
Développer un rapport Power BI peut-il s’apparenter à un développement « classique » au sens du code ? Pas entièrement sans doute mais des bonnes pratiques sont à mettre en œuvre et la documentation en fait sans nul doute partie.
Pourtant, car comme nous savons tous que ce n’est pas l’aspect le plus intéressant d’un développement, nous souhaiterons le faire :
- Sans y passer trop de temps et de la manière la plus automatisée possible
- En produisant un contenu utile pour un autre développeur qui n’aurait pas connaissance du projet initial
- En sécurisant et versionnant les contenus les plus précieux (M, DAX)
En effet, nous ne sommes jamais à l’abri d’une corruption de fichier et conserver toute « l’intelligence » du développement permettrait de ne pas tout refaire de zéro.
A faire au cours développement
Les pratiques qui seront présentées ici visent bien sûr à améliorer la qualité du rapport Power BI mais aussi à faciliter la documentation qui pourra être produite par la suite.
Réduire les étapes de transformation
Par exemple, il est possible de “typer“ une nouvelle colonne à la création.
= Table.AddColumn(#"Previous step", "Test approved = 0", each [#"Approved amount (local currency)"] * [Approved quantity] = 0, type logical)
Une bonne approche pour réduire les étapes consiste à privilégier les transformations réalisées au niveau de la source de données, par exemple en langage SQL.
Nommer certaines étapes de transformation
Les étapes d’une requête Power Query peuvent être renommées. Il est recommandé de privilégier le nommage automatique en anglais et de préciser certaines étapes.
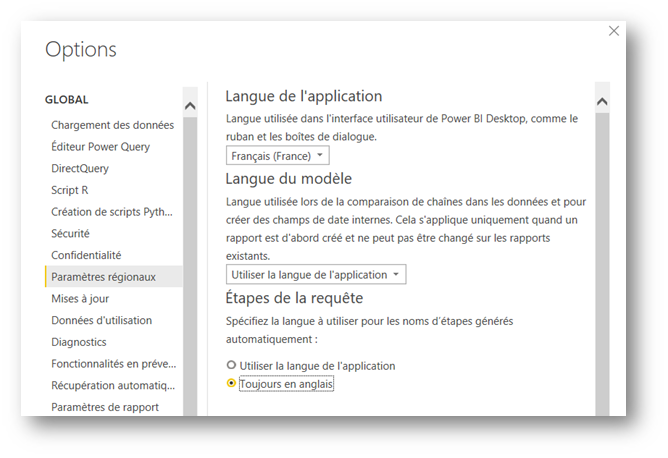
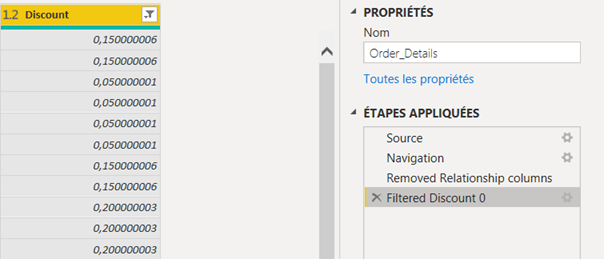
Du point de vue de la relecture du script, il n’est pas optimal de disposer de plusieurs étapes similaires (par exemple : Change Type ou Renamed Columns) mais cela est parfois inévitable comme pour l’action Replaced Value. On précisera ainsi la valeur remplacée par cette étape. De même pour des opérations comme Added Custom, Merge Queries, Filtered Rows, etc.
Ajouter si besoin une description plus détaillée au moyen d’un commentaire dans le script M entre /*…*/ ou sur une seule ligne à l’aide de //.
