Jusqu’à présent, nous avons l’habitude d’utiliser un espace de travail Azure Databricks en nous connectant au portail, l’authentification étant réalisée par un couple login / password déclaré dans l’annuaire Azure Active Directory.
Dans un but d’automatisation des tâches, il est intéressant de se pencher sur les commandes en lignes ou CLI. Celles-ci sont documentées sur le site de Databricks. Les commandes peuvent être vues comme une surcouche de l’API REST de Databricks.
Installation du CLI Databricks
Un environnement Python est nécessaire. Nous pouvons ensuite lancer le téléchargement du package dédié avec la commande ci-dessous, depuis un terminal.
pip install databricks-cli
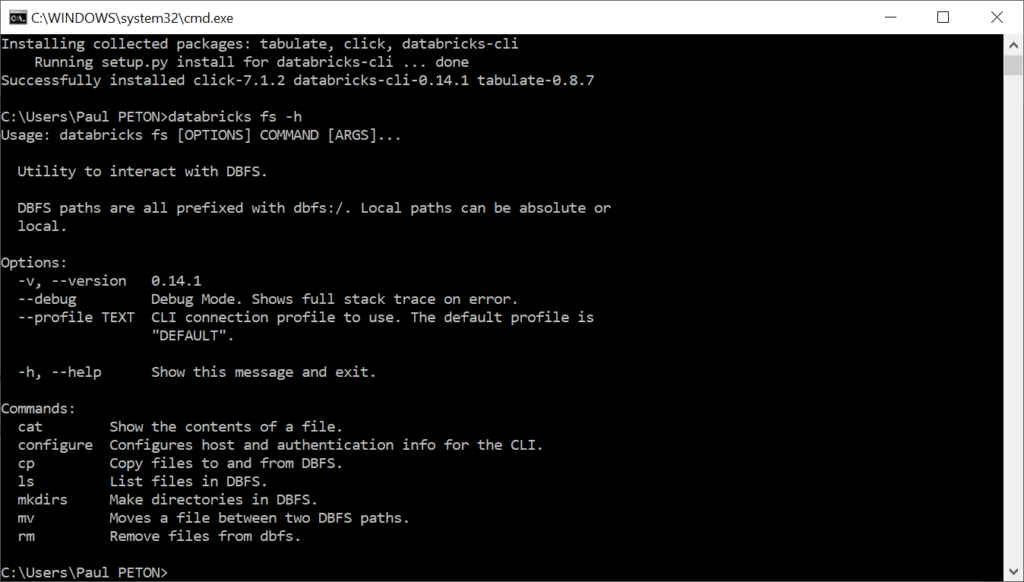
Nous vérifions dans la foulée que l’affichage de l’aide d’une commande, sur laquelle nous reviendrons plus tard, est fonctionnel.
databricks fs -h
La version installée peut être retrouvée par la commande :
databricks --version
C’est un produit qui évolue rapidement et il conviendra de le mettre à jour fréquemment, afin de bénéficier d’un maximum de fonctionnalités.
Authentification
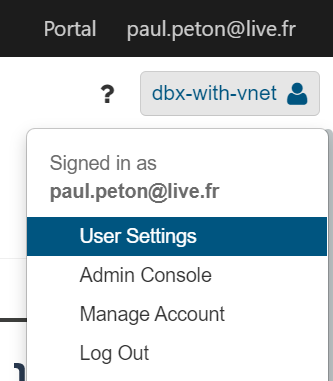
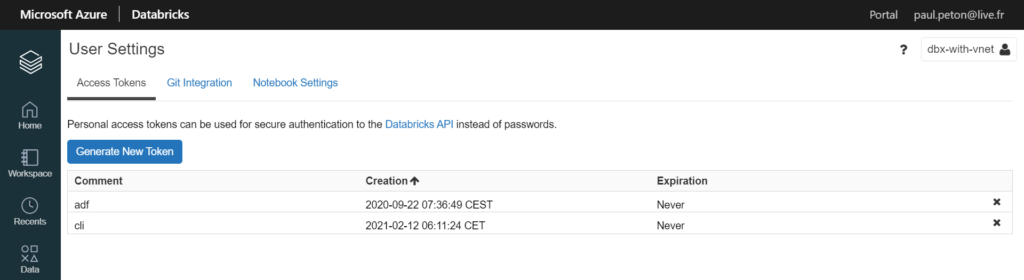
Nous allons utiliser un Personal Access Token pour nous authentifier auprès du service. Ce jeton de sécurité est obtenu sur le portail Databricks, dans le menu User Settings.
