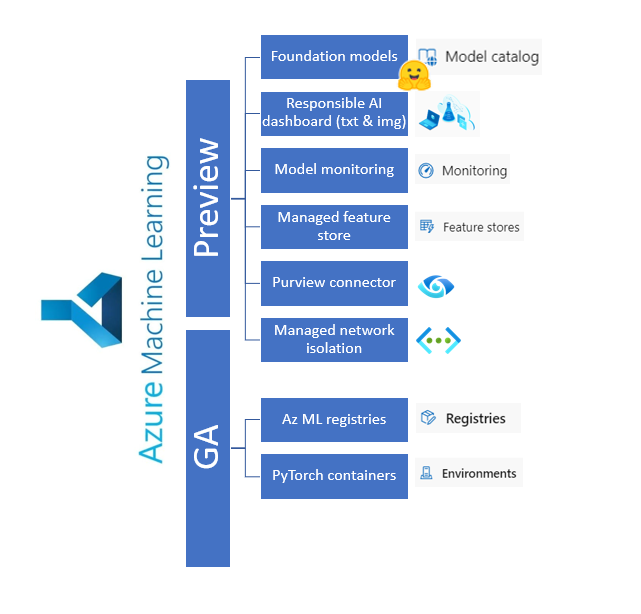
Entre la déferlante OpenAI et le renouveau de la data platform avec Microsoft Fabric, on pouvait craindre qu’il ne reste que la portion congrue pour Azure Machine Learning. Mais c’est loin d’être le cas ! Faisons un tour sur les différentes annonces qui contribuent à faire d’Azure ML une véritable plateforme pour le Machine Learning en production.
En préversion publique
Rappelons que lors de la phase dite de preview et avant la disponibilité générale (general availability), les services ne sont pas intégrés dans le support proposé par Microsoft. L’utilisateur doit également être conscient que les fonctionnalités, l’interface et bien sûr la tarification peuvent encore évoluer.
Veillez bien à activer les préversions à l’aide du menu dédié “Manage preview features“.
Support for foundation models
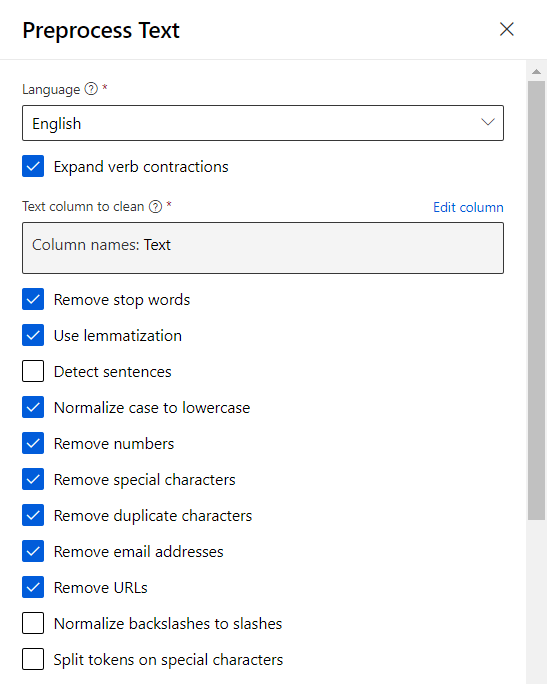
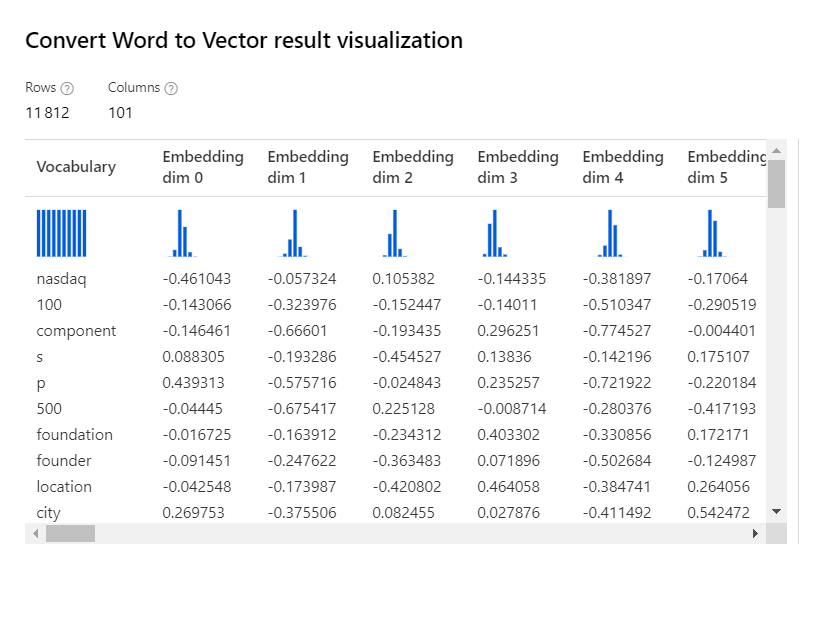
L’époque où les Data Scientists développaient leur propre modèle sur leur laptop semblerait presque révolue ! En effet, des modèles Open Source très puissants sont maintenant disponibles au travers de hubs comme Hugging Face qui se place ici en partenariat avec Microsoft. Il devient possible de déployer ces modèles au sein du workspace Azure Machine Learning pour les utiliser sur des tâches d’inférence.
