En France, le milieu de la Data Science connaît bien, de réputation au moins, la société Dataïku et son Data Science Studio qui s’est imposé comme l’une des plateformes SaaS les plus performantes du marché. Le cadran Gartner a reconnu la société qui est aujourd’hui implantée à New-York.
Si la plateforme peut être installée sur les serveurs de l’entreprise, il est également possible de l’utiliser, supportée par les ressources du Cloud, en particulier, le cloud Azure de Microsoft.
Utiliser Dataïku DSS au sein d’Azure
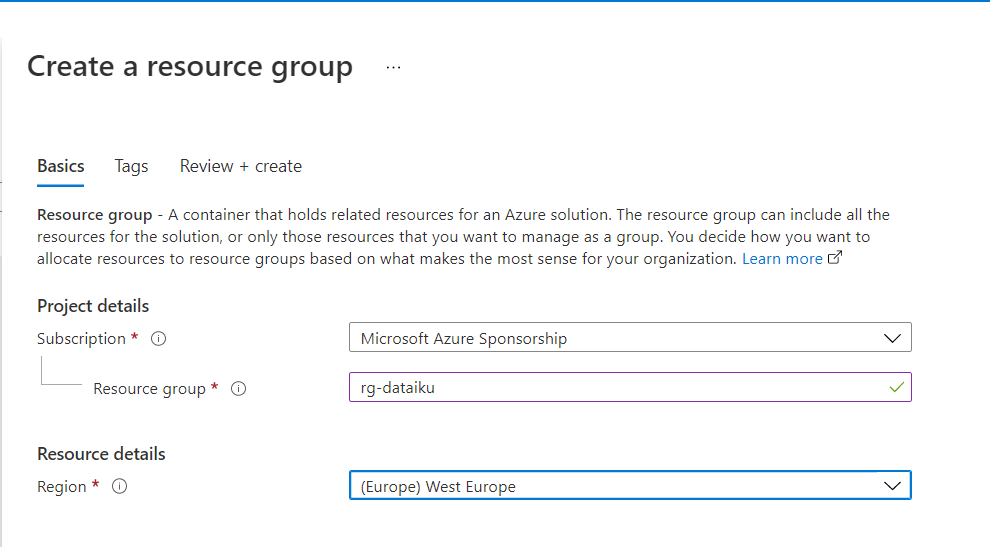
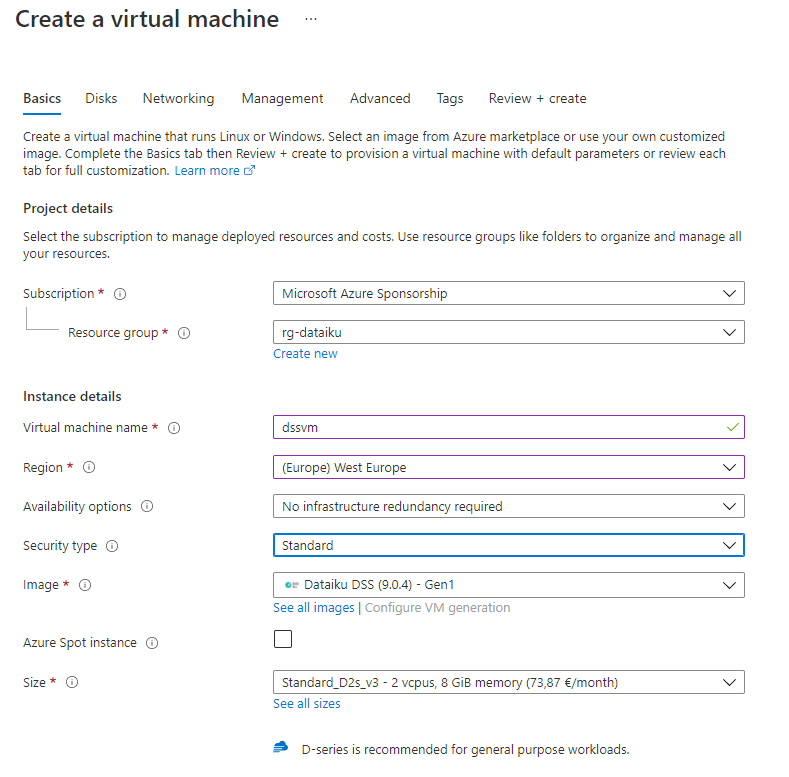
Nous allons commencer par créer un groupe de ressources Azure dédié à Dataïku DSS.
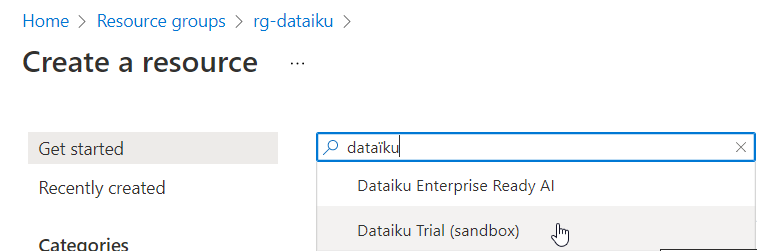
Dans la Market Place Azure, nous trouvons deux entrées :
Dataïku Enterprise Ready AI
Dataïku Trial (sandbox)
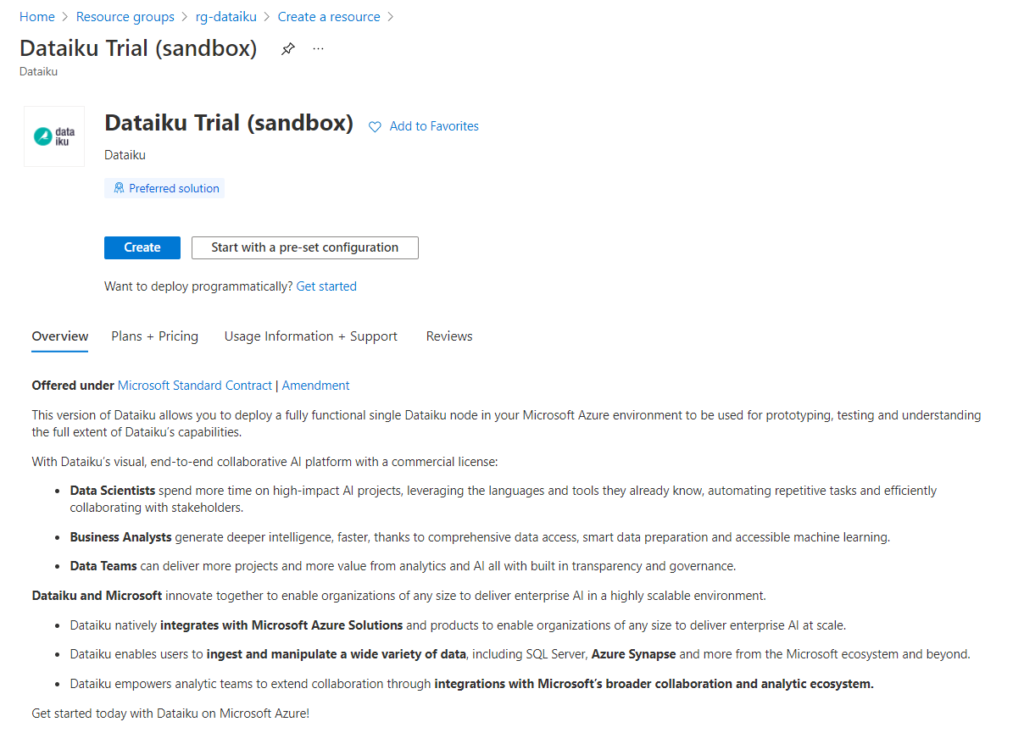
Nous allons commencer par la version “bac à sable” et de prochains articles traiteront de la version Enterprise.
La tarification se fait sur le temps où la machine virtuelle Linux est allumée, et en fonction du type de machine choisie.
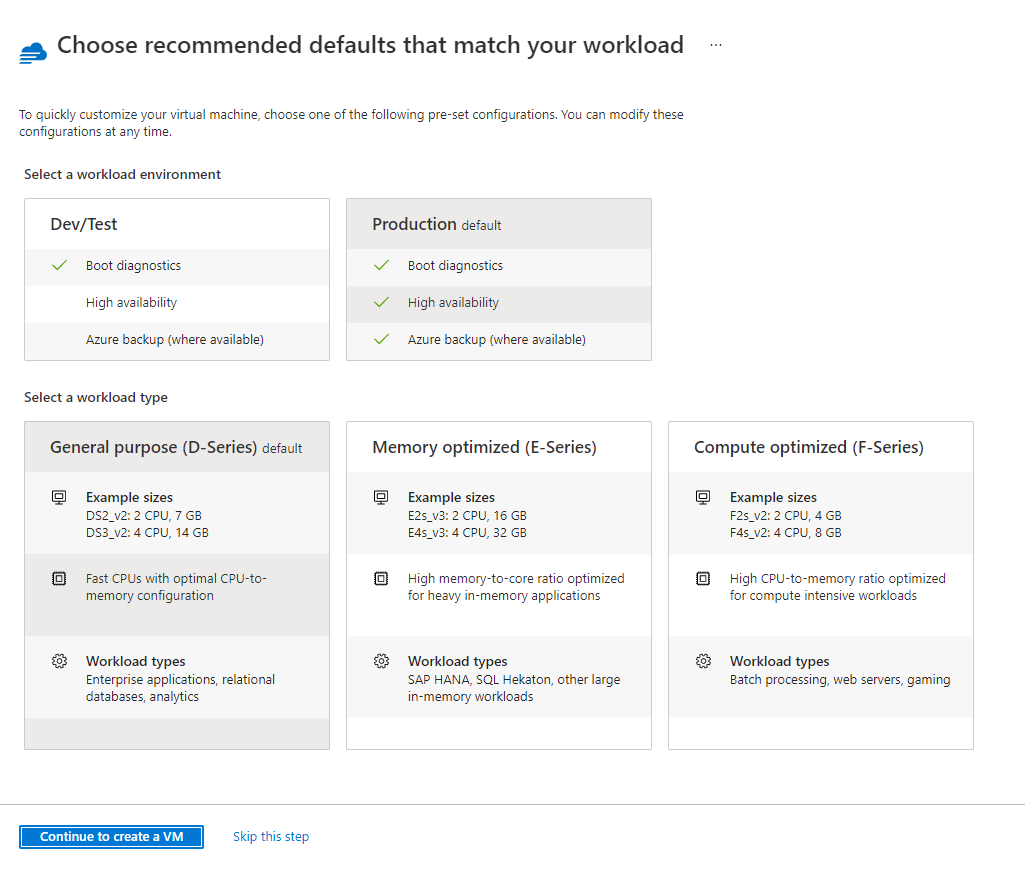
Le choix de la configuration d’installation se fait entre deux modes :
Dev/Test
Production
La configuration de la machine virtuelle se termine en choisissant une image contenant l’installation de Dataïku DSS.