Attention à bien noter (dans un coffre-fort électronique !) le jeton obtenu, il ne sera plus possible d’afficher sa valeur par la suite.
Nous démarrons la configuration par la commande :
databricks configure --token
Deux valeurs seront attendues : l’URL de l’espace de travail, puis le token précédemment généré. L’URL pour une ressource Azure est dorénavant de la forme https://adb-XXXXXXXXXXXXXXXX.XX.azuredatabricks.net/.
Un fichier local s’écrit alors et contient les informations renseignées.
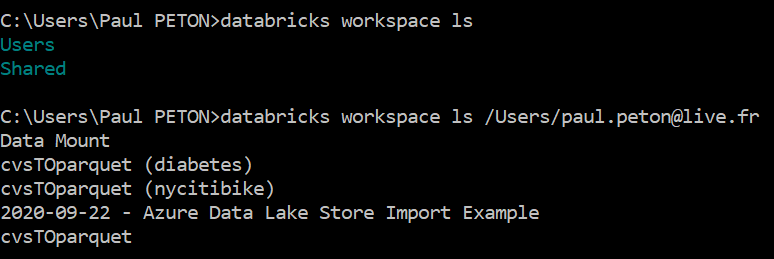
Vérifions maintenant que l’authentification est effective en lançant une commande interagissant avec l’espace de travail :
databricks workspace ls
Si nous obtenons un message d’erreur Error: b’Bad Request’, la cause peut être un mauvais enregistrement du token dans le fichier de configuration. En ouvrant celui-ci dans un éditeur de texte, nous visualisons le résultat suivant :
Remplacer les caractères SYN par la valeur du token permettra de résoudre ce problème mais demande de stocker ce secret de manière non sécurisée.
Nous pouvons maintenant lister le contenu de l’espace de travail.
Copier un fichier depuis le FileStore
Le FileStore est une zone de stockage spécifique (un dossier) du DataBricks File System (DBFS). Celui-ci nous permet de réaliser des échanges avec l’extérieur : copie de fichiers vers ou depuis le DBFS. Une documentation complète est disponible ici.
A l’aide des commandes du CLI, nous identifions un fichier que nous pouvons recopier localement.
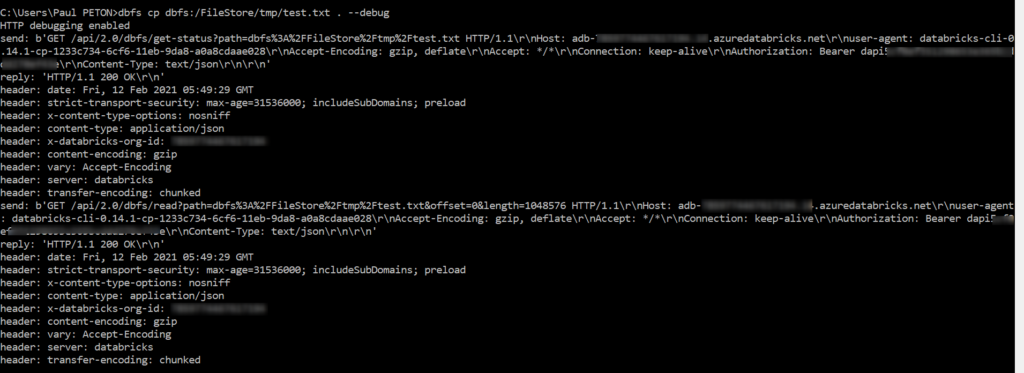
Comme le CLI est une surcouche de l’API REST de Databricks, il est intéressant de retrouver la commande initiale émise vers l’espace de travail. Nous pouvons l’obtenir en ajoutant –debug après la commande de copie.
