
Derrière ces trois notions, se cache une succession d’étapes nécessaires pour obtenir un service prédictif de qualité et apte à gérer des données qui ne sont pas uniquement numériques.
Prenons l’exemple du classique jeu de données German Credit disponible sur ce lien, sur lequel nous nous baserons pour entrainer un modèle d’apprentissage supervisé, dans une tâche de classification binaire (risque ou absence de risque sur le non remboursement d’un emprunt bancaire). Pour le déploiement d’un service web prédictif, nous allons utiliser le service Azure Machine Learning avec lequel nous interagirons au travers du SDK Python azureml-core, souvent évoqué sur ce blog (ici et là).
Même si leur champ de compétences grandit de jour en jour, les Data Scientists et Data Engineers ne sont pas attendus sur le développement de l’application finale qui offrira par exemple une interface de saisie et intègrera la restitution des prévisions. Pour autant, il est nécessaire de “passer la main” à une équipe de développeurs en fournissant une documentation claire et précise pour des personnes qui n’ont pas à se pencher sur des notions de feature selection ou encore feature engineering. Cette documentation s’établit communément sous le format dit Swagger qui correspond à un fichier JSON listant les colonnes en entrée du modèle ainsi que le type de données associé (texte, nombres entiers ou décimaux, dates voire fichier binaire dans un cas non structuré).
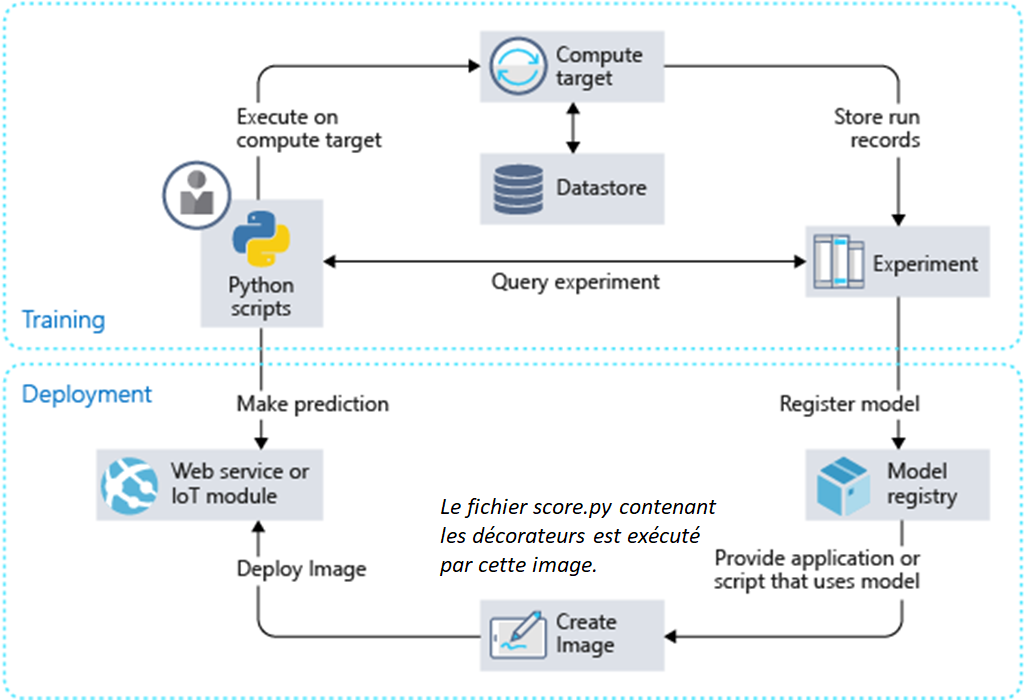
Afin d’obtenir ce résultat, nous devons préciser deux éléments dans la fonction de scoring qui supporte l’inférence du modèle. Rappelons que cette fonction Python score.py est ensuite hébergée sur une image Docker, stockée dans une ressource Azure Container Registry et exposée à l’aide d’Azure Container Instance ou Azure Kubernetes Services.
