
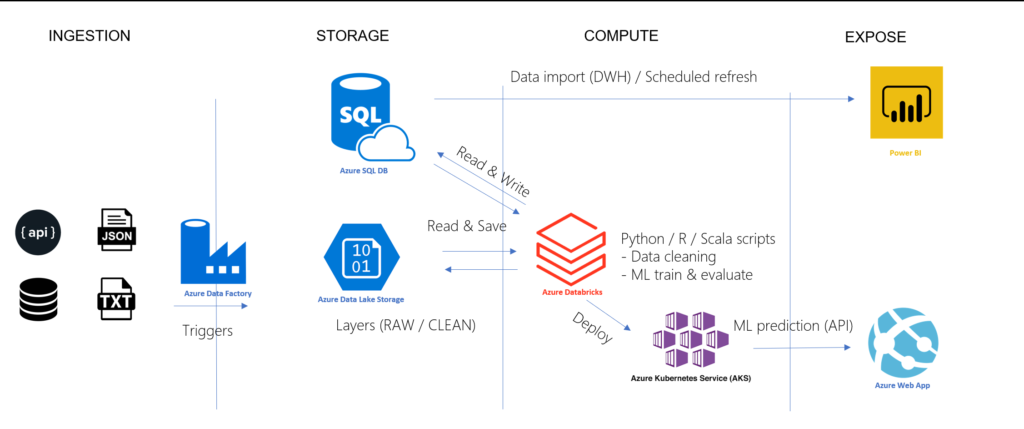
Dans une architecture cloud Azure, la ressource de “compute” Databricks va bien souvent être utilisée pour transformer la donnée brute en donnée dite nettoyée ou enrichie. Cette donnée peut bien sûr être stockée sur un Data Lake, par exemple dans un format Parquet (nous y reviendrons en fin d’article) mais les outils d’exploration et de visualisation de données comme Microsoft Power BI présentent de nombreux avantages à s’appuyer sur une base de données relationnelle (actualisation incrémentielle, DirectQuery…).
Nous partirons ainsi de l’architecture Azure ci-dessous :
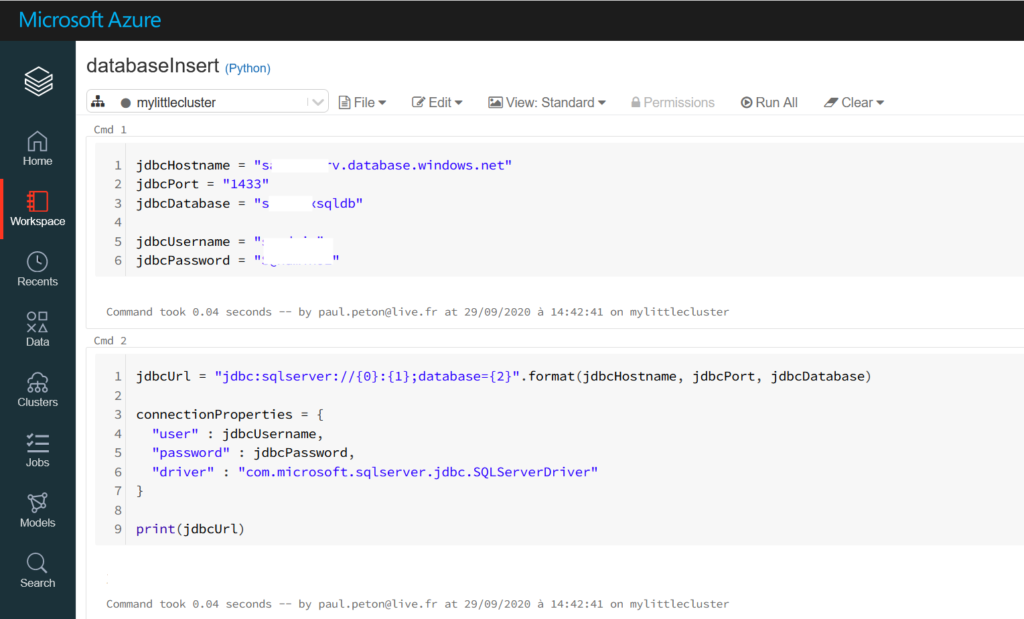
Nous lançons tout d’abord un notebook Python où nous définissons la chaîne de connexion. Il sera bien sûr très judicieux d’utiliser ici le secret scope de Databricks pour stocker toutes ces informations.