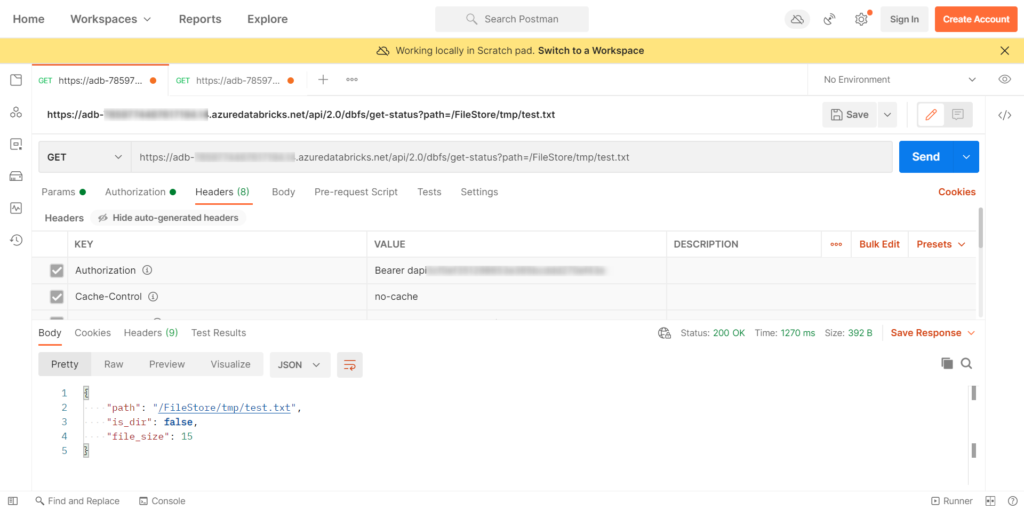
Le premier appel vérifie le statut du fichier. Il est possible d’exécuter la requête dans Postman (coller un token dans la partie Authorization).
Nous trouvons ici la taille du fichier. Il faut savoir que le contenu du fichier est converti en base 64 et nous allons ensuite mieux comprendre pourquoi.
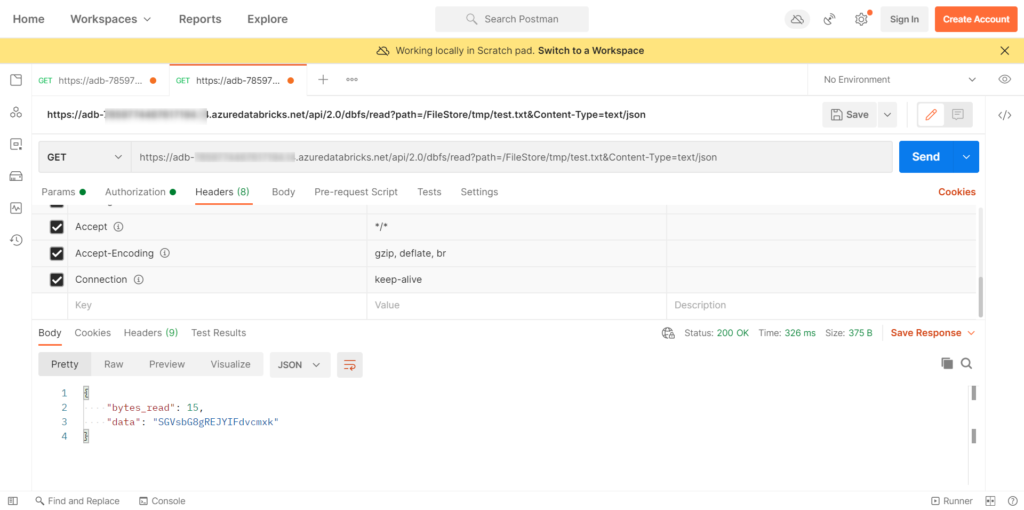
Un second appel à l’API se fait avec la méthode read et deux options &offset=0&length=1048576. Si le fichier dépasse 1 méga-octet, celui-ci est découpé en morceaux (chunks) et plusieurs appels seront nécessaires. La commande reconstitue toutefois le fichier et le décode automatiquement. Tout cela est donc transparent pour l’utilisateur !