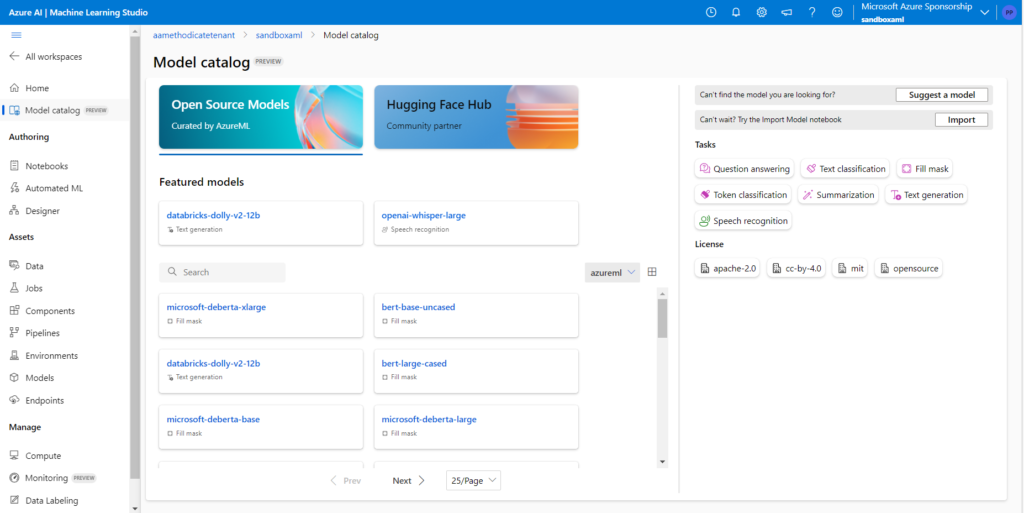
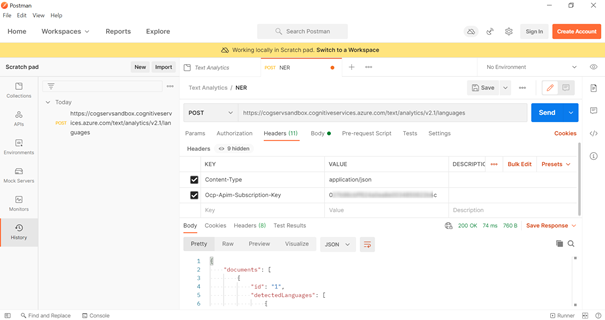
Après déploiement sous forme de managed online endpoint, nous passons donc directement dans le menu des points de terminaison (endpoints) pour retrouver les modèles disponibles.