Nous disposerons ainsi de la version 9 de Dataïku DSS, dont le descriptif est disponible sur cette page.
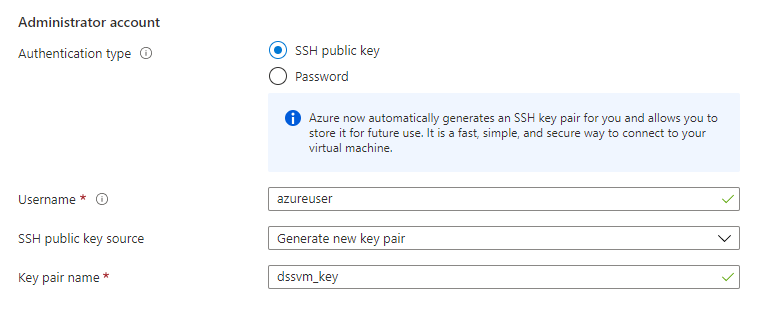
Il sera sûrement nécessaire de se connecter directement à cette machine et nous choisissons le mode SSH, qui demandera la création d’un clé privée, à télécharger sur le poste depuis lequel nous accèderons à la machine. Pensez à utiliser WSL pour faciliter toutes les opérations en lien avec les machines virtuelles Linux ! Mais attention, en version sandbox, les répertoires d’installation de Dataïku ne seront pas accessibles. Cela nous empêchera en particulier d’installer un driver JDBC nécessaire pour communiquer avec une ressource Azure Synapse Analytics mais nous y reviendrons dans un prochain article.
Il ne sera enfin pas possible de se connecter avec une identité présente dans l’annuaire Azure AD.
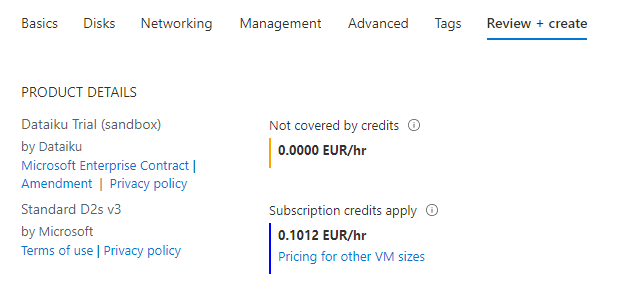
Nous terminons le processus de création sur un récapitulatif tarifaire, indiquant bien que nous ne serons facturés que sur l’utilisation de la machine virtuelle.
Il suffit maintenant de saisir l’IP publique de la machine virtuelle Linux dans un navigateur (connexion http non sécurisée pouvant lever une alerte dans votre navigateur).
Sans licence, nous cliquons sur “NO” afin d’entamer la phase d’évaluation du produit ou son utilisation gratuite (Free Edition).
Le Studio est maintenant prêt et nous disposons d’un login / password (admin /admin par défaut) pour nous reconnecter ultérieurement.
Nous voici dans le Data Science Studio.
Si vous utilisez à plusieurs cette ressource, il est recommandé de créer d’autres comptes utilisateurs.
De prochains articles viendront présenter les interactions de Dataïku DSS avec différentes ressources Azure :
Azure Storage Account (blob ou Data Lake gen2) pour le stockage de données
Azure Synapse Analytics – SQL pool (anciennement DataWarehouse) comme source de données ou cible d’écriture
Azure Synapse Analytics – Spark pool comme ressource de calcul, en particulier pour les entrainements
Azure Kubernetes Services en particulier pour le serving de modèles
Les citizen data scientists disposent d’un outil graphique dans le portail Azure Machine Learning nommé Concepteur (ou Designer en anglais) permettant de réaliser des pipelines de Machine Learning, pour l’apprentissage comme pour l’inférence (c’est-à-dire le fonctionnement prédictif).
Depuis la première version de l’outil, anciennement nommé Azure Machine Learning Studio, et dit maintenant “classique”, des modules pour l’analyse textuelle étaient déjà présents mais l’offre s’est aujourd’hui, en ce début 2021, agrandie.
L’objectif de cet article est de faire un survol des méthodes disponibles, dans cette approche “low code“, pour un jeu de données contenant un champ de “texte libre”, et dans le but de réaliser une méthode d’apprentissage supervisé, et plus précisément de classification.
En prérequis, rappelons les notions indispensables avant de s’attaquer à notre problématique :
– disposer d’une ressource de calcul dite “compute cluster” qui servira à exécuter les différentes itérations du pipeline (succession de modules)
– créer une nouvelle expérience, qui permettra de suivre le résultat des exécutions ou runs (outputs, logs, artefacts, métriques…)
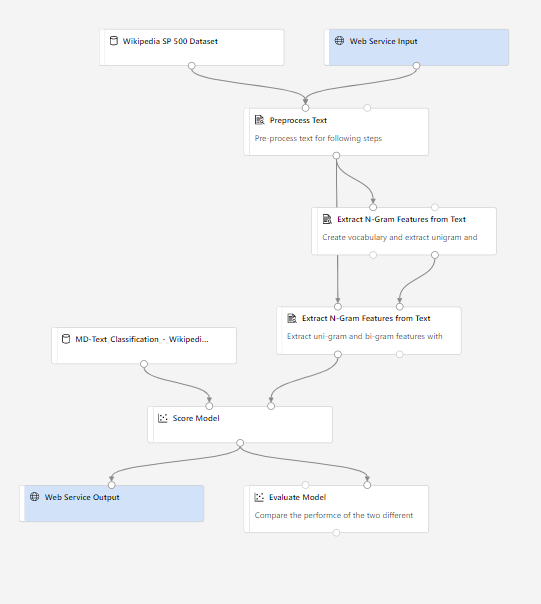
– connaître la structure classique d’un pipeline d’entrainement supervisé (s’inspirer des exemples disponibles, en particulier “Text Classification – Wikipedia SP 500 Dataset” qui est décrit sur ce site GitHub.
Image reprise de la documentation officielle de Microsoft et téléchargeable ici : https://download.microsoft.com/download/C/4/6/C4606116-522F-428A-BE04-B6D3213E9E52/ml_studio_overview_v1.1.pdf
Nous allons nous concentrer ici sur deux phases qui auront leurs spécificités pour le traitement de données textuelles :
– le preprocessing
– le choix du modèle d’apprentissage pour une classification
Preprocessing des données textuelles
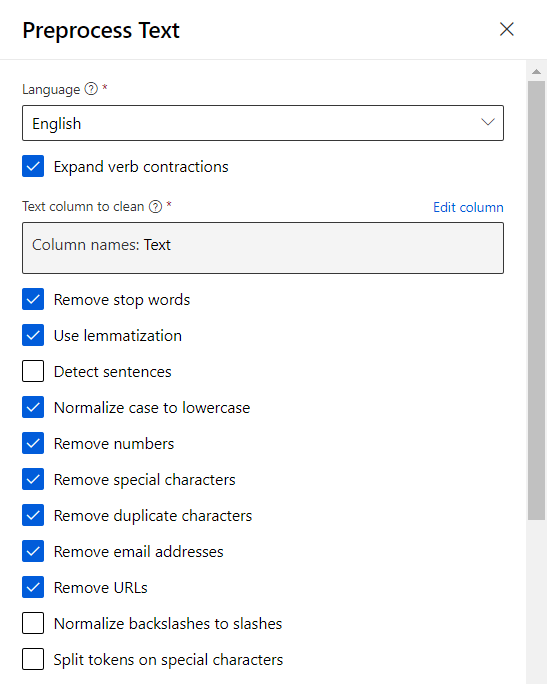
Nous allons utiliser ici le module Preprocess text qui réalisera de nombreuses actions de nettoyage et de préparation de nos données textuelles, en une seule étape.
Ce module est très puissant et basé sur la librairie de référence SpaCy mais ne supporte pour l’instant malheureusement que la langue anglaise. Nous pourrons contourner cela par un script R ou Python pour le cas de corpus en français. Mais à l’exception de la lemmatisation, les opérations pourront toutefois s’appliquer à un corpus d’une autre langue que l’anglais.
La case à cocher “Expand verb contractions” est toutefois spécifique à des formulations anglaises comme don’t, isn’t, I’ve, you’ll, etc.
Détaillons maintenant les autres options, avec quelques exemples simples si nécessaire.
– Retrait des mots outils (stop words) : a, about, all, any, etc.
Cette opération est paramétrable au moyen de la seconde entrée du module. Nous pouvons donc utiliser un fichier, d’une colonne, contenant les mots en français. Ce site propose une liste de mots outils dans de nombreuses langues.
– Lemmatisation (remplacement du mot par sa forme canonique qui est “l’entrée du dictionnaire”, c’est-à-dire, l’infinitif ou le masculin singulier lorsqu’il existe) : la phrase “The babies are walking on their feet” donnera “The baby be walk on their foot” puis sans mots outils “baby walk foot“.
– Détection des phrases (séparées alors par |||, à choisir si l’on souhaite un traitement spécifique par phrase plutôt que par ligne du jeu de données)
– Normalisation en minuscules (sinon les mots sont considérés comme différents)
– Suppression des nombres, caractères spéciaux (non alphanumériques), caractères dupliqués plus de deux fois, adresses email de la forme <string>@<string>, URLs reconnues par les préfixes http, https, ftp, www
– Remplacement des backslashes \ en slashes / : l’usage ne sera pas fréquent, on passera plutôt par la suppression de ces caractères spéciaux.
– Séparation des tokens (ici, les mots) sur la base de caractères spéciaux comme & (pour l’esperluette, on préfèrera à nouveau la citer dans les caractères spéciaux à supprimer) ou - : un “pense-bête” deviendra “penser bête” suite à séparation et lemmatisation en français.
En pratique, il est important de maîtriser l’ordre dans lequel ces opérations s’appliquent. Ainsi, on réalisera plutôt les opérations de nettoyage (suppressions, minuscules, mots outils…) avant les opérations de lemmatisation.
