
Nous avons déjà évoqué sur ce blog le driver JDBC permettant d’écrire depuis un notebook Azure Databricks dans une base de données managée ou encore comment utiliser Polybase pour pérenniser une table du métastore Databricks dans Azure SQL DWH (aujourd’hui Synapse Analytics).
Cette action d’écriture demande souvent un niveau de ressource suffisamment élevé, tout comme l’import de données réalisé dans un dataset Power BI. Le reste du temps, une puissance plus faible peut être tout à fait acceptable. Et comme le niveau de facturation est lié au niveau de la ressource, pouvoir maîtriser par code, et non manuellement depuis l’interface, le scape up ou scale down de sa ressource peut s’avérer très intéressant dans une démarche d’optimisation des coûts (FinOps).
Nous nous plaçons ici dans un scénario de pipeline de transformation de données réalisé par Azure Databricks puis d’import dans un dataset Power BI. L’actualisation par API REST de ce dernier est détaillé dans cet article.
Au démarrage de notre pipeline, nous souhaitons augmenter la puissance (scale up) et ceci peut se faire avec des instructions PowerShell documentées ici.
Il est possible d’exécuter un script PowerShell depuis Azure Data Factory à l’aide de ce qu’on appelle une “custom activity“. Celle-ci s’appuie sur un service lié de type Azure Batch. Et ce service n’est pas gratuit, voire même relativement cher pour ce que l’on souhaite réaliser.
Nous optons donc pour la programmation d’une Azure Function, qui supporte le langage PowerShell ! Nous choisissons le type de fonction Trigger HTTP.
Dans Visual Studio Code, nous obtenons l’arborescence ci-dessous.
Le code principal de la fonction doit se trouver dans le fichier run.ps1.
Un premier point important consistera à renseigner les dépendances de librairies PowerShell dans le fichier requirements.psd1. Une combinaison fonctionnelle est la suivante :
# This file enables modules to be automatically managed by the Functions service
# See https://aka.ms/functionsmanageddependency for additional information.
#
@{
'Az.Accounts' = '2.1.2'
'Az.Sql' = '2.11.1'
}
Second élément indispensable pour l’intégration dans une activité Web de Data Factory : le retour de la fonction doit obligatoirement être un objet JSON. Nous terminons donc la fonction par le code ci-dessous :
$body = @{name = 'Scale done !'} | ConvertTo-Json
#Associate values to output bindings by calling 'Push-OutputBinding'.
Push-OutputBinding -Name Response -Value ([HttpResponseContext]@{
StatusCode = [HttpStatusCode]::OK
Body = $body
})
Une fois la fonction publiée sur Azure, nous pouvons définir le pipeline complet.
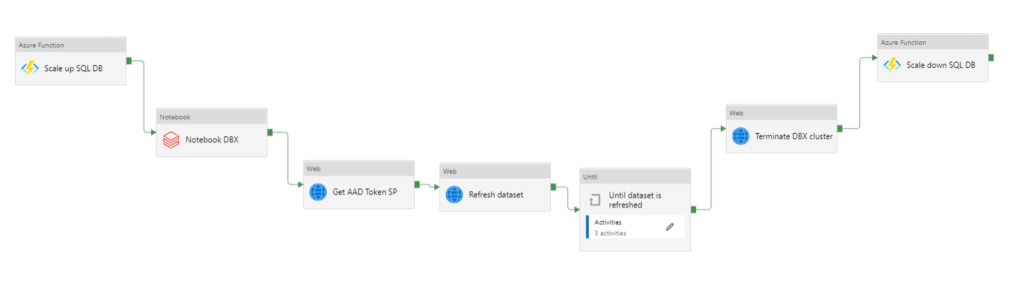
La fonction Azure étant pensée de manière paramétrable, nous pouvons donner le niveau de ressource comme un élément de l’URL appelée par la méthode POST. Nous utilisons dans l’exemple ci-dessous le niveau “S” suivi d’un chiffre.
Ce niveau modifiera automatiquement le configuration de la ressource Azure SQL DB, en mode de tarification basé sur les DTUs (et non les vCores).

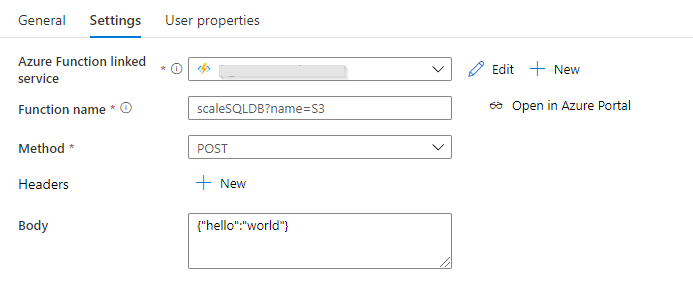
L’activité de traitement de la donnée, ici portée par Azure Databricks, réalise le démarrage d’un cluster de type interactif. Lorsque le traitement est terminé, le cluster peut s’éteindre automatiquement si la fonctionnalité “terminate after…” a été mise en place. Mais il faut ici attendre que l’import du dataset Power BI soit terminé ! Nous gérons donc la fin du cluster Databricks au moyen de l’API dédiée, dans une activité Web.
La syntaxe utilisée est la suivante :
POST https://adb-XXXXXXXXXXXXXXXX.X.azuredatabricks.net/api/2.0/clusters/delete
Les informations nécessaires seront : l’URL du workspace, un personal token d’authentification et l’identifiant du cluster.
Dans un optique d’optimisation des coûts, nous positionnons comme dernière activité du pipeline le scale down de la base de données.
Nous obtenons ainsi une chaîne complète optimisée sur l’enchainement des tâches et sur les coûts engendrés par les services PaaS.