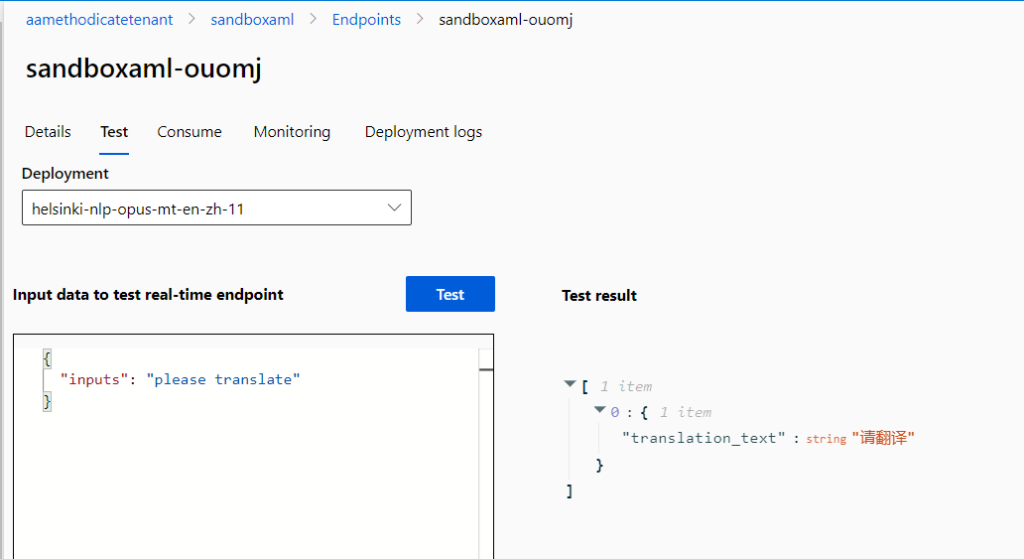
Certains modèles proposent aussi une interface de test sans déploiement.
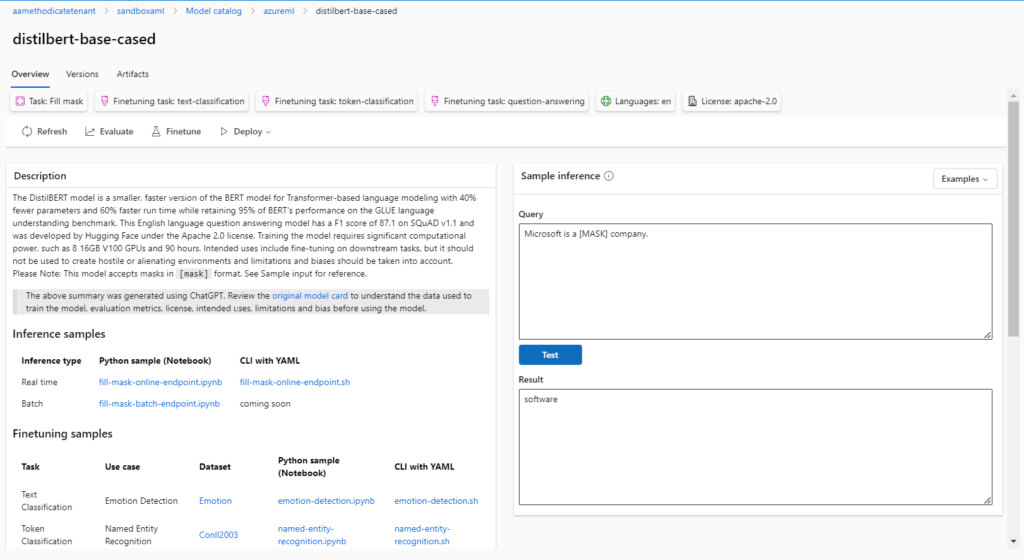
Responsible AI dashboard support for text and image data
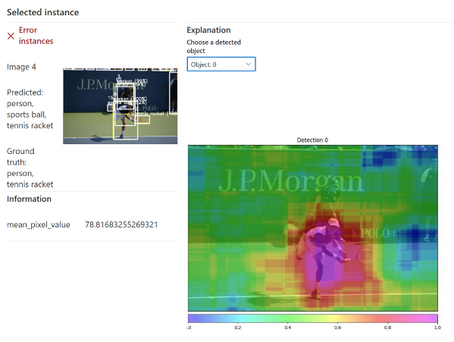
Nous connaissions déjà le tableau de bord pour une AI responsable, construit autour de briques Open Source sur l’explicabilité et l’interprétabilité des modèles. Je vous recommande d’ailleurs cet excellent article sur son utilisation.
Le tableau de bord s’étend maintenant aux modèles de Computer Vision (images) et de NLP (textes).
Model monitoring
La fonction “Dataset monitors”, toujours en préversion, réalise déjà une détection de dérive sur les nouvelles données qui pourraient être proposées à l’inférence sur un modèle entrainé. Il est important de lever des alertes lorsque la distribution des données d’entrée change et diffère de celle des données d’entrainement. Pour autant, un autre type de dérive est possible : celle du lien entre la variable cible et les variables d’entrée (model drift). C’est ici qu’entre en jeu un nouvel outil, dans un menu dédié “Monitoring“.