Importer la librairie NLTK et les mots outils en français
Nous disposons d’un module Python permettant d’exécuter un script, sur un ou deux dataframes en entrée de ce module. Le code suivant nous permettra d’importer la librairie NLTK et d’utiliser la liste des mots outils ou bien la lemmatisation en français.
import pandas as pd
def azureml_main(dataframe1 = None, dataframe2 = None):
import importlib.util
package_name = 'nltk'
spec = importlib.util.find_spec(package_name)
logging.debug(spec)
if spec is None:
import os
os.system(f"pip install nltk")
import nltk
from nltk.corpus import stopwords
stopwords = set(stopwords.words('french'))
def preprocess(text):
clean_data = []
for x in (text[:]):
print(x)
new_text = re.sub('<.*?>', '', x) # remove HTML tags
new_text = re.sub(r'[^\w\s]', '', new_text) # remove punc.
new_text = re.sub(r'\d+','', new_text)# remove numbers
new_text = new_text.lower() # lower case, .upper() for upper
if new_text != '':
clean_data.append(new_text)
return clean_data
dataframe1['preprocess'] = preprocess(dataframe1['Text'])
dataframe1['preprocess_without_stop'] = dataframe1['preprocess'].apply(lambda x: [word for word in x if word not in stopwords])
#On peut observer la liste des mots outils de NLTK dans la seconde sortie
dataframe2 = pd.DataFrame(list(stopwords))
return dataframe1, dataframe2,
Apprentissage supervisé sur données textuelles
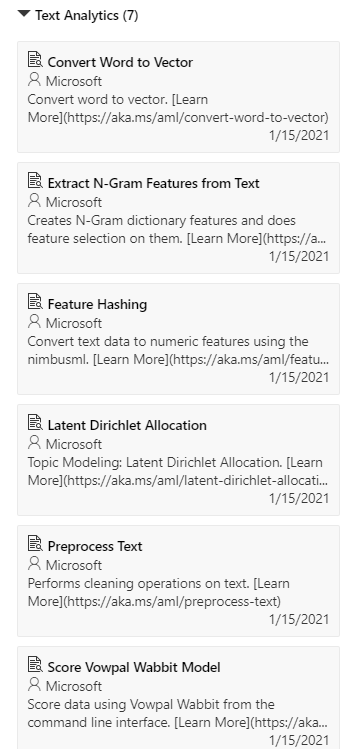
Dans le groupe Text Analytics, nous disposons des modules ci-dessous.
Vowpall Wabbit
Nous écartons d’emblée l’approche Vowpal Wabbit, framework de Machine / Online Learning initialement développé par la société Yahoo !. Celui-ci nécessite en effet d’obtenir en entrée des données préprocessées mais surtout présentées dans un format spécifique. Vous pouvez toutefois vous référer à ce blog si vous souhaitez préparer vos données en ce sens. Il faudra ensuite utiliser des lignes de commandes au sein du module Train Vowpal Wabbit Model.
Toutefois, nous allons pouvoir remplacer ce framework par une approche relativement similaire réalisée par le module Feature Hashing.
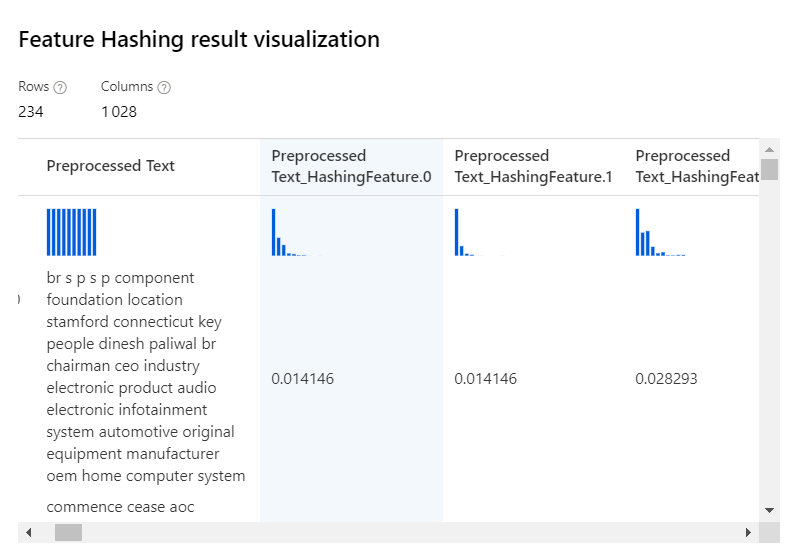
Feature Hashing
Cette méthode consiste à créer une table de hash, c’est-à-dire de valeurs numériques, construites à partir du dictionnaire des mots.
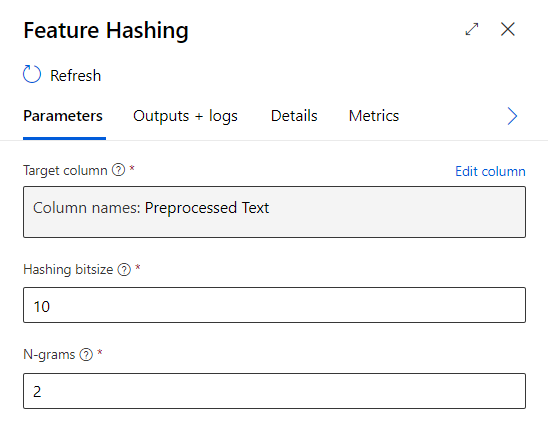
Nous prendrons comme entrée le texte préprocessé. Nous avons alors deux paramètres à renseigner dans la boîte de dialogue du module.
Une taille de 10 bits correspondra à 2^10, soit 1024, nouvelles colonnes dans le jeu de données en sortie. Ces colonnes contiendront le poids de la feature dans le texte. Une valeur de 10 se montre généralement suffisante et attention à l’explosion de la taille du jeu de données (2^20 correspondrait à 1048576 colonnes !).
Un N-gram est une suite de n mots consécutifs, considérée comme une seule unité. Dans la phrase “le ciel est bleu”, nous avons quatre unigrams, trois bigrams (“le ciel”, “ciel est”, “est bleu”) et deux trigrams (“le ciel est”, “ciel est bleu”). Le paramètre attendu est la valeur maximale, ainsi si nous choisissons la valeur 3, nous prenons en compte les unigrams, bigrams et trigrams.
Nous obtenons le résultat suivant.
Seules les colonnes numériques seront ensuite soumises à l’entrainement du modèle.
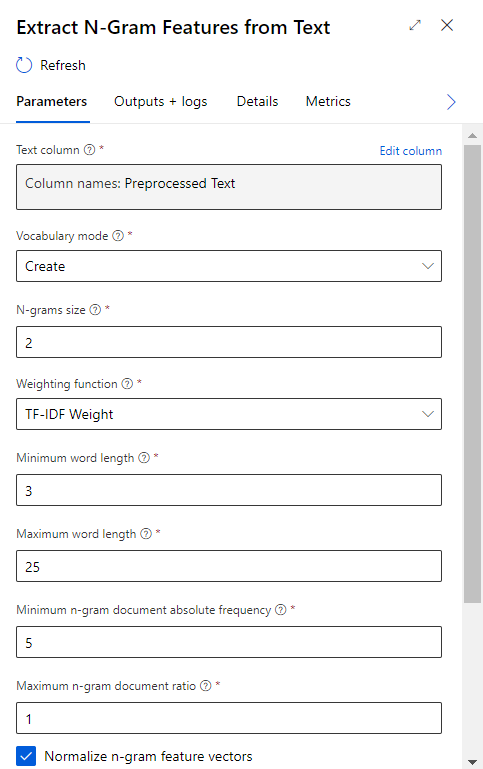
Extract N-gram feature
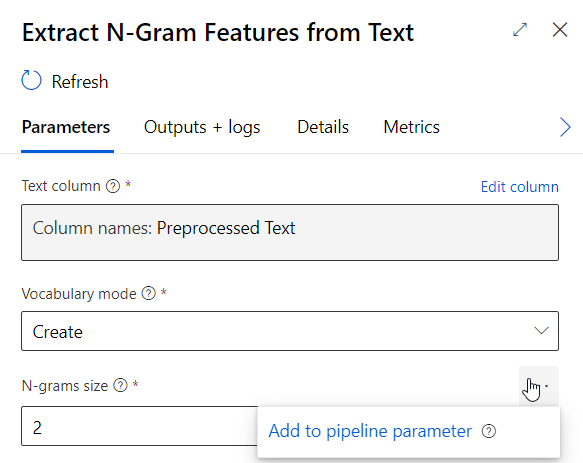
Nous retrouvons ici la notion de N-gram (suite de n mots consécutifs, considérée comme une seule unité). Les paramètres disponibles nous permettent de spécifier :
– la taille maximale des N-grams considérés dans le dictionnaire. Ce paramètre conditionnera la taille du jeu de données, qui peut devenir très grand.
– les longueurs minimale et maximale des mots, en nombre de lettres
– la fréquence minimale de présence d’un N-gram dans le document (ensemble des lignes du jeu de données)
– le pourcentage maximum de présence d’un N-gram par ligne sur l’ensemble des lignes. La valeur 1 (100%) correspond à retirer un N-gram présent dans chaque ligne, et donc considéré comme un bruit qu’il faut supprimer.
– la métrique de pondération calculée par ligne, pour chaque feature créée.
La métrique TF-IDF est un standard de la discipline est correspond au ratio de la fréquence d’un N-gram dans la ligne (TF) par le log d’un autre ratio dit”inversé” : le nombre de lignes du jeu de données sur la fréquence du terme dans le jeu de données. Les valeurs seront normalisées selon une norme L2 si la case correspondante est cochée dans la boîte de dialogue.
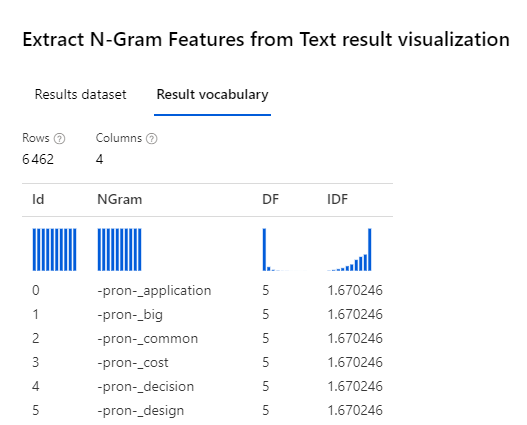
En créant le vocabulaire, nous obtenons un jeu de données en sortie tel que représenté ci-dessous. Celui-ci contient la liste des N-grams, ainsi que les métriques DF et IDF associées.