Il s’agit maintenant d’écrire un jeu de données nettoyées et travaillées en mémoire sous forme de Spark dataframe dans une table de la base de données. Cette opération se fait tout simplement au moyen de la méthode write associée aux informations de connexion : URL JDBC et propriétés de connexion.
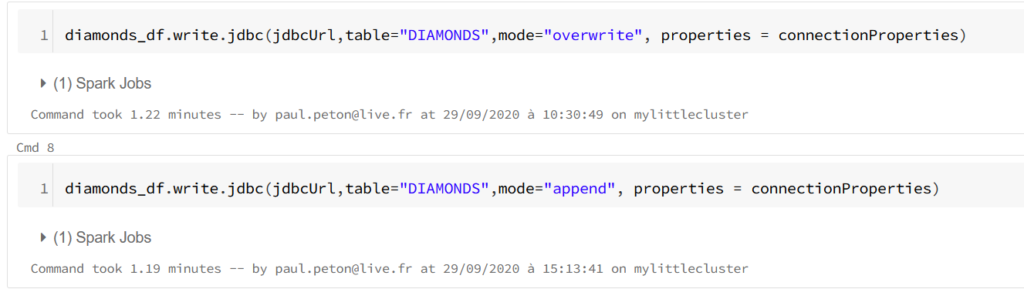
Le paramètre de mode permet de choisir entre un “annule et remplace” de la table au moyen de la valeur overwrite ou une insertion à l’aide du mot clé append.
Il n’y a donc ici pas de mode prévu pour la suppression ou la mise à jour. Il faudra penser ce scénario de manière différente et peut-être au travers du format de fichier Delta, basé sur le format Parquet et sur lequel existent des méthodes delete et upsert. Pour autant, ce fichier restera en dehors de la base de données.
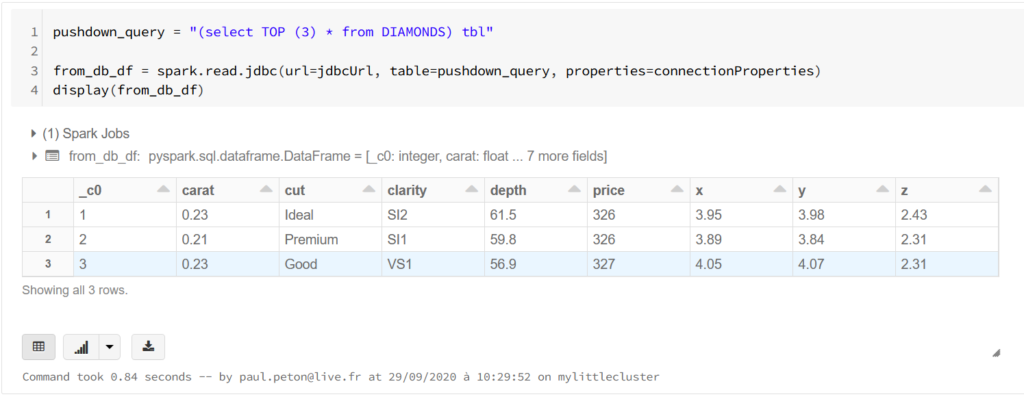
La méthode read de Spark est également possible et se fait en soumettant une requête SQL au travers du driver JDBC. Nous utilisons ici la syntaxe SQL propre à la base de données, ici le Transac-SQL de Microsoft.