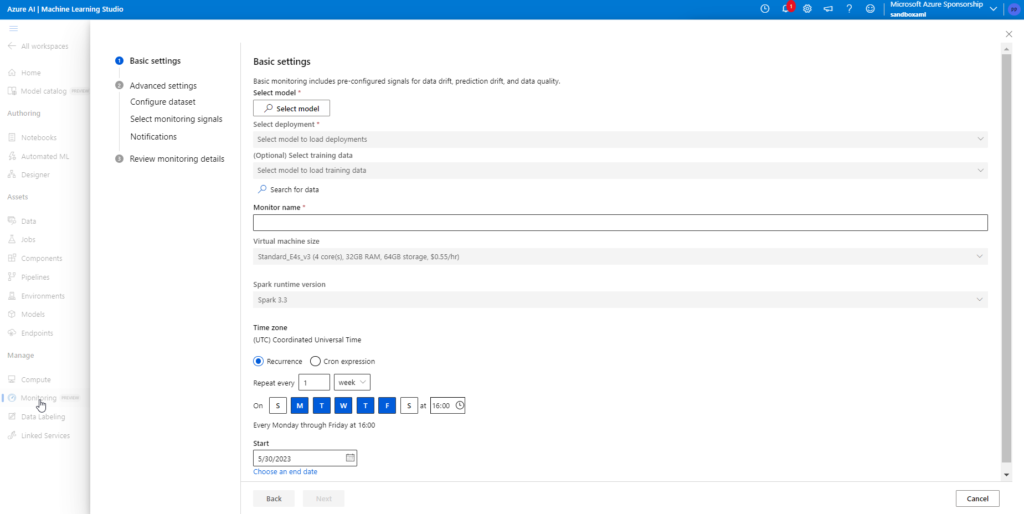
Il est possible ici de choisir les différents éléments mis sous contrôle et qui seront visibles dans des tableaux de bord dédiés.
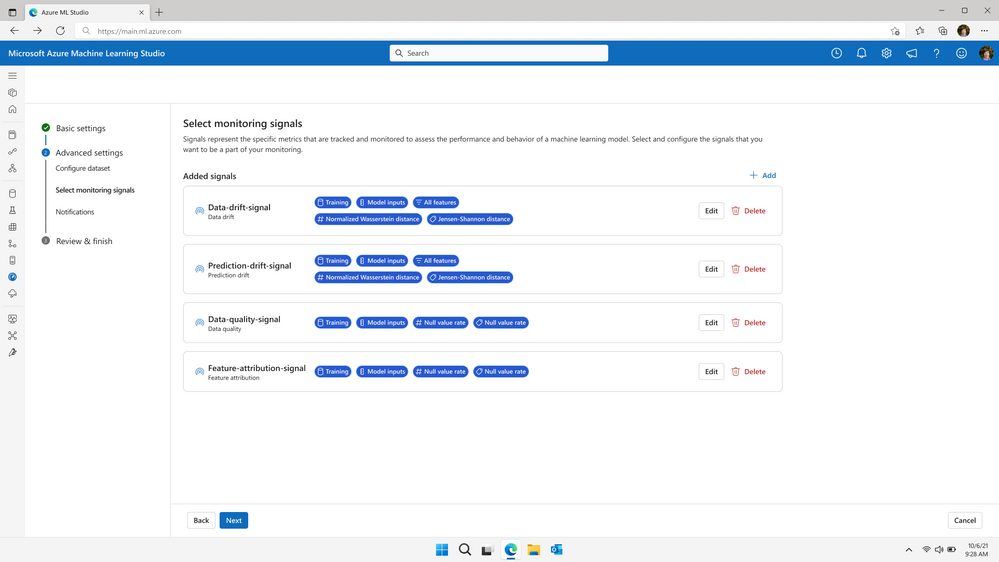
Les quatre fonctionnalités incluses sont :
- Data drift (dérive des données) : détection de changements dans la distribution des données
- Prediction drift (dérive des prédictions) : changements significatifs dans la distribution des prédictions d’un modèle
- Data quality (qualité des données) : détection des problèmes de données tels que les valeurs nulles, les violations de plage ou incohérences de type
- Feature attribution drift (dérive de l’attribution des caractéristiques) : détection des changements d’importance des features dans le modèle
Cette fonctionnalité native, sans intégration d’un composant tiers, est une avancée majeure pour la plateforme et son usage pour supporter les modèles en production.