Les services cognitifs Azure permettent de bénéficier d’algorithmes déjà entrainés pour répondre à des analyses de type « cognitives », c’est-à-dire simulant le fonctionnement du cerveau humain (raisonnement) et des sens comme la vue ou l’ouïe.
Plusieurs domaines sont couverts par ces services :
La décision
Le langage
La parole (« speech »)
La vision
Dans les domaines du texte et du langage, nous bénéficions, outre la traduction, de 4 principales fonctionnalités ;
La détection de la langue
La reconnaissance d’entités nommées
L’extraction de phrases clés
L’analyse de sentiments
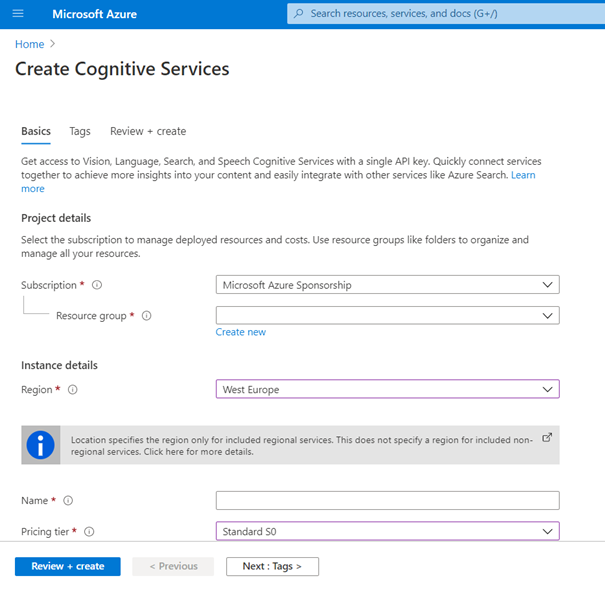
Mais avant de nous lancer, il nous faut créer une ressource Azure qui fournira une clé d’authentification auprès de l’API. Cette ressource est aujourd’hui (janvier 2021) commune à la plupart des APIs des services cognitifs Azure, ce qui simplifie son usage. On veillera toutefois, dans un environnement de production, à segmenter les ressources selon les différents usages. QnA Maker, Speech Services, Translator et Custom Vision ne sont actuellement disponibles que sous forme d’API individuelles.
Nous pouvons bénéficier de la tarification Standard S0, décrite sur ce lien.
Cette tarification se base sur des tranches de 1000 enregistrements de texte, avec un tarif dégressif selon des paliers d’enregistrements.
A la page de la ressource, nous trouvons deux informations qui seront ensuite indispensables : point de terminaison ou endpoint (celui-ci dépend de la région Azure préalablement sélectionnée) et deux clés d’authentification. Disposer de deux clés permet d’assurer une rotation lors du renouvellement des clés.
De nombreux langages de programmation permettent d’appeler les APIs des services cognitifs (C#, Python, node.js, Go, Ruby…) mais pour simplifier le propos et aller directement à l’essentiel, nous utiliserons ici le client Postman, téléchargeable sur ce lien, qui permettra d’interroger le point de terminaison et de bien détailler le rôle de chaque élément.