Nous disposerons alors de deux URLs, dont la propriété dns_name_label aura été précisée dans la définition de l’appel à la fonction deploy_configuration() sur l’objet AciWebservice :
- celle du point de terminaison:
http://german-credit-classification.westeurope.azurecontainer.io/score
- celle de la documentation Swagger :
http://german-credit-classification.westeurope.azurecontainer.io/swagger.json
Le fichier score.py se compose de deux fonctions au nom réservé :
- init() qui récupère le binaire du modèle (par exemple au format Pickle) et le désérialise en mémoire
- run(input) : qui récupère les données en entrée et applique la fonction .predict sur le modèle
def init():
global model
global encoder
# The AZUREML_MODEL_DIR environment variable indicates
# a directory containing the model file you registered.
model_filename = 'german_credit_log_model.pkl'
model_path = os.path.join(os.environ['AZUREML_MODEL_DIR'], model_filename)
with open(model_path, 'rb') as f:
encoder, model = joblib.load(f)
Pour garantir la cohérence des données en entrée (nombre de colonnes et type des données) ainsi qu’en sortie, nous allons définir deux objets appelés décorateurs. Ces objets Python servent à modifier le comportement d’une fonction existante. Cette page GitHub documente ce que Microsoft appelle l’InferenceSchema.
A partir du SDK Python, nous allons commencer par importer les éléments nécessaires à la création des décorateurs.
from inference_schema.schema_decorators import input_schema, output_schema from inference_schema.parameter_types.standard_py_parameter_type import StandardPythonParameterType from inference_schema.parameter_types.numpy_parameter_type import NumpyParameterType from inference_schema.parameter_types.pandas_parameter_type import PandasParameterType
Nous disposons de trois types pour ces décorateurs :
- le type standard que nous utiliserons pour une valeur simple comme par exemple un paramètre en entrée ou une valeur en sortie
- le type Numpy Array soit un tableau de nombres en entrée (les features sont alors uniquement numériques) ou un tableau de valeurs en sortie (une prévision numérique pour une régression mais pourquoi pas un tableau de probabilités associées à chaque classe pour une classification)
- le type Pandas Dataframe qui permet de faire entrer un jeu de données de multiples types, ce qui est bien plus souvent le cas dans la vraie vie que dans les tutoriels visibles sur le Web !
Voici la définition des décorateurs en entrée et sortie pour une tâche de classification sur le jeu de données German Credit. Il faut veiller à donner un exemple respectant le type de données de chaque colonne. Pour obtenir facilement ces informations, je vous recommande de lancer la commande df.iloc[:,1] sur le dataframe.
input_sample = pd.DataFrame(data=[{
"Status of existing checking account": "A12",
"Duration in month": 48,
"Credit history": "A32",
"Purpose": "A43",
"Credit amount": 5951,
"Savings account/bonds": "A61",
"Present employment since": "A73",
"Installment rate in percentage of disposable income": 2,
"Personal status and sex": "A92",
"Other debtors / guarantors": "A101",
"Present residence since": 2,
"Property": "A121",
"Age in years": 22,
"Other installment plans": "A143",
"Housing": "A152",
"Number of existing credits at this bank": 1,
"Job": "A173",
"Number of people being liable to provide maintenance for": 1,
"Telephone": "A191",
"foreign worker": "A201",
}])
output_sample = np.array([0])
@input_schema('data', PandasParameterType(input_sample))
@output_schema(NumpyParameterType(output_sample))
La méthode .predict() de Scikit-Learn accepte en entrée soit un tableau Numpy soit un Pandas dataframe. Nous n’aurons donc pas à intervenir sur le script score.py, le décorateur fera le travail d’interprétation des données en entrée et en particulier associera le nom des colonnes pour un Pandas dataframe.