Microsoft Purview connector
L’outil de data discovery, cataloging et lineage Microsoft Purview s’enrichit d’un connecteur pour Azure Machine Learning. Il sera maintenant possible d’établir le lien entre dataset d’entrainement, modèle, job et prévisions.
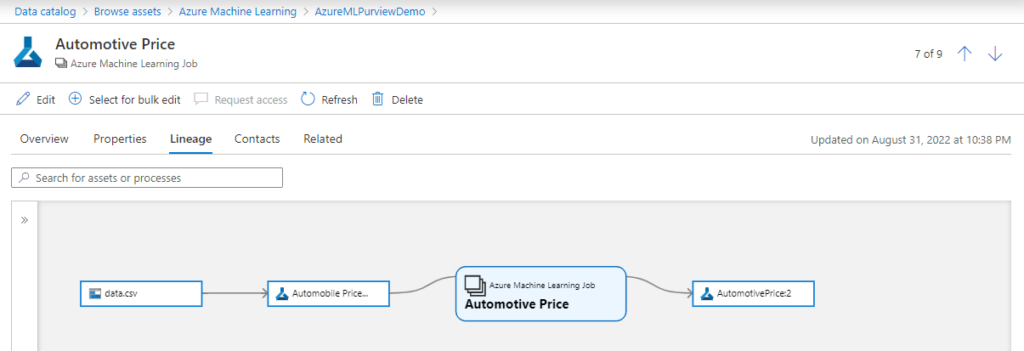
Le rêve des Data Scientists reste sans doute d’arriver à un niveau de détail du linéage montrant l’impact des features brutes sur les résultats, au travers de l’étape de feature engineering (travail sur les données brutes pour fournir des prédicteurs plus efficaces). Nous nous tournons pour cela vers un autre outil, attendu depuis longtemps dans une version managée : le feature store.
Azure ML managed feature store
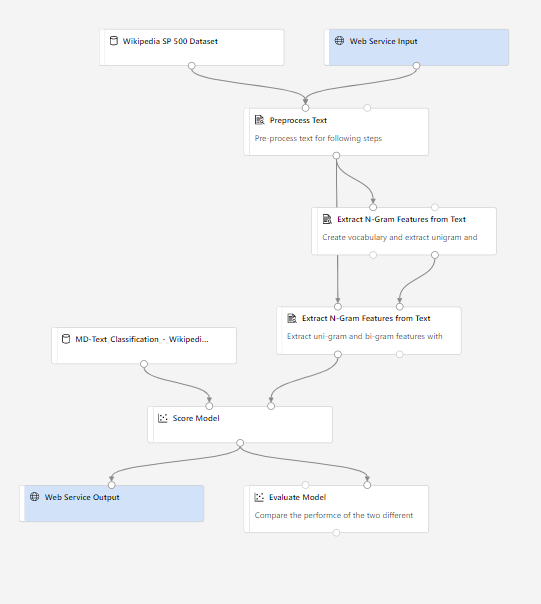
Le feature store est une composante indispensable dans une architecture MLOps qui partage plusieurs projets de Machine Learning et surtout des préparations de données communes. Le schéma ci-dessous, issu de la documentation officielle, résume les utilisations potentielles du feature store.
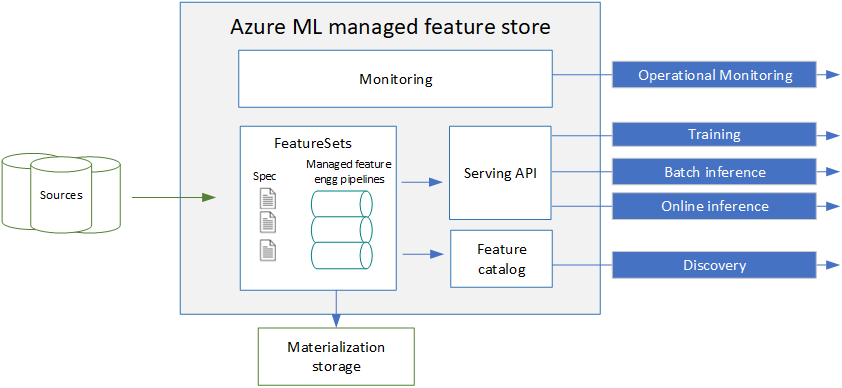
Premier point important : nous sommes à un niveau “supérieur” à celui des workspaces Azure ML (voir la logique des registries présentée ci-dessous) et nous pouvons donc imaginer partager des features et leur préparation entre workspaces ou entre modèles.
