Si vous avez provisionné un service Azure Machine Learning, vous vous êtes certainement aperçu que celui-ci ne venait pas seul au sein du resource group.
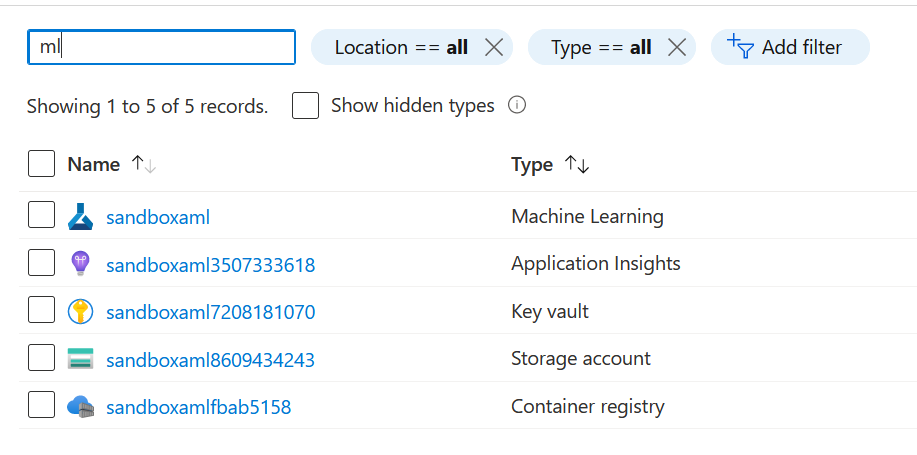
Il est en effet accompagné par un compte de stockage qui servira à enregistrer des éléments comme des datasets ou bien les artefacts liés aux modèles. Le container registry servira quant à lui à conserver les images Docker générées pour les services web prédictifs. Le Key Vault jouera son rôle de stockage des clés, secrets ou passphrases. Reste le service Application Insights.
Application Insights, pour quoi faire ?
Application Insights est une branche du service Azure Monitor qui permet de réaliser le monitoring d’applications comme des applications Web, côté front mais aussi back. De nombreux services Azure (Azure Function, Azure Databricks dans sa version enterprise, etc.) peuvent être surveiller grâce à Application Insights.
Le détail des éléments supervisés est disponible dans la documentation officielle.
La manière la plus concrète d’obtenir un résultat avec ce service est sans doute d’utiliser l’interface Log Analytics. Celle-ci se lance en cliquant sur le bouton logs.
L’interface de Log Analytics nous invite à écrire une nouvelle requête dans le langage KustoQL, dont la syntaxe est disponible ici. Ce langage est aussi utilisé dans l’outil Azure Data Explorer.
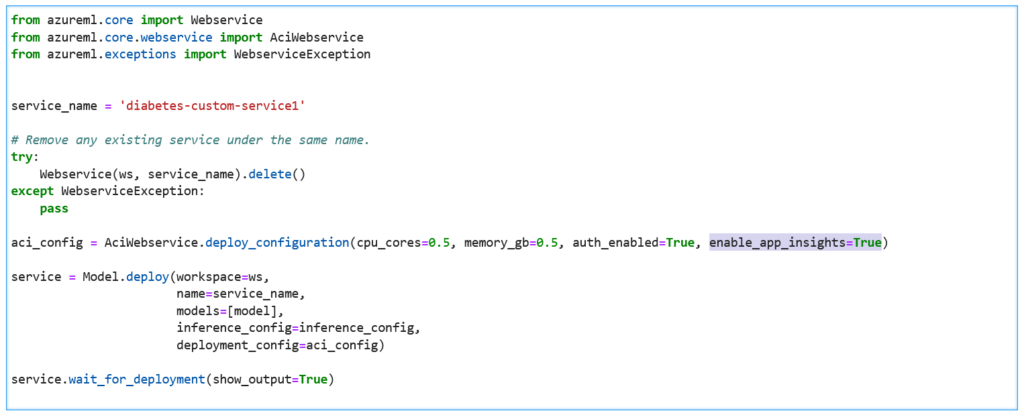
Mais avant de pouvoir obtenir des résultats, nous devons déployer un service web prédictif sur lequel App Insights a été activé. Nous le faisons en ajoutant la propriété enable_app_insights=True dans la définition de la configuration d’inférence.
Il faut également que du texte soit “imprimé” au moment de l’exécution de la fonction run(), tout simplement à l’aide de la fonction print().

Quelques exemples de notebooks sont disponibles dans ce dépôt GitHub.