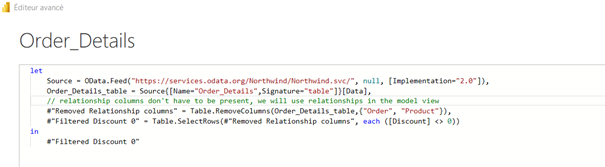
Comme dans tout développement, un commentaire vient expliquer la logique adoptée par le développeur lorsque celle-ci est plus complexe que l’usage nominal de la formule.
Déterminer la bonne stratégie de filtres
Il y a tellement d’endroits où l’on peut filtrer les données lors d’un développement Power BI ! Dans une ordre « chronologique » au sens des phases de développement, nous pouvons identifier :
- La requête vers la source (par exemple avec une clause WHERE dans un script SQL)
- Une étape de transformation Power Query
- Un contexte dans une mesure DAX avec des fonctions comme CALCULATE() ou FILTER()
- Un rôle de sécurité
- Le volet de filtre latéral :
- Au niveau du rapport
- Au niveau de la page
- Au niveau du visuel
D’emblée, précisons tout de suite que si vous êtes tentés par les filtres de rapport, c’est très vraisemblablement une mauvaise idée et il était sûrement possible de le faire dans une étape précédente ! Une règle (non absolue) est de réaliser l’opération le plus tôt possible, dans la liste précédente.
Ainsi, on privilégiera la requête SQL, ou le query folding, qui délégueront toute la préparation de données au serveur, qui sera vraisemblablement plus puissant que le service Power BI.
Appliquer une nomenclature aux noms de tables, champs et mesures
Il n’est pas pertinent de préfixer les noms de tables par DIM_ ou FACT_, ceci étant des notions propres aux développeurs décisionnels mais ne parlant pas aux utilisateurs métiers.
Les noms de tables peuvent comporter des espaces, accents ou caractères spéciaux mais l’usage de ces caractères complexifiera l’utilisation de l’auto-complétion des formules. L’utilisation d’émoticônes peut entrainer une corruption du fichier.
Il vaut mieux utiliser des noms de tables courts pour limiter la taille du volet latéral Fields.
Les noms des champs et des mesures doivent être parlants pour un être humain, on bannira donc les _ ou l’écriture CamelCase.
Il est possible d’utiliser des symboles tels que % ou ∑ pour donner une information sur le calcul réalisé.
Afin de profiter de l’écriture dynamique des titres, les mesures peuvent être écrites avec une majuscule et les autres noms de champs en minuscules uniquement. Cela donnera par exemple : « Nb commandes par catégorie » à partir d’une mesure « Nb commandes » et d’un champ nommé « catégorie ».
Mettre en place une stratégie d’imbrication de mesures
Il est recommandé de produire des mesures avancées en se basant sur des mesures simples (et toujours explicites !), quitte à masquer celles-ci.
Par exemple :
# ventes = COUNTROWS(VENTES)
# ventes en ligne = CALCULATE([# ventes], VENTES[Canal] = "en ligne")
Les mesures appelées dans une autre mesure ne seront pas préfixées par un nome de table à l’inverse des noms de colonnes.
Décrire les mesures
La description fonctionnelle des mesures se fait (et ce n’est pas très intuitif…) dans l’affichage de modèle.
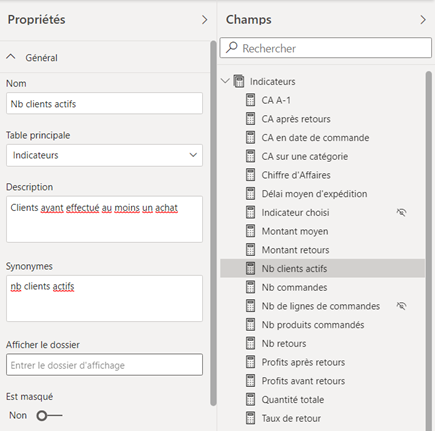
Cet affichage permet également de regrouper les mesures (d’une même table uniquement) dans un dossier ou plusieurs dossiers (« display folder »).