Nous remarquons ici l’utilisation du framework de calcul Apache Spark, qui sera sûrement utilisé pour transformer les données brutes en features enrichies.
La matérialisation va permettre de stocker les features dans une ressource de type Blob Storage ou Data Lake Gen2.

Ensuite, nous pourrons définir des feature sets au niveau des modèles. Ceux-ci se définissent par une source, une fonction de transformation et des paramètres de matérialisation optionnels.
Les différentes manipulations seront réalisées au moyen d’un nouveau SDK Python : azureml-featurestore (voir ce premier tutoriel).
Managed network isolation
Si vous vous êtes déjà confrontés à la complexité de déployer Azure ML, ses ressources liés et les services qui doivent communiquer avec, dans un réseau privé, cette nouvelle devrait vous réjouir.
Le réseau virtuel managé va ainsi contenir les compute instances, compute clusters et Spark serverless. Les règles de trafic sortant (outbound) et les points de terminaison privés (private endpoints) seront déjà configurés.
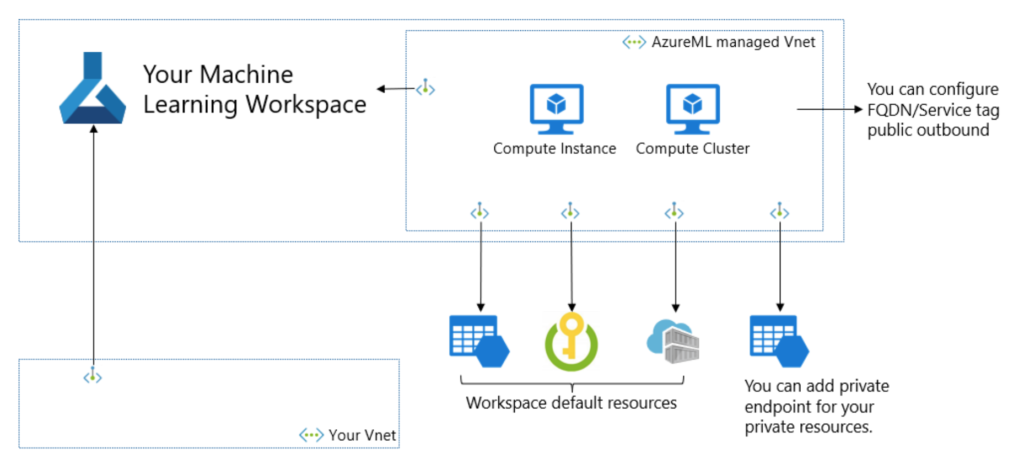
Le déploiement d’un tel workspace ne semble pas disponible au travers du portail Azure, il faudra donc passer par exemple par une commande Azure CLI comme ci-dessous :
az ml workspace create --name ws --resource-group rg --managed-network allow_only_approved_outbound
En disponibilité générale (“GA”)
Azure Machine Learning registries
L’approche MLOps nécessite de travailler avec plusieurs environnements : développement, qualification (ou UAT) et production a minima. Jusqu’ici, nous pouvions hésiter entre créer différents pipelines au sein d’un même workspace Azure ML (environnements non isolés d’un point de vue sécurité) ou bien créer des ressources séparées (difficulté de transfert des livrables entre environnements). Il manquait un niveau de gestion “supérieur” à celui des workspaces Azure Machine Learning.
Les registres permettent de partager entre workspaces des environnements (distribution de l’OS et librairies), des modèles, des jeux de données et des components.
Azure Container for PyTorch
PyTorch est le framework choisi par Microsoft pour le Deep Learning (face à TensorFlow chez Google par exemple). Il est maintenant possible d’utiliser des containers déjà paramétrés pour exécuter ce type de code.
Et bientôt en préversion
Il ne vous a pas échappé que le prochain métier en vogue (au moins sur les profils LinkedIn) allait être celui de promptologue ou prompt engineer. A mi-chemin entre le développeur no code et le linguiste, cette personne devra maîtriser les hyperparamètres des modèles génératifs (l’aspect déterministe, dit “température”, par exemple), la méthodologie naissante autour des cycles itératifs et surtout l’art du “langage naturel” pour exprimer clairement une intention.