Un pronom est ici identifié dans le bigram.
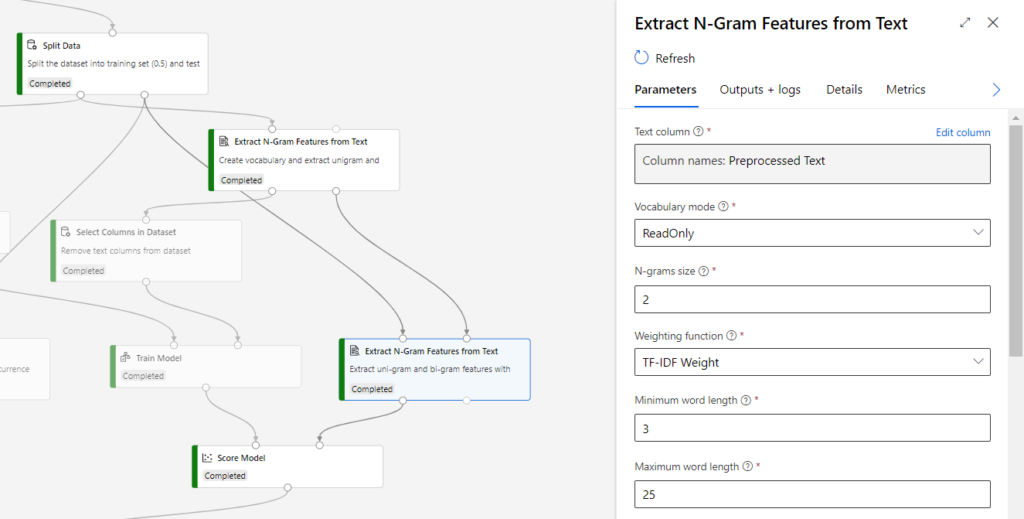
C’est ce vocabulaire établi sur le jeu d’entrainement qui devra saisir à la phase de validation sur les nouvelles données. Il ne faudrait pas créer un nouveau vocabulaire sur la seconde partie des données ! Mais les métriques doivent être calculées. Nous utilisons donc la combinaison ci-dessous des modules.
Le paramètre “Vocabulary mode” est alors positionné sur la valeur ReadOnly.
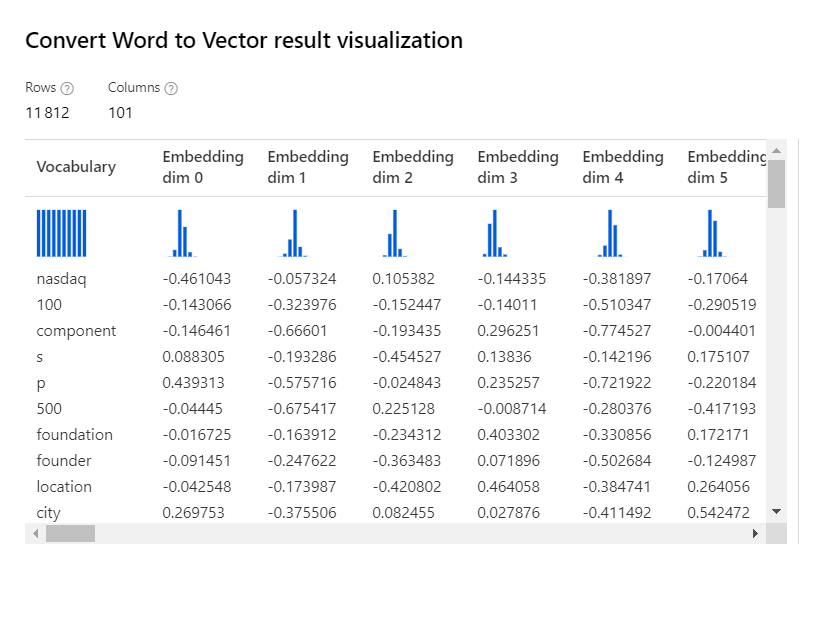
Convert word to vector
Nous retrouvons ici une méthode dite de plongement lexical (word embedding) qui a connu un fort engouement ces dernières années, et plus communément appelée word2vec. Il s’agit d’utiliser des modèles pré-entrainés sur des milliards de documents, issus par exemple de Wikipedia ou de Google News.
A ce jour (janvier 2021), il ne semble pas y avoir de module permettant de tirer parti du vocabulaire obtenu en sortie. Nous privilégierons donc une approche par script Python, au moyen de librairies comme Gensim (voir le site officiel).
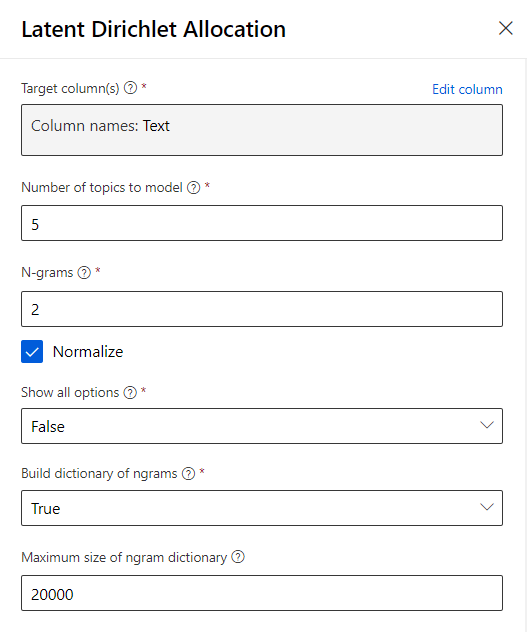
Latent Dirichlet Allocation
Nous sortons ici du cadre supervisé pour obtenir une méthode non supervisée et donc dédiée à rassembler des textes similaires, dans un nombre prédéfini (“Number of topics to model”) de catégories, sans que celles-ci ne soient explicitement définies.
Comme nous disposons déjà des catégories, cette méthode ne se prête pas à l’objectif mais pourrait être intéressante en amont, dans un but exploratoire (nos catégories a priori ne sont peut-être pas si pertinentes…).
Un mode d’options avancées donnera la main sur tous les hyperparamètres du module.
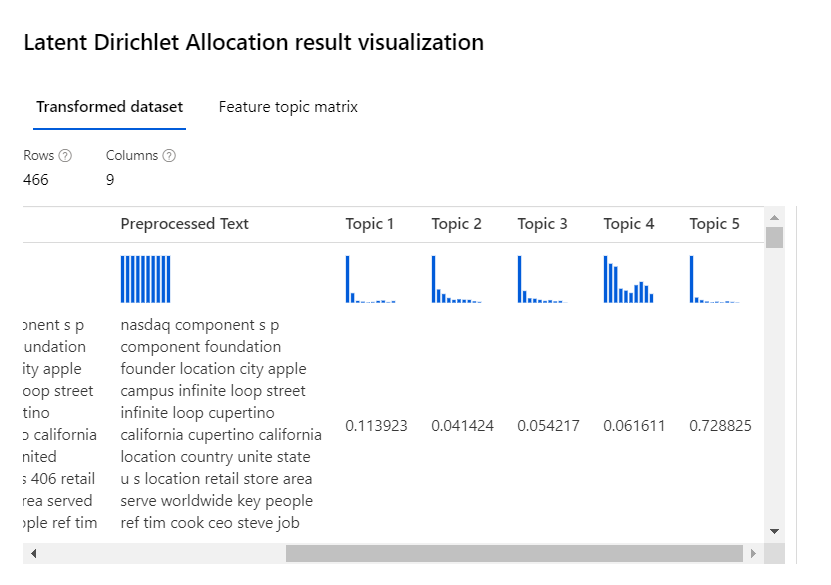
Chaque ligne est évaluée sur les nombre prédéfini de sujets (topics).
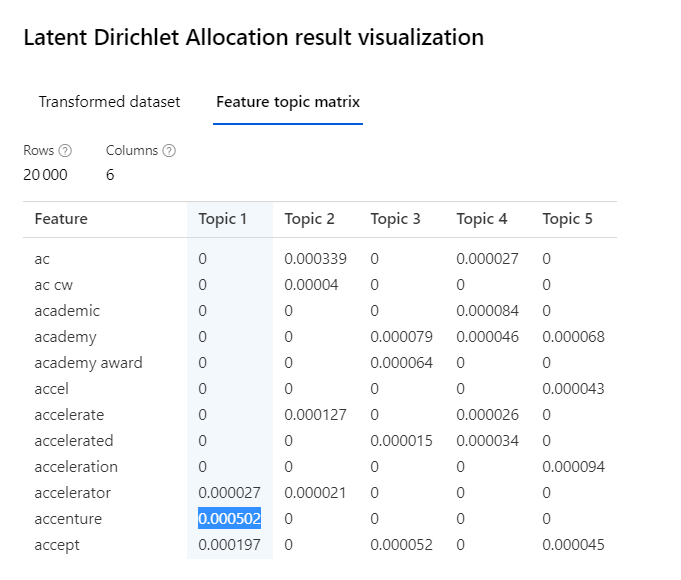
A partir de la sortie, il sera nécessaire de réaliser une lecture et une interprétation “humaine” sur les sur les groupes afin de les nommer. Dans la feature matrix topic, nous pouvons visualiser les N-grams les plus contributeurs de chaque sujet.