Nous utiliserons ici la propriété « is hidden » pour masquer les colonnes qui ne sont pas utiles à un utilisateur : identifiants, clés techniques, valeurs numériques reprises dans des mesures explicites.
Commenter les formules DAX
Comme dans tout langage de programmation, le commentaire ne doit intervenir que lorsque la stratégie mise en place par le code n’est pas intuitive.
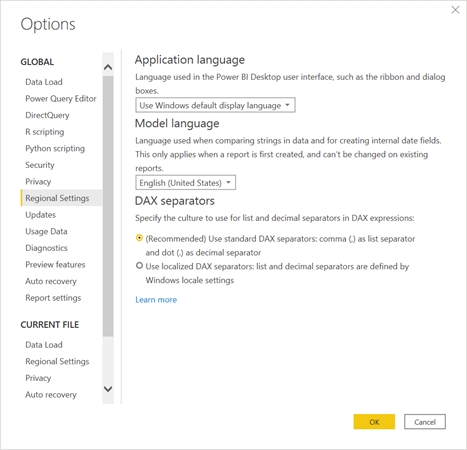
Il est recommandé d’utiliser les séparateurs virgule (paramètres) et point (décimales) dans les formules DAX. Ceci est paramétrable dans les options globales.
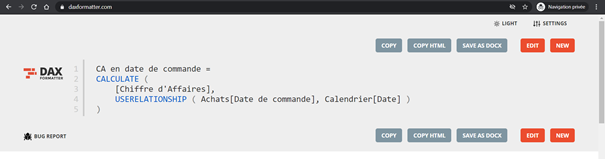
Penser également à mettre en forme systématiquement les champs DAX à l’aide de l’outil en ligne DAX formatter.
Nommer les composants visuels
Pour nommer un composant, on utilise le champ « Title », que celui-ci soit activé ou désactivé. C’est pourquoi il faut activer le titre pour le renseigner, quitte ensuite à le désactiver. Les objets peuvent donc avoir un nom qui est un titre utilisé de manière visuelle.

Le nom de l’objet est ensuite visible dans le volet de sélection.
Les objets ont un identifiant et un nom qui sont utilisés dans les fichiers JSON constituant le contenu du fichier .pbix.
Documenter à l’aide d’outils externes
Nous allons mettre en place une approche pragmatique, à partir d’outils tiers, qui ne sont ni développés ni maintenus par Microsoft mais intégrés maintenant au sein du menu « External Tools ».
Suite à l’installation de ces outils, des raccourcis seront disponibles dans le nouveau menu.

Les différents exécutables sont simples à trouver au travers d’un moteur de recherche.
Power BI Helper
Nous utilisons ici la version de décembre 2020.
Ouvrir le rapport dans Power BI Desktop.
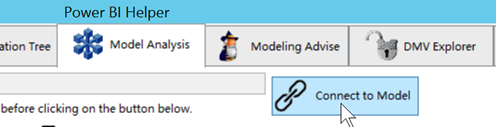
Lancer Power BI Helper. Depuis l’onglet Model Analysis, cliquer sur Connect to Model.
Le nom du fichier doit apparaître dans la liste déroulante « Choose the Power BI file ».
Créer le fichier HTML en cliquant sur « export to document » ou aller sur l’onglet « Document » du menu horizontal.
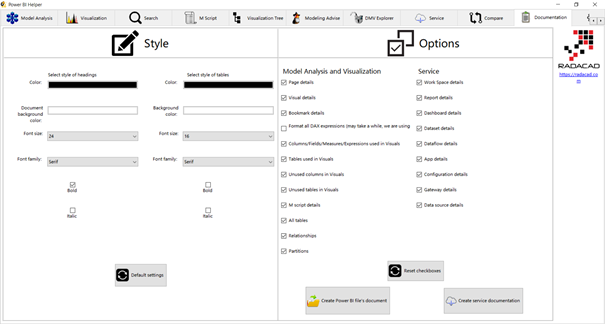
Choisir les éléments voulus dans la liste « Model Analysis and Visualisation » puis cliquer sur « Create Power BI file’s document ». Nous obtenons un fichier au format .htm contenant des tableaux.

