
L’API d’Azure Databricks permet de réaliser de nombreuses actions au moyen de commandes émises au travers d’une URL, de type GET ou POST. La documentation complète est disponible sur le site de Microsoft ou bien sur celui de Databricks.
Un premier exemple prend la forme ci-dessous et permet d’obtenir des informations détaillées sur un cluster :
GET https://<databricks-instance>/api/2.0/clusters/get?cluster_id=<cluster-id>
Les identifiants nécessaires de l’espace de travail et du cluster Databricks peuvent être obtenues en se rendant sur la page Web du cluster.
Bien sûr, Databricks ne se limite pas à des clusters, il faut des notebooks contenant du code et ceux-ci sont pilotés par des jobs. Pour imaginer un scénario paramétrable, nous définissons des widgets dans le notebook, ce qui permettra de passer les valeurs de ces paramètres aux jobs.
parquet_file = dbutils.widgets.get("pParquetFile")
limit = int(dbutils.widgets.get("pLimit")
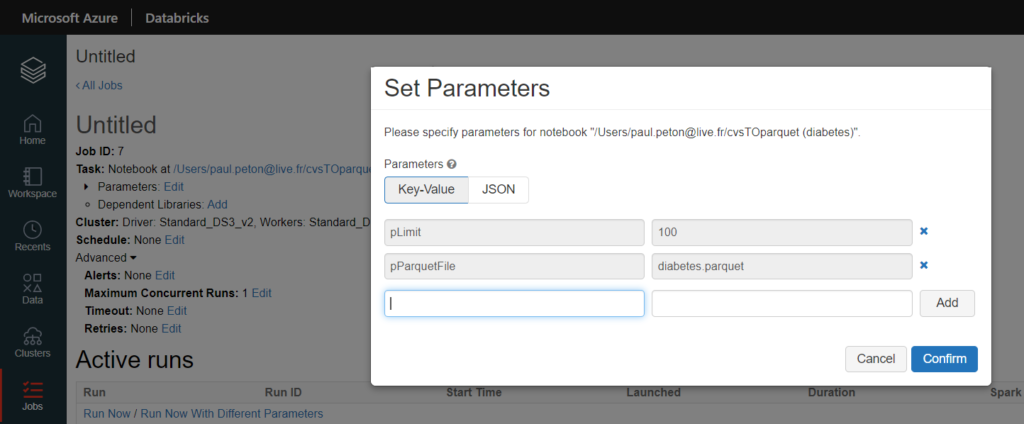
La définition du job se fait dans l’interface dédiée et les paramètres peuvent y être déclarés. Il faut noter ici l’identifiant du job, nous en aurons besoin par la suite.
Sauf à planifier le job, ces étapes resteront manuelles et les valeurs des paramètres seront à préciser à chaque exécution.
En intégrant différentes instructions dans un script PowerShell, nous pouvons élaborer le scénario suivant :

Le code correspondant est détaillé ci-dessous :
$param1 = "abc"
$param2 = 123
$limitRows = 100
$dbxPAT = "dapixxxxxxxxxxxxxxxxxxxxx"
$dbxBearerToken = "Bearer " + $dbxPAT
$dbxWorkspaceURL = "https://adb-00000000000000000.0.azuredatabricks.net/"
$clusterID = "0000-000000-xxxxx000"
$jobID = 42
$localPath = "C:\temp\"
$filePath = $localPath+$fileName
$headers = New-Object "System.Collections.Generic.Dictionary[[String],[String]]"
$headers.Add("Authorization", $dbxBearerToken)
Write-Output "Cluster status"
$URL = $dbxWorkspaceURL + "api/2.0/clusters/get?cluster_id="+$($clusterID)
$responseCluster = Invoke-RestMethod $URL -Method 'GET' -Headers $headers
$clusterState = $responseCluster.state
Write-Output "Cluster state :" $clusterState
If($clusterState -ne "RUNNING")
{
Write-Output "Start cluster"
$URL = $dbxWorkspaceURL + "api/2.0/clusters/start"
$body = @{"cluster_id"=$clusterID} | ConvertTo-Json
$responseStart = Invoke-RestMethod $URL -Method 'POST' -Headers $headers -Body $body
$clusterState = $responseStart.state
While($clusterState -ne "RUNNING")
{
Write-Output "Please wait one minute more...the cluster is starting"
Start-Sleep -Seconds 60
$URL = $dbxWorkspaceURL + "api/2.0/clusters/get?cluster_id="+$($clusterID)
$responseStart = Invoke-RestMethod $URL -Method 'GET' -Headers $headers
$clusterState = $responseStart.state
Write-Output $clusterState
}
}
Write-Output "Run job"
$body = @{
"job_id"= $jobID
"notebook_params"= @{"P1"= $param1 ;"P2"= $param2 ;"limit"= $limitRows }
} | ConvertTo-Json
$URL = $dbxWorkspaceURL + "api/2.0/jobs/run-now"
$responseJob = Invoke-RestMethod $URL -Method 'POST' -Headers $headers -Body $body
$runId = $responseJob.run_id
Write-Output "run ID : "$runId
$URL = $dbxWorkspaceURL + "api/2.0/jobs/runs/get-output?run_id="+$($runId)
Write-Output "Run status and Get output"
$runStatus = "PENDING"
Do
{
Write-Output "Please wait one minute more...the job is running"
Start-Sleep -Seconds 60
$responseRun = Invoke-RestMethod $URL -Method 'GET' -Headers $headers
$responseun | ConvertTo-Json
$runStatus = $responseRun.metadata.state.life_cycle_state
Write-Output $runStatus
}
Until($runStatus -eq "TERMINATED")
Write-Output "Check run result state"
$runResultState = $responseRun.metadata.state.result_state
Write-Output $runResultState
If($runResultState -ne "SUCCESS")
{
exit;
}
Write-Output "Export result to file"
$result = $responseRun.notebook_output.result
$isTruncated = $responseRun.notebook_output.truncated
if($isTruncated -eq "False")
{
$result | Out-File -FilePath $filePath -Force
Write-Output "Export done"
}
Dans ce code, nous nous appuyons sur la fonction Invoke-RestMethod suivie de l’URL de l’API Databricks. La réponse sera ensuite exploitée pour continuer le programme.
L’instruction api/2.0/jobs/runs/get-output?run_id= permet de retourner un texte passé en paramètre de la commande Databricks qui viendra conclure le notebook (aucune autre cellule ne sera ensuite exécutée) :
dbutils.notebook.exit(textObject)
Le contenu de la variable textObject se retrouve alors au niveau metadata.state.result_state du résultat de l’instruction. La sortie ne peut dépasser un volume de plus de 5Mo. Nous pouvons vérifier que le résultat n’est pas tronqué à l’aide de la valeur de l’élément notebook_output.truncated à false.
En mettant en œuvre ce code au sein d’une ressource comme Azure Function (les paramètres définis au début du code intégrant alors la route de la fonction), nous avons obtenu une “meta API” paramétrable, restituant un résultat sous forme d’export de données !