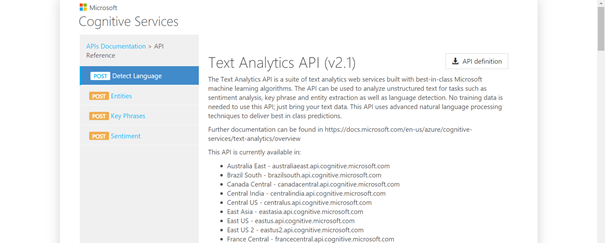
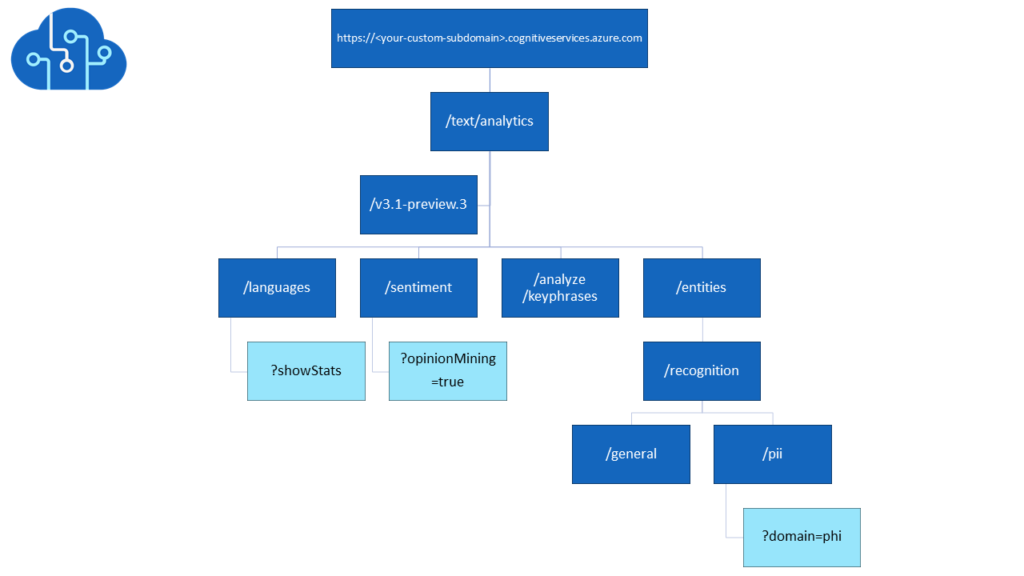
La page de documentation la plus utile sera certainement celle-ci. Nous y trouvons les différents endpoints régionaux, et dans le menu de gauche, les quatre actions possibles à partir du service cognitif Text Analytics.
Interrogation sous Postman
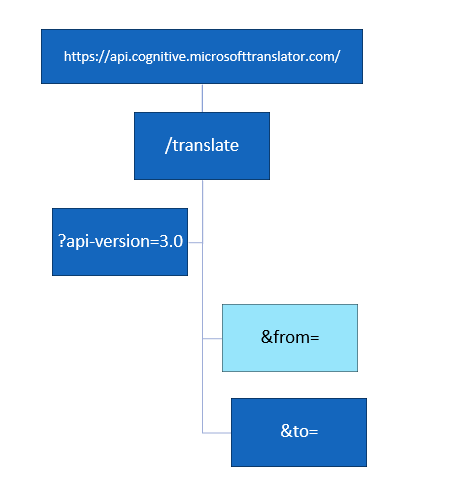
Le premier élément nécessaire sera l’URL de l’API, de la forme :
Nous adaptons cette URL à notre région, en retirant le paramètres ?showStats et en positionnant la boîte de dialogue de Postman sur POST. La version de l’API doit être précisée. A ce jour, nous utilisons la version 2.1 ou 3.0 voire la préversion 3.1 qui apporte de nouvelles fonctionnalités. Celles-ci sont détaillées dans cette documentation officielle.