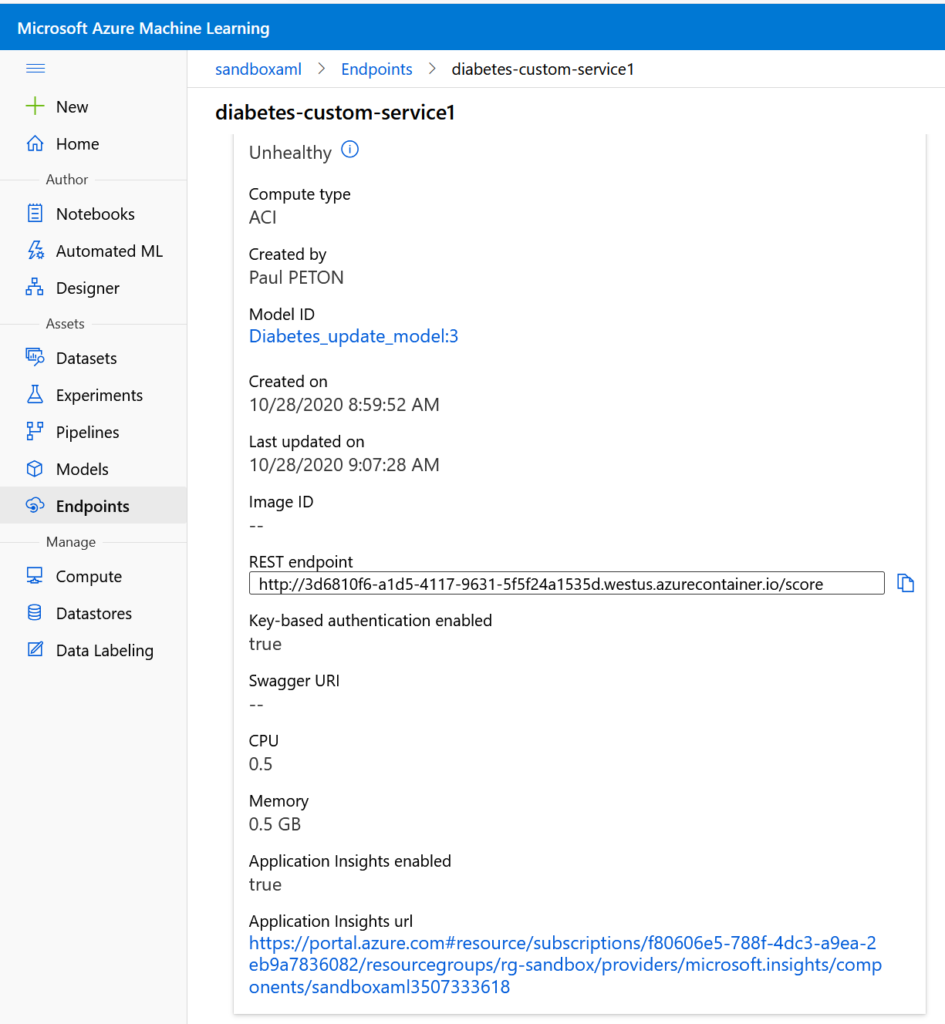
Après publication ou mise à jour du service web, une URL apparaît dans l’interface et donne accès au service App Insights correspondant.
Exploiter Log Analytics
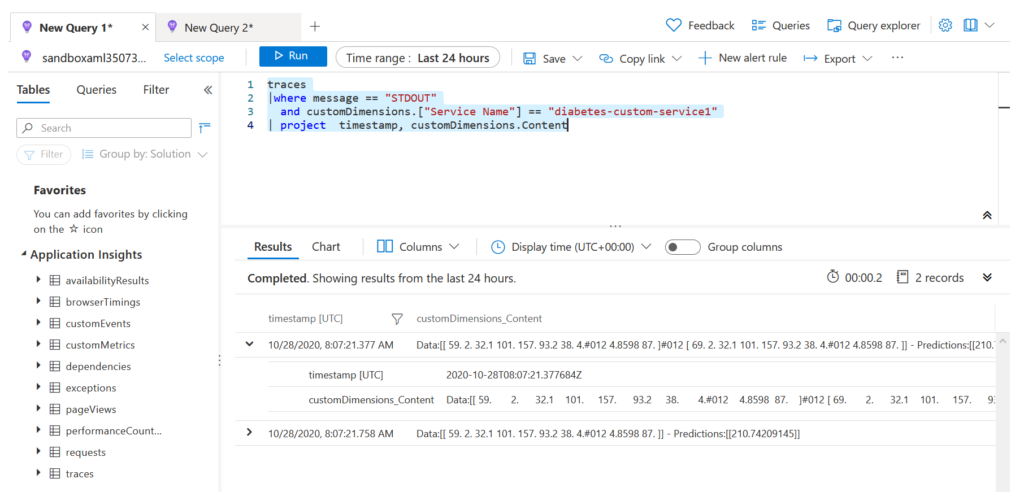
Il est maintenant possible de lancer une première requête dans l’interface Log Analytics, avec la syntaxe suivante :
traces |where message == "STDOUT" and customDimensions.["Service Name"] == "diabetes-custom-service1" |project timestamp, customDimensions.Content
Nous obtenons le résultat ci-dessous.
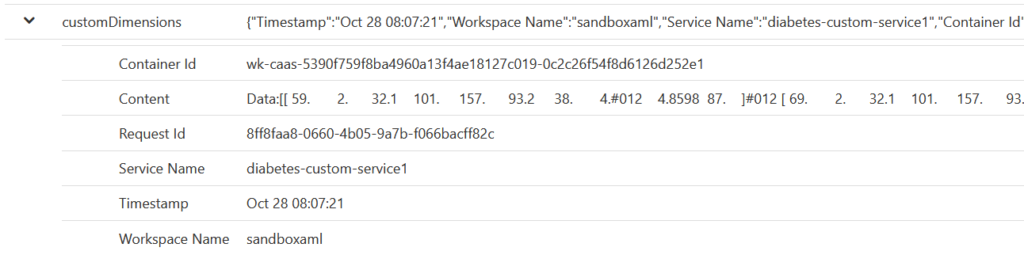
Le service Azure Machine Learning a créé une “custom dimension“, nouvel objet au format JSON, interrogeable par le langage KustoQL. Celui-ci contient des informations comme l’identifiant du container associé, le nom de l’espace de travail ainsi que du service déployé.
Afin de conserver les logs sur la durée, un mécanisme d’export continu pourra être mis en œuvre et stockera les informations sur un compte de stockage.