Publier le pipeline d’entrainement
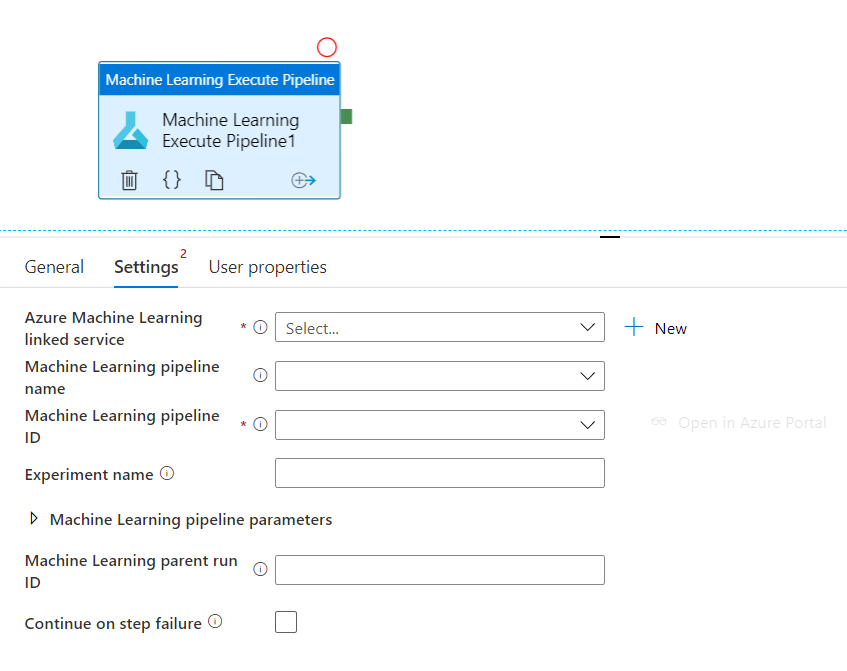
Publier un pipeline permet de bénéficier de l’ordonnancement de celui-ci, par exemple avec un outil comme Azure Data Factory. Nous obtiendrons ainsi un identifiant (ID) qui devra être renseignée dans l’activité.
Les différents paramètres sélectionnés dans les modules peuvent être ajoutés comme paramètres du pipeline et ainsi renseignés lors de nouveaux lancements.
Déploiement du pipeline d’inférence
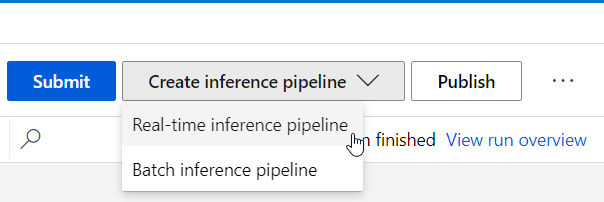
Une fois le pipeline d’entrainement soumis et correctement exécuté (tous les modules sont en vert), nous pouvons choisir entre un service Webprédictif, soit en real-time (prévision par valeur), soit en batch (prévision par lot).
Si nous avons comparé plusieurs modèles au sein du pipeline d’entrainement, il faut cliquer sur le module “Train model” correspond à celui que l’on veut déployer (en pratique, celui ayant les meilleures métriques d’évaluation).
Le pipeline graphique se simplifie alors et se voit enrichi d’une entrée et d’une sortie pour le service Web qui sera créé.
Attention, pour aller plus loin, il est nécessaire de supprimer le module d’évaluation ou sinon, vous rencontrerez le message d’erreur suivant.
Un nouveau run du pipeline doit être soumis avant de pouvoir cliquer sur le bouton de déploiement du service web.
Le déploiement se fait au choix, sur une ressource ACI (plutôt pour le test) ou AKS (plutôt pour la production).
En conclusion, même s’il paraît difficile d’aller jusqu’en production avec cet outil, il reste néanmoins très rapide pour mettre en œuvre différentes méthodes reconnues dans le Traitement Automatique du Langage (TAL) et pourra apporter des résultats pertinents dans des cas relativement simples de classification.
Pour des données établissant une série temporelle (mesure numérique à intervalles de temps régulier), la première étape de mise en qualité des données sera bien souvent de corriger les données dites aberrantes, c’est-à-dire trop éloignées de la réalité.
Rappelons les différents cas pouvant amener à ce type de données : – erreur de mesure ou de saisie (maintenant plutôt lié à une erreur “informatique”) – dérive réelle et ponctuelle (souvent non souhaitée, correspondant à un défaut de qualité) – hasard (événement assez peu probable mais pouvant néanmoins se produire exceptionnellement!)
Avec la version de novembre 2020 de Power BI Desktop, nous découvrons une nouvelle fonctionnalité en préversion (donc à activer depuis le menu Options) qui ajoute une entrée dans le menu Analytique des graphiques en courbe (“line chart“).
Tout d’abord, regardons les limites d’utilisation précisées à cette page. Si 12 points sont le minimum requis (ou 4 patterns saisonniers), il sera beaucoup plus pertinent d’en avoir en plus grand nombre ! Ensuite, de nombreuses fonctionnalités ne sont pas (encore ?) compatibles avec la détection d’anomalies : légende, axe secondaire, prévision (forecast), live connection, drill down…
Fonctionnement théorique
Le papier de recherche qui décrit l’algorithme utilisé, nommé unsupervised SR-CNN, est disponible ici. Nous allons essayer de le vulgariser sans trop d’approximations.
Cet algorithme d’apprentissage automatique fait partie de la catégorie des méthodes non-supervisées, c’est-à-dire qu’il n’est pas nécessaire de disposer a priori d’un échantillon de données d’apprentissage où les anomalies seraient déjà identifiées (approche supervisée).
Les deux premières lettres du nom de cette approche correspondent à la méthode dite Spectral Residual, basée sur des transformées de Fourier, qui met en valeur des éléments “saillants” (salient) de la série temporelle.
Issus du domaine du Deep Learning, les réseaux de neurones à convolution (CNN) ont émergé dans le domaine du traitement d’images en deux dimensions. Pour autant, il est tout-à-fait possible de les utiliser dans le cadre d’une série temporelle à une dimension. Au lieu d’analyser des fragments d’images, la série des données transformées va être reformulée comme plusieurs successions de valeurs.
Ainsi, la série {10, 20, 30, 40, 50, 60} pourra donner des séries comme {10, 20, 30}, {20, 30, 40} ou encore {40, 50, 60} (voir ce très bon article pour aller plus loin dans le code).
Le rôle de la couche de convolution est d’extraire les features (caractéristiques) de la série temporelle. Ce sont elles qui permettront ensuite de décider si une valeur est ou non une anomalie.
D’un point de vue de l’architecture du réseau, la couche de convolution à une dimension est suivi d’une couche “fully connected” qui fait le lien entre le résultat de la convolution et le label de sortie (anomalie ou non).
Allons maintenant à la recherche d’un jeu de données pour expérimenter cette fonctionnalité !
Test sur un jeu de données
Il existe des jeux de données de référence pour évaluer la performance de la détection d’anomalies, et plus spécifiquement dans le cadre des séries temporelles. Vous en trouverez par exemple sur cette page.
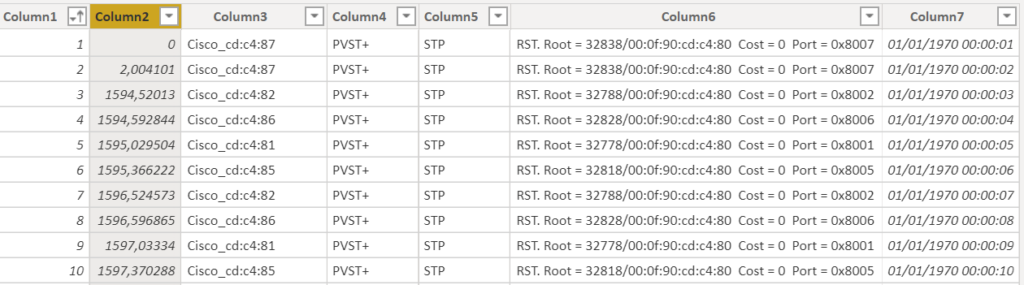
Nous travaillerons ici avec un jeu de données de trafic réseau.
Ce dataset contient environ 4,5 millions de lignes.
La détection d’anomalies se déclenche dans le menu Analytique du visuel.
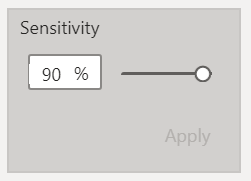
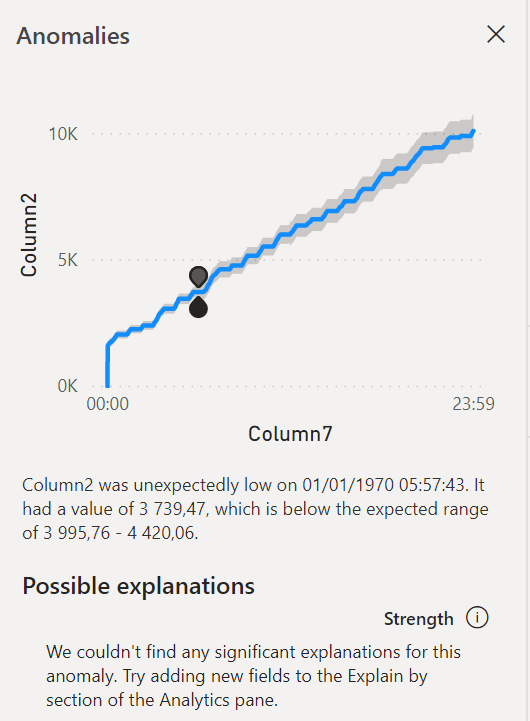
Un seul paramètre est disponible pour régler le niveau de détection, entre 0 et 100% : sensitivity.
Plus la valeur est élevée, plus “l’intervalle de confiance” en dehors duquel sera détectée une anomalie est fin. Autrement dit, plus la valeur approche des 100%, plus vous apercevrez de points mis en évidence. Difficile de dire sur quoi joue ce paramètre d’un point de vue mathématique, il n’est pas évoqué dans le papier de recherche cité précédemment.