Deux informations d’entêtes sont requises, sous forme de couple clé-valeur et nous les renseignons dans le menu Headers :
Le type de contenu
La clé d’authentification
En basculant sur le contenu brut (bouton « bulk edit » de l’interface), nous obtenons le script suivant :
Pour renseigner le corps de la requête (« Body »), il est également possible de basculer sur l’affichage « raw », pour un contenu de type JSON.
Le schéma attendu nous est à nouveau donné par la page de documentation de l’API.
Pour la détection du langage, chaque document est attendu, au sein d’une liste marquée par des crochets, sous la forme de trois éléments :
countryHint (facultatif)
id
text
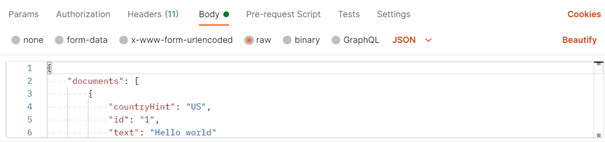
Pour une seule phrase, le contenu minimal de ce corps est le suivant :
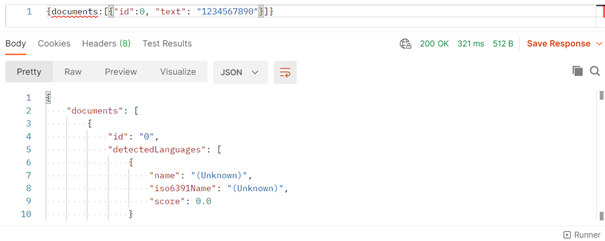
{documents:[{"id":0, "text": "dans quelle langue cette phrase est-elle écrite ?"}]}
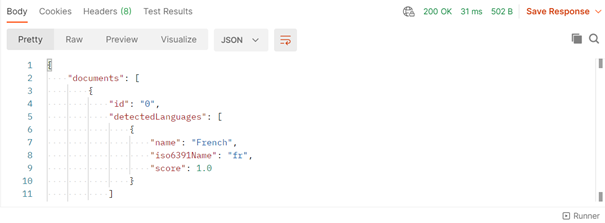
La réponse obtenue, de statut 200 OK, prend alors la forme ci-dessous :
Le score donne un indicateur de confiance, entre 0 et 1, de la prévision réalisée. En pratique, un doute sera émis dès que le score sera inférieur à 1.
L’information countryHint peut être renseignée par un code sur deux lettres représentant le pays d’où est issu le texte, ce qui permet de retirer d’éventuelles ambiguités lorsqu’un même mot est utilisé dans plusieurs langues. Le champ peut être soit omis, soit renseigné comme une chaîne vide countryHint = “”.
Lorsqu’il n’est pas possible d’identifier un langage, la réponse otenue sera le mot « (Unknown) ».
Le schéma ci-dessous résume les principales syntaxes d’interrogation de l’API Text Analytics.
L’API Translator
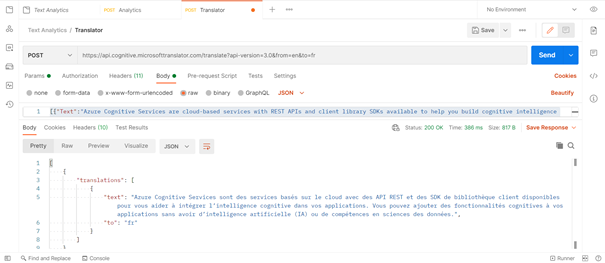
Dans la foulée de la reconnaissance de la langue, il est logique de rechercher à traduire le texte. Nous appelons ici une autre API : Translator, réalisant ci-dessous une traduction en français.
[{"Text":"Azure Cognitive Services are cloud-based services with REST APIs and client library SDKs available
to help you build cognitive intelligence into your applications.