Jetons un oeil du côté de la syntaxe classique d’appel au service web prédictif, ici en Python mais cet appel peut se faire dans de multiples langages. La seule contrainte est de passer les données dans un format JSON.
def run(data):
print(data.shape)
df_text = data.select_dtypes(include='object')
df_num = data.select_dtypes(include='int64')
df_text_encoded = pd.DataFrame(encoder.transform(df_text).toarray())
df_encoded = pd.concat([df_num, df_text_encoded], axis=1)
# Use the model object loaded by init().
result = model.predict(df_encoded)
# You can return any JSON-serializable object.
return result.tolist()Explorons maintenant le détail du code de la fonction run(). Celle-ci attend un paramètre en entrée et il est important de respecter le nom associé au Dataframe dans sa définition faite au sein du décorateur d’entrée (la casse également, attention aux majuscules et minuscules !).
La première étape consiste à lire le JSON en entrée grâce à la fonction json.loads(). N’oubliez pas de faire un import json dans le début du script ainsi que de charger la librairie pandas dans l’environnement d’inférence.
Nous passons ensuite un traitement spécifique aux colonnes de type texte, qui était lui-même stocké dans le fichier pickle.
Il n’y a plus qu’à demander la prédiction à partir du modèle avec l’instruction model.predict(data) puis à restituer le résultat en convertissant le Numpy array en liste, objet dit “JSON-serializable”.
Modification de la méthode de prévision
Puisque nous travaillons sur une classification binaire, nous pourrions préférer appliquer au modèle la méthode predict_proba() et
Voici le nouveau code à positionner dans la fonction score.py.
pandas_sample_input = pd.DataFrame(data=[{
"Status of existing checking account": "A12",
"Duration in month": 48,
"Credit history": "A32",
"Purpose": "A43",
"Credit amount": 5951,
"Savings account/bonds": "A61",
"Present employment since": "A73",
"Installment rate in percentage of disposable income": 2,
"Personal status and sex": "A92",
"Other debtors / guarantors": "A101",
"Present residence since": 2,
"Property": "A121",
"Age in years": 22,
"Other installment plans": "A143",
"Housing": "A152",
"Number of existing credits at this bank": 1,
"Job": "A173",
"Number of people being liable to provide maintenance for": 1,
"Telephone": "A191",
"foreign worker": "A201",
}])
method_sample_input = "predict"
output_sample = np.array([0])
@input_schema('data', PandasParameterType(pandas_sample_input))
@input_schema('method', StandardPythonParameterType(method_sample_input))
@output_schema(NumpyParameterType(output_sample))
def run(data, method):
df_text = data.select_dtypes(include='object')
df_num = data.select_dtypes(include='int64')
df_text_encoded = pd.DataFrame(encoder.transform(df_text).toarray())
df_encoded = pd.concat([df_num, df_text_encoded], axis=1)
print(method)
# Use the model object loaded by init().
result = model.predict(df_encoded) if method=="predict" else model.predict_proba(df_encoded)
# You can return any JSON-serializable object.
return result.tolist()Nous exploitons ici deux paramètres en entrée de la fonction run(). Le second est du type StandardPythonParameterType, c’est-à-dire tout simplement une chaîne de texte ! Ensuite, nous jouons avec une condition pour appliquer soit predict(), soit predict_proba() qui renverra alors les probabilités appliquées à chacune des deux classes :
[[0.27303021717776266, 0.7269697828222373]]
En conclusion
Voilà un fonctionnement qui est satisfaisant autant pour les développeurs du modèle et du service que pour les personnes qui l’exploiteront ensuite. Attention toutefois à ne pas oublier de venir modifier ces décorateurs si jamais votre modèle n’utilise plus les mêmes données en entrée. Il est recommandé de rester à l’identique de la donnée de départ et si une étape de préparation (feature engineering, scaling…) est nécessaire, il faudra l’inclure dans un pipeline, ce que nous verrons dans un prochain article.
Le notebook complet sera disponible dans ce repository.