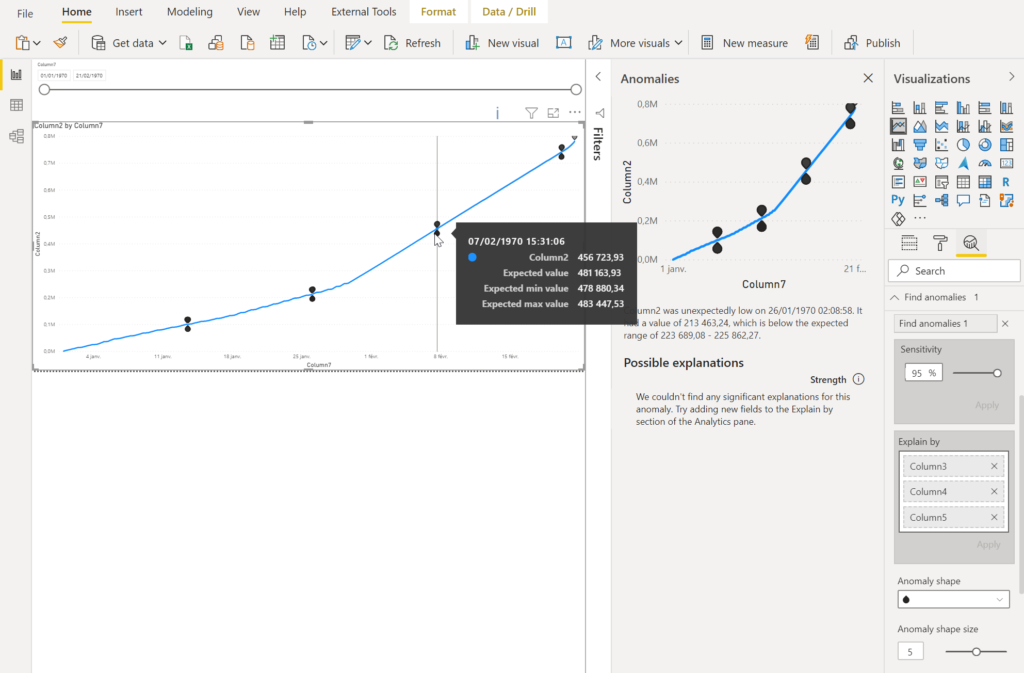
En cliquant sur un point, s’ouvre un nouveau volet latéral donnant les valeurs de la plage attendue, reprises également dans l’infobulle.
En plaçant d’autres champs de la table dans la case “explain by“, on peut espérer mettre une évidence un facteur explicatif de cette anomalie.
Attention, il n’est pas envisageable de “zoomer” sur un portion du graphique contenant une anomalie car cela modifiera la plage de données servant à évaluer l’algorithme et fera donc apparaître ou disparaître des points identifiés comme aberrants !
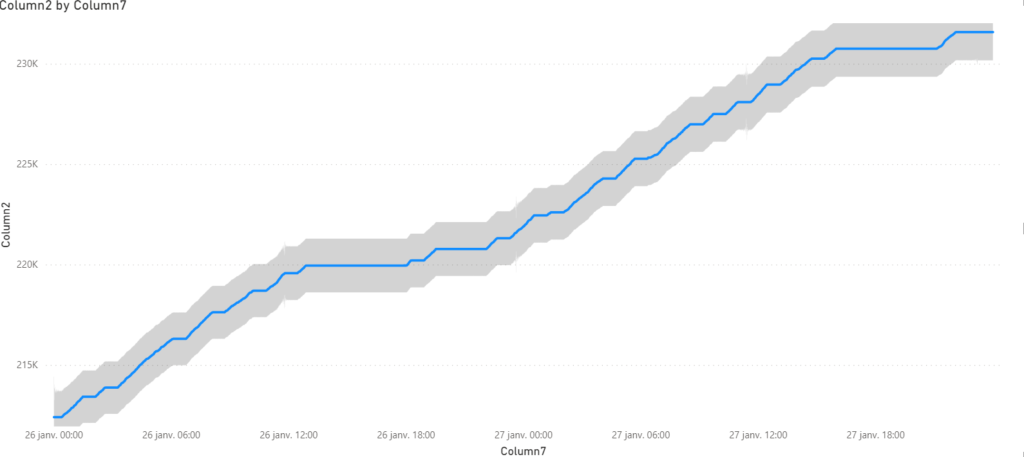
Zoom sur une journée contenant initialement une détection d’anomalies
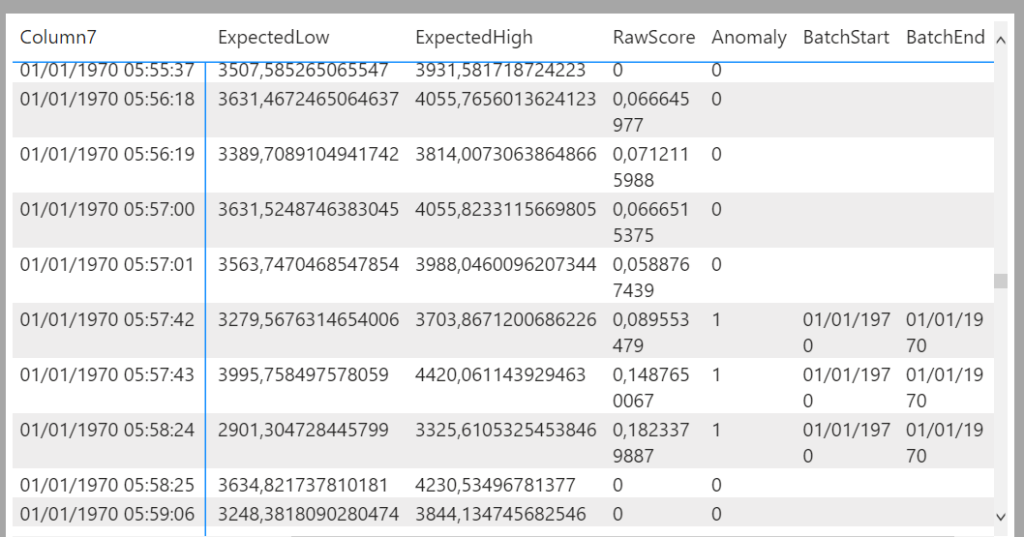
On pourra plutôt profiter de l’affichage du visuel en tant que table de données qui dispose d’une colonne “anomaly” valant 0 ou 1. On s’aperçoit ici que plusieurs points consécutifs sont identifiés comme des anomalies, ce qui était difficilement identifiable sur le graphique.
En conclusion
Malheureusement, les informations obtenues au travers de ce visuel ne peuvent pas réellement être exploitées : pas d’indicateur créé dans la table, pas d’export au delà de 30000 points (soit un peu plus de 8h pour des données à la seconde), un modèle perpétuellement recalculé et ne pouvant être arrêté sur une période. Alors, que faire lorsque des anomalies apparaissent ? Rien hormis prévenir le propriétaire des données…
Comme pour les autres services touchant (de loin) à l’IA sous Power BI, je suis sceptique quant au moment où cette fonctionnalité est mise en œuvre. La détection d’anomalies est une étape de préparation de la donnée et hormis à effectuer un reporting sur ces anomalies elles-mêmes, nous sommes en droit d’attendre qu’elles soient déjà retirées des données avant exposition. Il serait donc beaucoup plus opportun d’utiliser le service cognitif Azure dans un dataflow (Premium ou maintenant en licence Premium Per User) afin de mettre la donnée en qualité lors de la constitution de donnée. Pour une détection sur un flux de streaming, on se tournera avec intérêt vers les possibilités offertes par Azure Databricks, comme exposé dans ce tutoriel.
A l’inverse, les algorithmes prédictifs qui ne peuvent être utilisés que dans les dataflows seraient beaucoup plus à leur place dans un visuel qui permettrait de tester différents scénarios et d’observer les prévisions associées.
En résumé, les ingrédients de la recette sont les bons, encore faut-il les ajouter dans l’ordre pour obtenir un plat satisfaisant !
L’algorithme choisi (SR-CNN) ne doit pour autant pas être remis en cause car il semble aujourd’hui représenter l’état de l’art de la détection d’anomalies;
Vos remarques sur cet outil peuvent être déposées sur cette page communautaire.
(*) Revenir à l’essentiel : l’analyse des données !
Intelligence Artificielle,
Machine Learning, RGPD… la donnée ne quitte plus le devant de la scène
médiatique, qui attribue bien souvent à la data des pouvoirs thaumaturges. Le
monde du recrutement s’emballe autour des profils « Data Scientists »
tout en présentant des listes de compétences impossibles à maîtriser pour une
seule et même personne, allant de l’architecture Big Data à la programmation de
réseaux de neurones convolutifs (le fameux Deep Learning). A l’exception des entreprises
dont la data constitue le cœur de métier comme Booking, AirBNB ou Uber, quelles
sont celles qui ont réellement modifié et amélioré leur activité par une approche
« data driven »,
c’est-à-dire pilotée par la donnée ? Ce phénomène de « hype » autour de la donnée peut
poser question et générer une certaine méfiance.
Pourtant, une réaction inverse qui reviendrait à rejeter tout apport de la donnée serait aussi improductive. Et tant qu’à stocker la data, autant en tirer profit ! Dans une série de trois articles, nous nous arrêterons successivement sur l’intérêt, pour les entreprises, de l’analyse de données exploratoire, l’analyse prédictive grâce au Machine Learning et les promesses du Deep Learning sur les données non structurées.
Une même finalité, de nouveaux outils
Bien avant l’explosion de l’engouement pour la Data Science, certaines personnes dans l’entreprise pratiquaient déjà l’analyse de données sous des intitulés de poste tels que « chargé.e d’études statistiques », « statisticien.ne », « actuaire », « data miner », etc. Souvent éloignées du département IT et des architectures de production, ces personnes en charge de forer la donnée réalisent des extractions puis travaillent ces échantillons dans un classeur Excel ou un logiciel spécialisé. Une fois les conclusions obtenues, celles-ci figurent dans une présentation au format Word ou PowerPoint, c’est-à-dire sans possibilité simple de mise à jour ni d’extension à d’autres données. Nous allons voir ici que c’est aujourd’hui, non pas un bouleversement méthodologique, mais bien une simplification et une meilleure performance des outils qui changent ces métiers.
Notre approche méthodologique visera à répondre aux quatre temps de l’analyse de données.
Les quatre temps de l’analyse de données
Prenons un exemple concret : l’analyse des accidents corporels de la circulation pour laquelle les données sont disponibles en open data sur le portail data.gouv.fr.
Pour une première
approche du jeu de données, nous travaillerons dans l’outil Microsoft Power BI Desktop qui, même s’il
n’est pas un logiciel statistique à proprement parler, permet de nettoyer et
visualiser les données très rapidement. Nous verrons même qu’il cache plusieurs
fonctionnalités analytiques particulièrement intéressantes. Enfin, lorsque
l’étude exploratoire sera terminée, il ne sera plus nécessaire de quitter
l’outil pour présenter les résultats dans un logiciel bureautique figé.
L’interface proposera une visualisation dynamique et adaptée à la restitution.