You can add cognitive features to your applications without having artificial intelligence (AI) or data science skills."}]
Nous obtenons la sortie suivante.
Si besoin, la langue d’origine peut être précisée et ce n’est pas le mécanisme d’auto-détection qui est mis en œuvre.
La documentation détaillée de l’API est disponible sur ce GitHub et un extrait est illustré ci-dessous.
Un niveau de tarification supérieur à S0 est nécessaire, sinon le message suivant apparaît :
The Translate Operation under Translator Text API v3.0 is not supported with the current subscription key
and pricing tier CognitiveServices.S0.
Les méthodes l’API Text Analytics
Voyons maintenant les trois autres méthodes disponibles avec l’API Text Analytics.
Celles-ci ne seront pas toujours disponibles en français, ou dans d’autres langues que l’anglais. La vérification peut être faite, en fonction de la version de l’API, sur cette page.
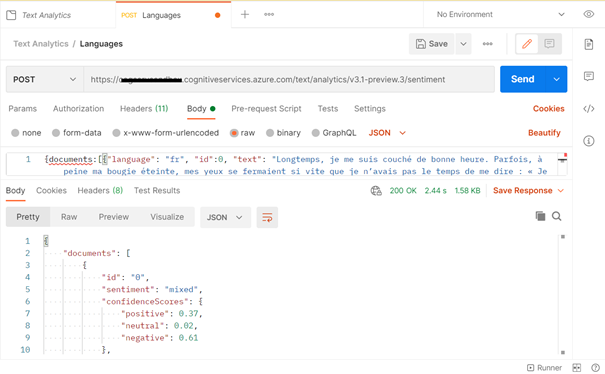
L’analyse de sentiments évalue un texte dans sa totalité en se basant sur le poids des mots utilisés, pour attribuer trois scores : positif, neutre, négatif. Un sentiment global est donné sous forme de texte : positive, mixed, negative ou neutral si aucun des trois cas précédents n’est vérifié.
Pour obtenir l’exploration des opinions, uniquement en anglais à ce jour, nous ajoutons à la fin de l’URL : ?opinionMining=true
{documents:[{"language": "en", "id":0, "text": "Very welcome and advice from the guests. Very clean accommodation. We recommend it!"}]}
Nous obtenons alors, lorsqu’une relation de type opinion est détectée, un groupe d’informations supplémentaires intitulé « opinions », disposant de deux scores, positif et négatif.
L’extraction de phrases clés permet d’identifier des éléments (mots ou groupes de mots) les plus importants au sein d’un texte (phrase ou ensemble de phrases). On pourrait voir cela comme une extension d’un preprocessing visant à retirer les mots outils (« stop words »).
Nous obtenons le résultat suivant avec la première phrase du roman de Marcel Proust, A la Recherche du Temps Perdu.
La reconnaissance d’entités nommées se fait avec la syntaxe :
recognition/general
Nous retrouvons certains éléments ressortant dans les phrases clés, pour lesquels une catégorie et sous-catégorie sont données, associées à un score de confiance. A ce jour (février 2021), c’est la version 2.1 de l’API qui est utilisée en langue française, même si la version 3.0 est indiquée dans l’URL.
La liaison d’entités (non disponible pour l’instant en français) ajoute une information supplémentaire à la reconnaissance générale d’entité en spécifiant l’URL d’une page Wikipedia dédiée à cette entité.
Les Informations d’identification personnelle (PII) sont des patterns correspondant à différents éléments : numéro de téléphone, adresse e-mail, adresse postale, numéro de passeport.
Nous remarquons que la sortie donne un élément redactedText qui remplace les éléments reconnus comme informations personnelles par des étoiles (*).
Un domaine (optionnel) peut être précisé pour obtenir les informations (personnelles) médicales mais il n’existe à ce jour pas de documentation explicitant les éléments pouvant être identifiés.