La lecture de la documentation et les quelques démos visibles nous font penser qu’il s’agira d’un véritable outil de CICD (Continuous Integration Continuous Deployment) pour le prompting ! En effet, nous allons pouvoir :
- tester, comparer, reproduire des prompts entre eux
- évaluer les prompts grâce à une galerie d’outils déjà développés
- déployer les modèles et les messages systèmes dans différents environnements (dev, UAT, prod par exemple)
- monitorer les modèles en production
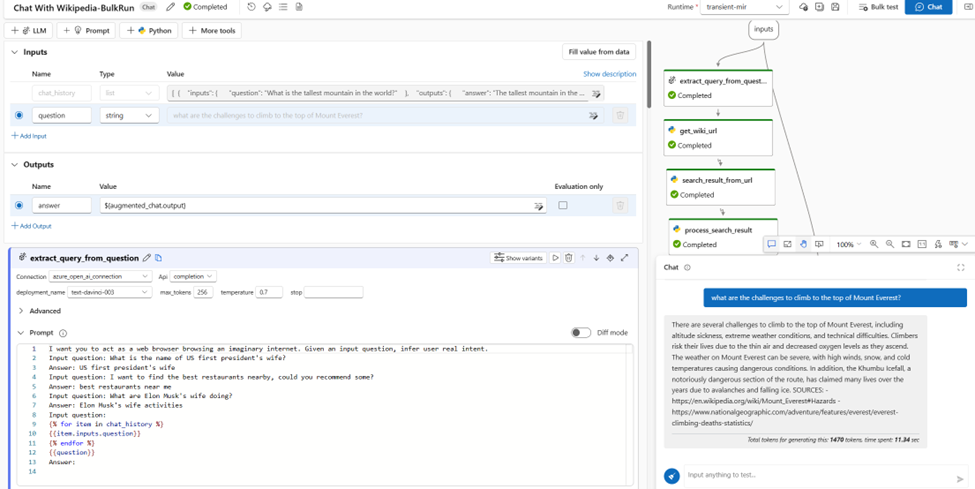
Il faut noter ici que le prompting semble déjà une discipline très mature chez Microsoft qui a anticipé tous les besoins des futurs prompt engineers.
Les chat bots étant un cas d’usage fréquent des LLM, il est intéressant de retrouver la logique de pipeline visuel, connue depuis les débuts d’Azure Machine Learning.
Et en dehors d’Azure ML
Ajoutons à cela les autres annonces liées à l’intelligence artificielle au sens large :
- l’essor du service Azure OpenAI, toujours en preview (mai 2023), avec l’ajout des plugins vers des applications tierces et la possibilité d’avoir une capacité dédiée (Provisioned Throughput Model) vous mettant à l’abri des “voisins bruyants”
- le support de DataRobot 9.0, plateforme concurrente qui pourrait ainsi bénéficier d’Azure pour des scénarios de production en entreprise
- une base de type “vector DB” ajoutée à Azure Cognitive Search en préversion privée (mai 2023), accessible sur formulaire
- le nouveau service de modération Azure Content Safety
La partie Content Safety est un nouveau service cognitif, dans la catégorie Decision.
Il s’agit d’un service de modération de contenu pour lequel un studio dédié sera disponible à l’URL suivante : https://contentsafety.cognitive.azure.com et qui sera associé à un SDK documenté ici. Il s’agit d’identifier les contenus, créés par les utilisateurs ou bien par une IA générative, tombant dans les catégories suivantes : hate, sexual, violence, self-harm. Quatre niveaux de sécurité sont alors associés à ces contenus, en fonction du contexte : safe, low, medium, high.
Nous voyons enfin apparaître une nouvelle dénomination : Azure AI Studio.
Nous savons que les noms de produits changent souvent chez Microsoft et souvent, les noms expriment une démarche sous-jacente. Le service Azure OpenAI a été présenté comme un service parmi les autres services cognitifs. Maintenant, les différents studios sont préfixés par “Azure AI |” qui unifiera les différentes offres autour de l’intelligence artificielle.
Maintenant, place à la pratique, et à de prochains billets de blog, pour se faire une véritable idée de l’impact de chacune de ces annonces.
Retrouvez l’ensemble des blogs officiels de Microsoft concernant ces annonces du 23 mai 2023 sur ce lien.