Pour aller un peu plus loin dans l’exploitation de ce driver JDBC, nous pouvons créer une table dans le métastore du cluster, copie d’une table de la base de données.
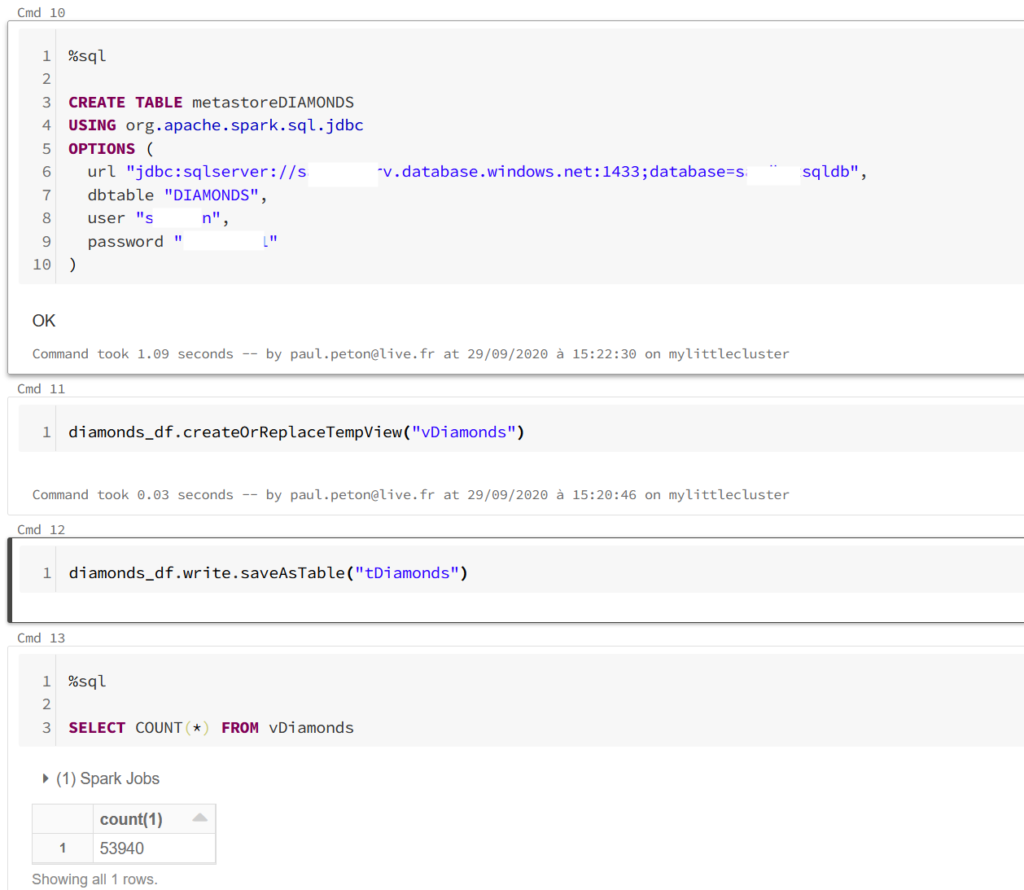
Il est alors possible de créer des interactions en Spark SQL entre des vues créées à partir de dataframes Spark (ou Pandas en les convertissant au préalable) et la table du métastore. Ce scénario ne réalise qu’une lecture des données de la base et des opérations d’écriture sur cette table ne seront bien sûr pas répercutées sur la base de données.
Nous avons ici utilisé le driver JDBC de manière simple avec une ressource de type SQL Database. Vous retrouverez ici une autre manière de procéder au travers de Polybase pour Azure SQL Datawarehouse. Ce service Azure étant maintenant renommé Azure Synapse Analytics et disposant de nouvelles fonctionnalités, de prochains articles décriront les modes d’interaction entre fichiers, dataframes et tables. En attendant, je vous recommande cet épisode du podcast Big Data Hebdo autour de Synapse.