L’indispensable nettoyage des données
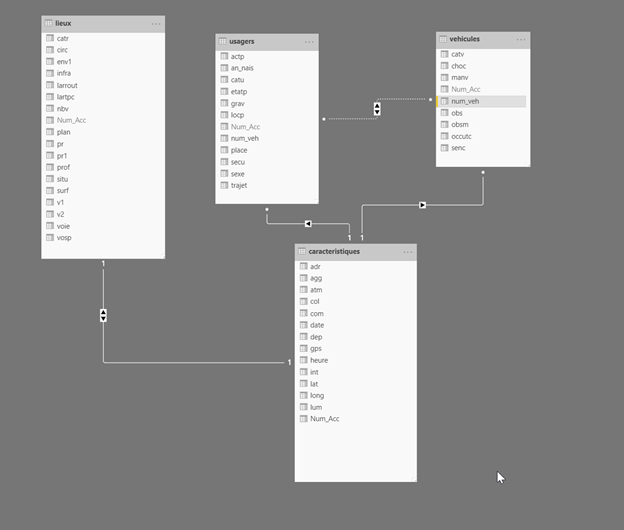
Observons tout d’abord le
schéma des données collectées, dont la description précise des champs est
disponible dans ce document. Nous travaillerons ici avec les notions
de :
Caractéristiques de l’accident
Lieu de l’accident
Véhicules impliqués
Usagers des véhicules impliqués
Modélisation des données dans Power BI Desktop
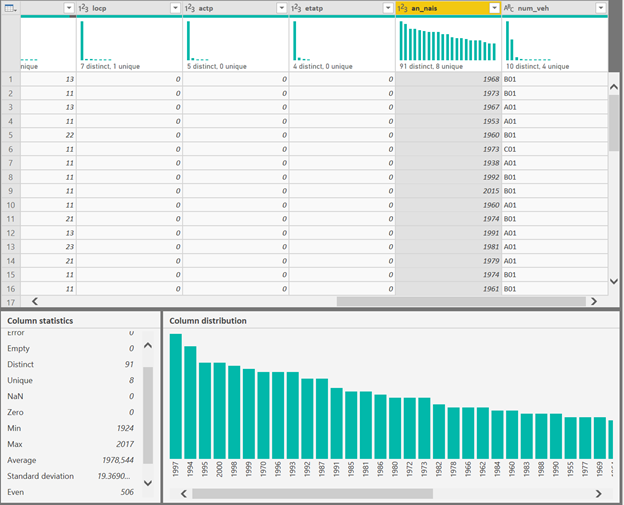
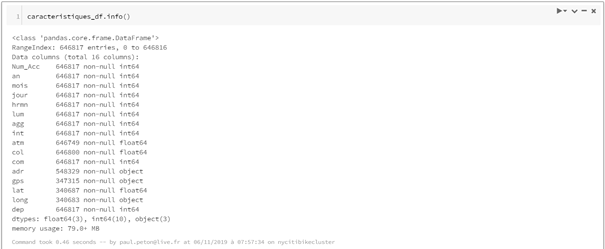
La qualité des données en entrée déterminera la qualité des résultats qui seront obtenus (ou tout du moins, garbage in, garbage out !). Un travail d’inspection de chaque champ est nécessaire et celui-ci se fait rapidement grâce au profil de la colonne, comme par exemple ci-dessous, sur l’année de naissance de l’usager.
La lecture des indicateurs de synthèse (moyenne, médiane, écart-type, etc.) nous permet de débusquer des valeurs aberrantes (un conducteur né en 1924, cela reste plausible) et de comptabiliser des valeurs manquantes qui nécessiterait un traitement spécifique (ici, toutes les lignes sont renseignées.)
L’interaction pour une meilleure
exploration des données
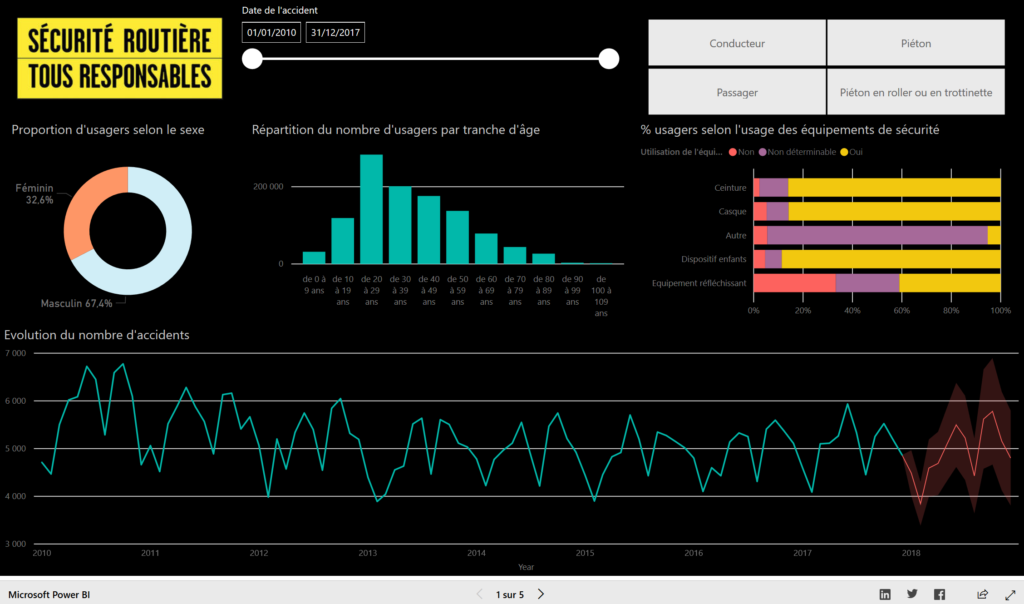
L’une des grandes forces de Power BI réside dans son haut niveau d’interaction avec la donnée, au moyen de filtres visuels ou en sélectionnant un élément graphique pour obtenir instantanément la mise à jour des autres visuels.
L’analyse descriptive est ainsi rapidement obtenue. A vous de jouer, ce rapport est totalement interactif !
Bien sûr, il ne faudra
pas tomber dans le travers de chercher à filtrer sur toutes les dimensions
possibles ! L’être humain n’est pas en capacité d’appréhender un trop
grand nombre d’informations mais les méthodes d’analyse avancée sont là pour
nous aider.
Des fonctionnalités pour l’analyse
explicative
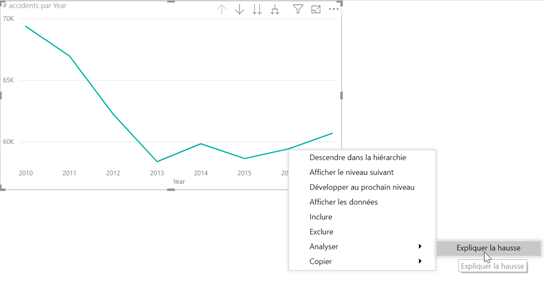
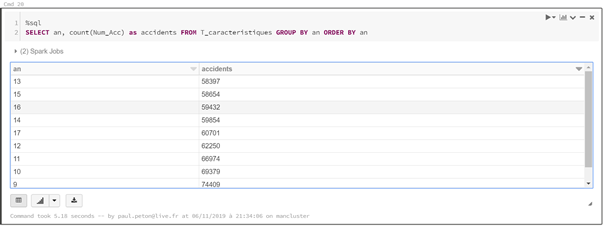
Observons l’évolution du nombre d’accidents dans le temps, au niveau annuel. On constate une hausse en 2016 avec un recul des accidents sur les années précédentes.
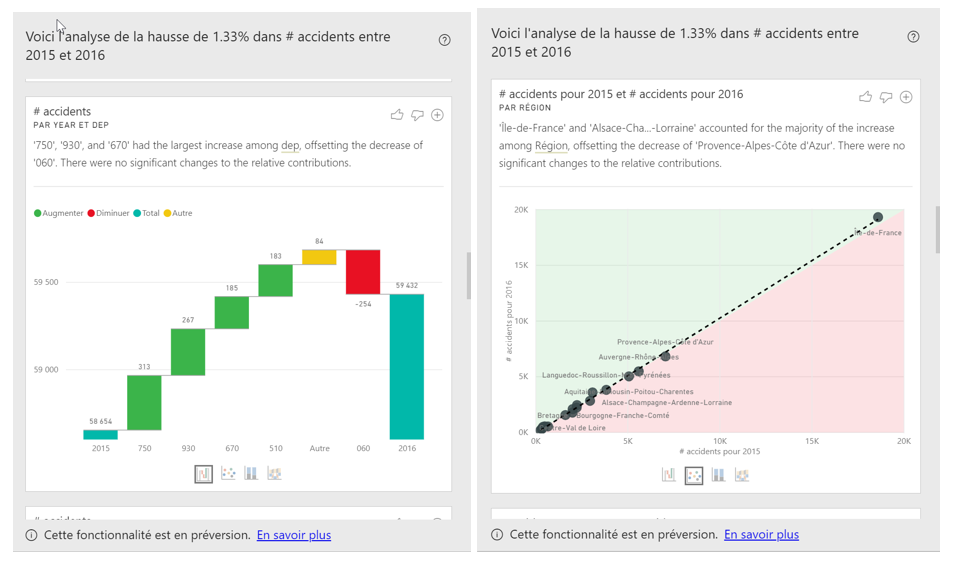
Expliquer (automatiquement) la hausse
Power BI va rechercher les facteurs explicatifs de la hausse de l’indicateur en testant tous les champs du modèle et nous fera plusieurs propositions. Nous retenons ici celle du département de l’accident qui met en évidence une hausse significative sur les départements d’Ile-de-France 75 et 93, contre une baisse dans les Alpes-Maritimes. Cette piste nous mettrait sur la voie de données décrivant ces départements (population, infrastructures routières, etc.).
Visuels générés automatiquement par Power BI : l’utilisateur choisit le plus parlant.
L’analyse faite jusqu’ici
nous permet de comprendre les données dans leur ensemble mais il est
fondamental de répondre à une problématique levée par le sujet, ici
l’accidentologie, et nous allons donc rechercher des explications à la
mortalité routière.
Nous disposons pour cela d’une information sur la gravité de l’accident qui permet de déterminer si l’usager est décédé.
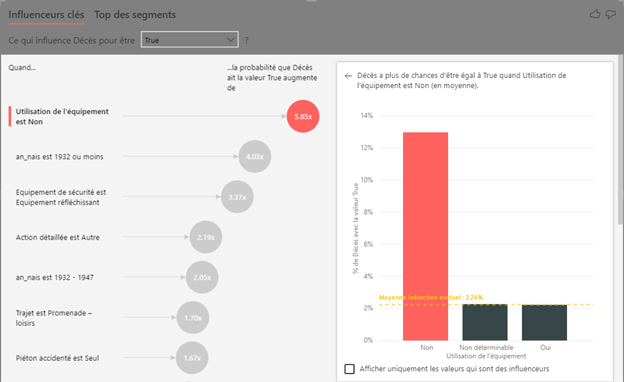
Influenceurs clés : une régression logistique visuelle !
