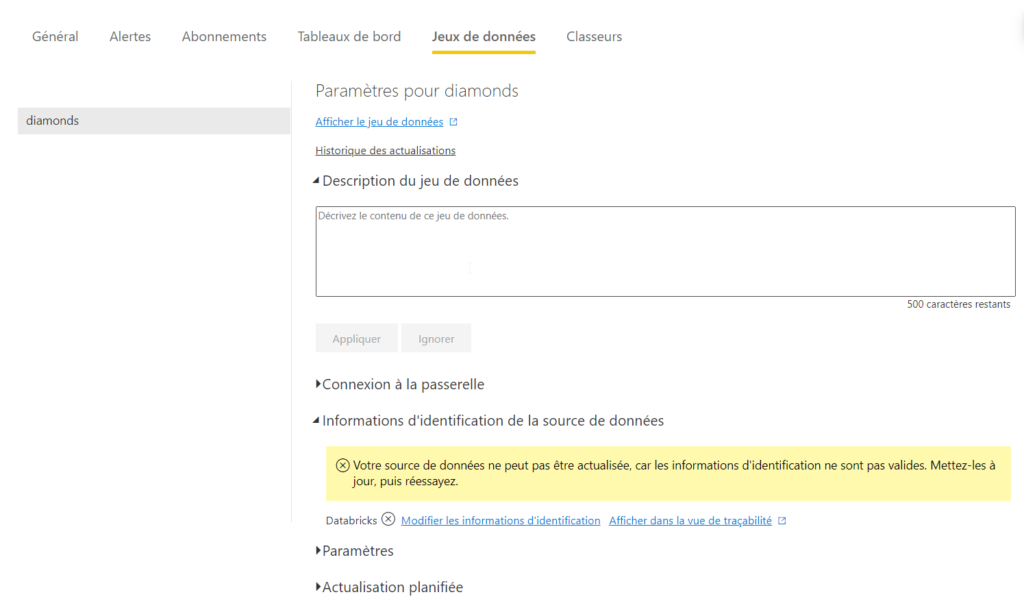
Nous devons ici redonner les informations de connexion. Nous en profitons pour préciser le niveau de confidentialité des données.
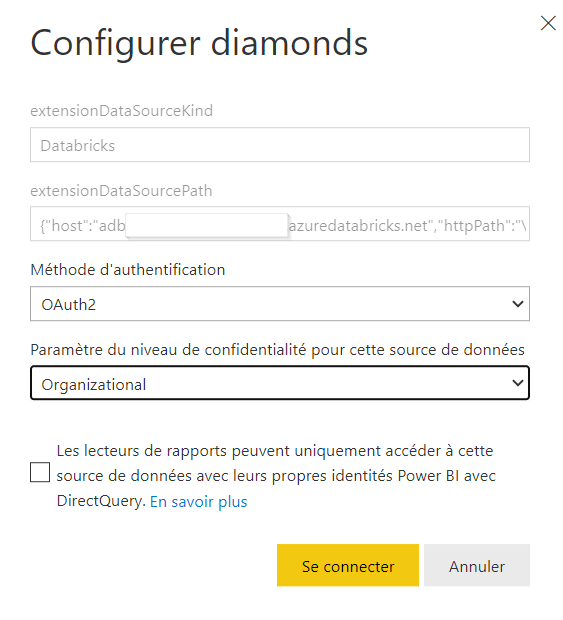
Dans le cas d’une connexion de type DirectQuery, nous pouvons demander à ce que l’identité de l’AAD des personnes en consultation soit utilisée. Cela permet de sécuriser l’accès aux données mais à l’inverse, il sera nécessaire que ces personnes soient déclarées dans l’espace de travail Databricks.
En conclusion, le endpoint SQL de Databricks est une approche intéressante pour éviter le coût d’un serveur de base de données dans une architecture décisionnelle. Il sera pertinent de préparer au maximum les données dans le metastore Hive pour profiter pleinement de la puissance de l’API Spark SQL et du cluster de calcul. Le petit avantage du SQL endpoint sur la connexion directe à un cluster Databricks (voir cet article) consiste dans la séparation des tâches entre clusters :
- interactive cluster pour les travaux quotidiens d’exploration et de modélisation des Data Scientists
- job cluster pour les traitements planifiés, de type batch
- SQL endpoint pour la mise à disposition des données vers un outil de visualisation