Voici pourquoi il est important de renseigner la description dans le rapport Power BI.
Tiens, pourquoi pas brancher un Power BI sur ce fichier HTML et ainsi charger les tableaux dans un « méta-rapport » ?
Le code M est visible dans l’onglet du menu « M script ».
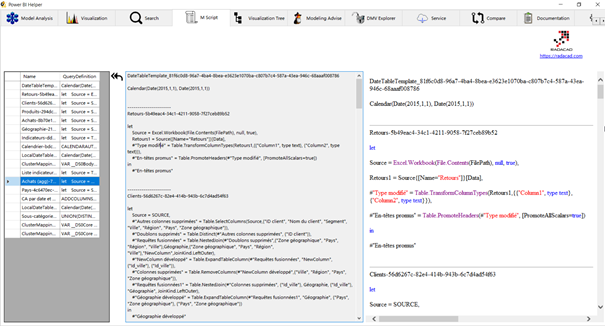
Le bouton d’export semble avoir disparu mais il est possible de faire un simple copier-coller de la zone de texte grisée.
Sans même utiliser un outil externe, il était déjà possible de copier une requête dans l’éditeur (clic droit, copier), puis de coller dans un bloc-notes pour obtenir le script, qu’on enregistre par convention dans un fichier d’extension .M.
Power BI Field Finder
Télécharger la dernière version du modèle .pbit depuis le dépôt GitHub : https://github.com/stephbruno/Power-BI-Field-Finder
Ouvrir le modèle .pbit et renseigner comme valeur de paramètre le chemin du fichier .pbix que l’on souhaite documenter.
Les données vont se mettre à jour et il sera possible d’enregistrer le rapport au format .pbix, puis de le mettre à jour en cas de modification dans le fichier d’origine.
Je tiens à signaler que je suis vraiment bluffé par la qualité de cet outil qui rend d’immenses services au quotidien. Bravo, Stéphanie BRUNO ! L’outil est présenté plus en détail sur ce site.
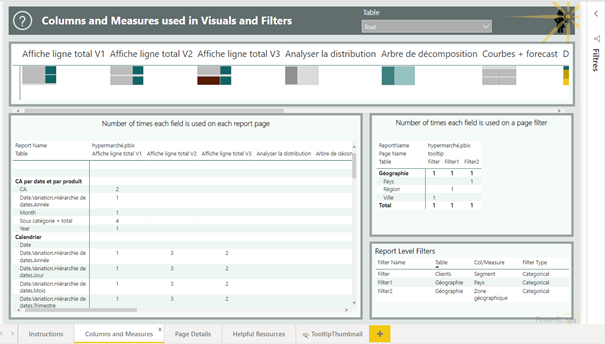
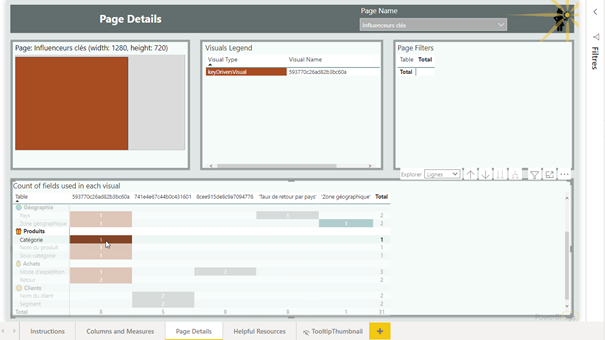
Cliquer sur un nom de champ pour identifier la ou les pages où il est utilisé.