L’analyseur d’influenceurs clés (key influencers, basé sur une approche de modélisation par régression logistique) identifie la non utilisation d’un équipement de sécurité (ceinture, casque, etc) comme le facteur le plus fort dans un décès lié à un accident : la probabilité est presque multipliée par 6. L’âge est également un facteur très important. Si celle-ci est inférieure à 1932, le risque de décès est ici multiplié par 4.
Nous obtenons ici, grâce
à l’analyse, des leviers d’actions concrets pour la sécurité routière, ce qui
constitue une première forme d’analyse prescriptive
… et une première analyse prédictive !
Reprenons l’évolution du
nombre d’accidents dans le temps mais cette fois-ci, au niveau mensuel. La
courbe traduit clairement une notion de saisonnalité : il y a beaucoup
(trop) d’accidents lors des périodes de vacances scolaires par exemple. Si l’on
ajoute une droite de tendance, on voit que celle-ci est légèrement à la hausse.
Prolonger cette droite ne donnerait pas une bonne prévision au détail mensuel
puisqu’il faut tenir compte de cette saisonnalité.
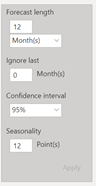
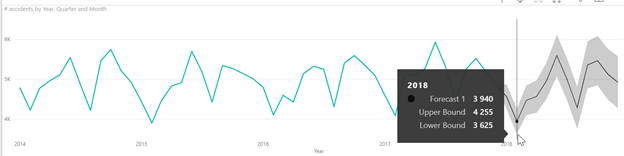
Nous utilisons ici la fonctionnalité de « forecast » de Power BI basée sur la méthode statistique du lissage exponentiel. N’allons pas trop loin, il est conseillé de ne pas dépasser une prévision au tiers de l’historique disponible. Cette prévision est encadrée par un intervalle de prévision, donnant les bornes entre lesquelles on espère voir apparaître la « vraie » valeur, avec un niveau de confiance de 95%.
Paramètres de la prévision
On obtient alors la prévision sur le graphique et l’infobulle donne les valeurs chiffrées.
Une présentation dynamique sans changer
d’outil
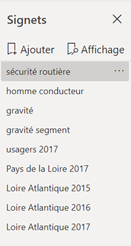
Résumons maintenant toutes les informations découvertes au travers de cette première analyse. Pour communiquer ces résultats, nous pourrions utiliser un support externe comme PowerPoint ou un fichier PDF mais nous perdrions toute interaction. Les bookmarks (ou signets) de Power BI sont ici un outil extrêmement pratique pour garder en mémoire une sélection personnalisée de filtres et enchainer la lecture de plusieurs pages de rapport comme l’on enchainerait des diapositives.
Azure Databricks se positionne comme une plateforme unifiée pour le traitement de la donnée et en effet, le service de clusters managés permet d’aborder des problématiques comme le traitement batch, mais aussi le streaming, voire l’exposition de données à un outil de visualisation comme Power BI.
La capacité de mise à l’échelle (scalabilité ici horizontale) d’Azure Databricks est également un argument de poids pour
établir cette solution dans un contexte de forte volumétrie. Par forte
volumétrie, nous entendons ici le fait qu’un tableau de données, ou les
opérations qui permettraient d’y parvenir,
dépasse la mémoire disponible sur une seule machine. La solution sera
donc de distribuer la donnée ou les
traitements. Mais attention, il va falloir bien choisir ses armes avant de se
lancer dans un premier notebook !
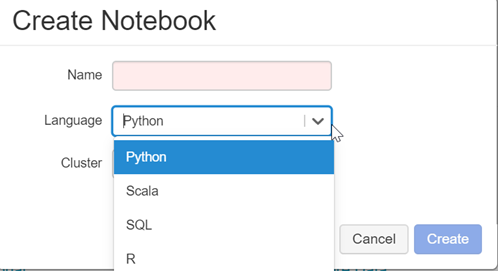
Le choix des armes
A la création d’un notebook sur Azure Databricks, quatre langages sont disponibles.
Sauf à ne vouloir faire que du SQL, je vous déconseille de prendre ce type de notebook puisqu’il sera très simple d’exécuter une commande SQL dans une cellule à l’aide la commande magique %sql.
Si vous venez de la Data Science « traditionnelle » (rien de péjoratif, c’est d’ailleurs mon parcours, comprendre ici l’approche statistique antérieure à l’ère de la Big Data), vous serez attirés par le langage R. Mais vous savez sûrement que R est un langage, de naissance, single-threaded et peu apte à paralléliser les traitements. Microsoft a pourtant racheté la solution RevoScaleR de Revolution Analytics et l’a intégrée en particulier à SQL Server. Dans un contexte Spark, on peut s’orienter vers l’API SparkR mais celle-ci ne semble pas soulever un très gros engouement (contredisez-moi dans les commentaires) dans la communauté.
Python remporte aujourd’hui une plus forte adhésion, en
particulier auprès des profils venant du monde du développement. Attention,
coder un traitement de données en Python ne vous apportera aucune garantie
d’amélioration par rapport au même code R ! Ici, plusieurs choix se
présentent à nouveau.
Une première piste sera d’exploiter la librairie Dask qui permet de distribuer les
traitements.
Une deuxième possibilité est de remplacer les instructions
de la librairie pandas par la librairie développée par Databricks : koalas. Je détaillerai sûrement
l’intérêt de cette librairie dans un prochain article.
Le troisième choix possible sera à mon sens le
meilleur : l’API pyspark. Cette
API va vous permettre :
de créer des objets Spark DataFrames
d’enregistrer ces DataFrames sous formes de
tables (locales ou globales dans Databricks)
d’exécuter des requêtes SQL sur ces tables
de lire des fichiers au format parquet
Les API Spark permettent d’écrire dans un langage de plus haut niveau et plus accessible pour les développeurs (data scientists ou data engineers) qui sera ensuite traduit pour son exécution dans le langage natif du cluster.
Les différents codes possibles
Je vous propose ci-dessous un comparatif des approches
pandas et pyspark pour un même traitement de données. Le scénario est de
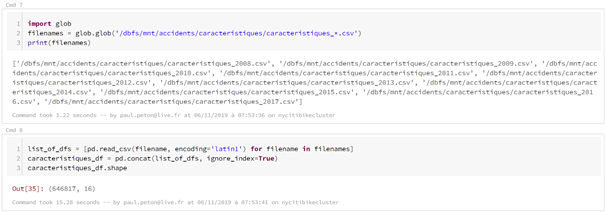
charger les données de la base open data des accidents corporels, soit deux
dossiers de fichiers csv : les usagers et les caractéristiques des
accidents. Une fois les fichiers chargés, une jointure sera réalisée entre les
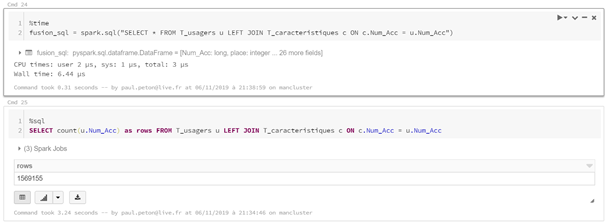
deux sources sur la base d’une clé commune.
L’objectif est ici d’établir un parallèle entre les syntaxes et non d’évaluer les performances. La librairie pandas n’est d’ailleurs pas la plus optimale pour charger des fichiers csv et on mettra à profit les méthodes plus classiques de lecture de fichiers.
Avec pandas, il pourra être nécessaire de caster certaines colonnes dates suite à l’import.
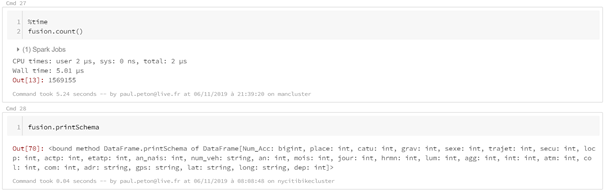
La lecture en Spark autorise l’emploi de caractères génériques ( ? ou *) pour lire et concaténer automatiquement plusieurs fichiers. Les archives .zip contenant par exemple un fichier .csv peuvent être chargées sans décompression préalable, ce qui ne sera pas le cas avec pandas.
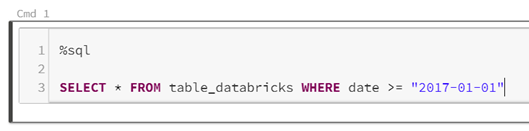
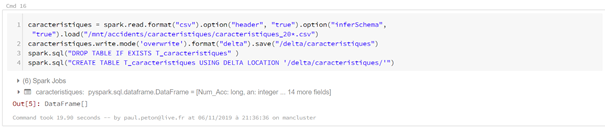
L’avantage de Databricks sera de pouvoir persister certains dataframes sous forme de vues (« tables locales ») ou de tables (« tables globales). En particulier, le format delta pourra être mis à profit. Dès lors, il devient très simple de travailler en Spark SQL pur, toujours en débutant la cellule par la commande magique %sql.
Pandas se montre ici à son avantage avec des résultats plus simples à obtenir pour connaître les dimensions du dataframe (shape) ou des informations sur le schéma et les valeurs manquantes.
En conclusion
Lorsqu’on pose à certains érudits musicaux la sempiternelle
question « Stones ou Beatles », il n’est rare d’entendre la
réponse suivante : « ni l’un, ni l’autre, mais les
Kinks ! »
A la question non moins sempiternelle « R ou
Python », je répondrai donc… Scala !
C’est en effet le langage natif de Spark et donc le plus proche du moteur
d’exécution.
Malgré tout, le choix se fera aussi en fonction de critères plus
pragmatiques comme la puissance nécessaire au traitement, le coût de travailler
sur l’exhaustivité des données (pourquoi par un échantillon
représentatif ?) ou la maîtrise des différents langages par les personnes
en charge des développements.
Depuis, la version Gen2 d’Azure Data Lake Storage est sortie (le logo a évolué). Azure Machine Learning Service est devenu un portail à part entière : ml.azure.com et depuis
Voici un aperçu des fonctionnalités en vidéo de ce qui s’appelle pour l’instant Azure Machine Learning Web Experience.