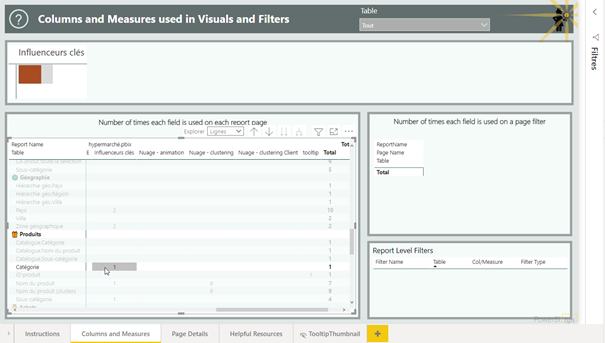
La page détaillée indique ensuite le(s) visuel(s) utilisant ce champ.
DAX Studio
Quelques requêtes permettent de synthétiser le code DAX écrit dans le fichier .pbix. Conservez-les précieusement, par exemple dans un fichier texte d’extension .dax. Le résultat pourra ensuite être enregistré dans un format CSV ou Excel en paramétrant l’output.
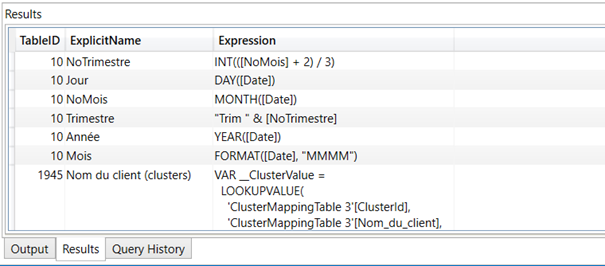
Liste de toutes les colonnes calculées
select TableID, ExplicitName, Expression from $SYSTEM.TMSCHEMA_COLUMNS where [Type] = 2 order by TableID
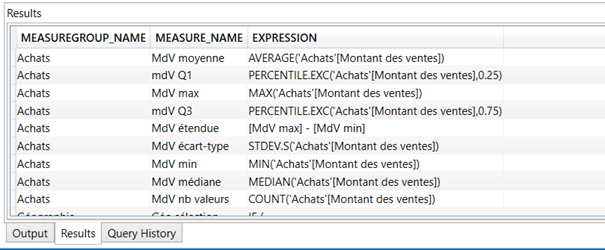
Liste de toutes les mesures
select MEASUREGROUP_NAME, MEASURE_NAME, EXPRESSION from $SYSTEM.MDSCHEMA_MEASURES where MEASURE_AGGREGATOR = 0 order by MEASUREGROUP_NAME
Dépendances entre les formules DAX
Puisque je vous ai encouragés à utiliser les mesures imbriquant d’autres mesures, vous chercherez certainement les dépendances créés. Celles-ci peuvent être obtenues par la requête suivante, où l’on précisera le nom de la mesure entre simples cotes.
Cette démarche est expliquée en détail dans cet article de Chris Webb.
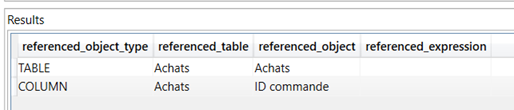
select referenced_object_type, referenced_table, referenced_object, referenced_expression from $system.discover_calc_dependency where [object]='Nom de la mesure'
Ainsi, pour la mesure simple (mais explicite !) ‘Nb commandes’, nous obtenons :
Puis, pour une mesure ‘CA A-1’ basé sur une autre mesure :
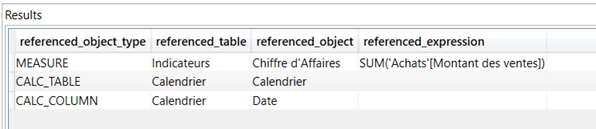
Vous avez quelques belles cartes en main pour créer et maintenir une documentation robuste autour de vos rapports Power BI. Maintenant, à vous de jouer ! Les personnes qui prendront votre relais sur ces développements vous remercient déjà par avance !