
Si vous travaillez à plusieurs sur Azure Databricks, vous vous êtes sûrement déjà confronté.e.s à des réflexions sur les droits à accorder à chacun.e, selon les profils : data analyst, data scientist, data engineer, ML engineer… Rappelons qu’une gestion fine des droits ne sera possible qu’en licence dite Premium.
Il est évident qu’un administrateur de l’espace de travail ne souhaitera pas gérer des autorisations nominatives et ainsi, devoir reprendre la gestion à droits à chaque arrivée ou départ sur un projet ! Nous souhaitons donc nous référer à des groupes et c’est justement une notion bien intégrée dans l’annuaire Azure Active Directory (AAD).
Databricks dispose également d’une gestion de groupes d’utilisateurs dans sa console d’administration.
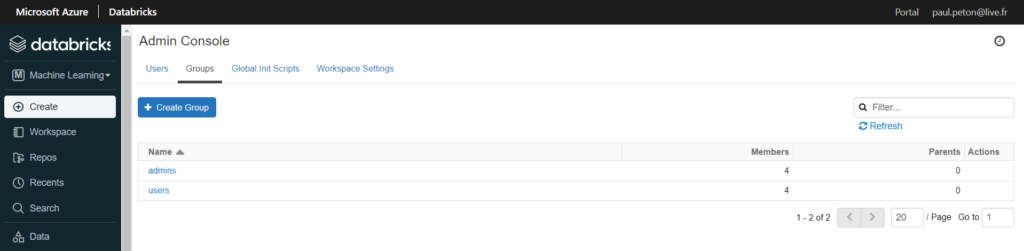
Malheureusement, il n’est pas possible d’utiliser un alias de groupe AAD dans Databricks et ces deux notions de groupes ne sont pas synchronisées entre elles !
Nous pourrions aussi imaginer un déploiement Terraform qui viendrait décortiquer un groupe AD et ajouter chaque utilisateur au moyen d’une boucle (voir ce post Medium) mais cette démarche semble vraiment trop lourde à mettre en œuvre et à maintenir…
Un outil vient à notre secours : Azure Databricks SCIM Provisioning Connector et c’est mon collègue Hamza BACHAR qui me l’a soufflé.
Nous commençons par enregistrer cet outil en tant qu’enterprise application dans Azure AD.
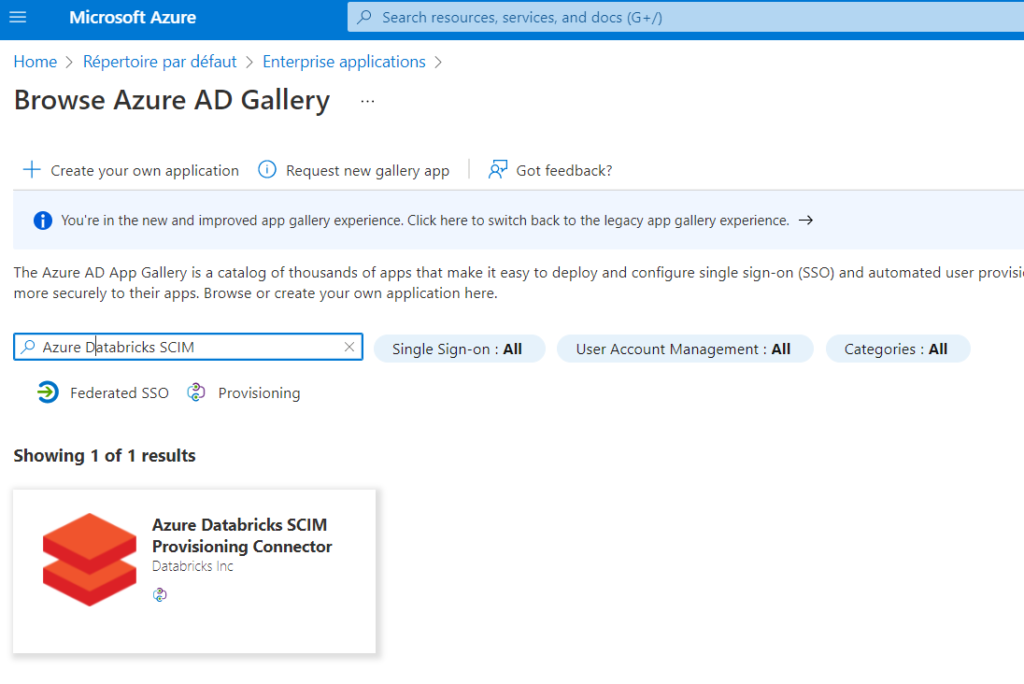
Il s’agit d’un produit développé par la société Databricks Inc, ce qui est plutôt rassurant.
Il est recommandé de renommer l’application en intégrant le nom de la ressource Databricks car il faudra autant d’enregistrements d’applications que de workspaces.
L’application est maintenant enregistrée dans notre abonnement Azure et dispose de deux identifiants : application ID et object ID.
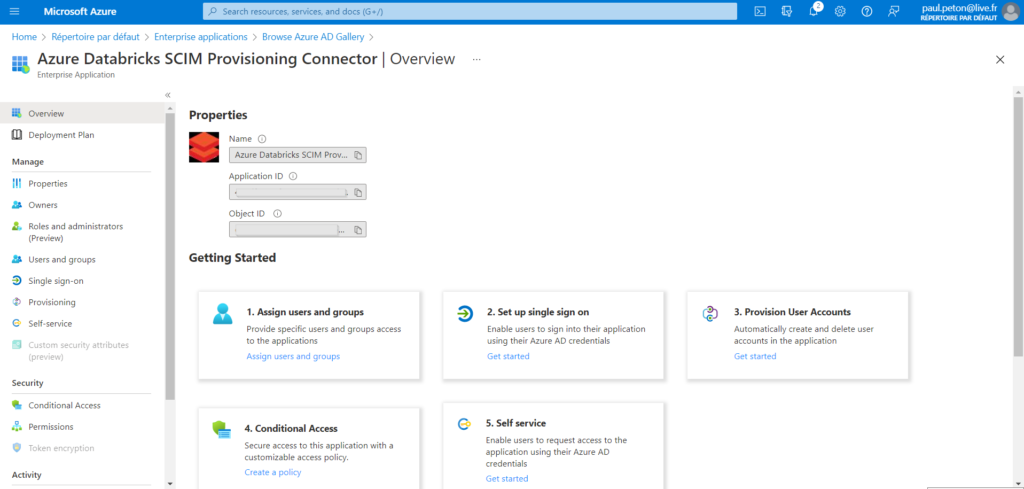
Nous cliquons maintenant sur le menu Provisioning qui va nous permettre d’associer l’application avec un workspace Databricks. Le mode de provisioning doit être basculé sur Automatic.
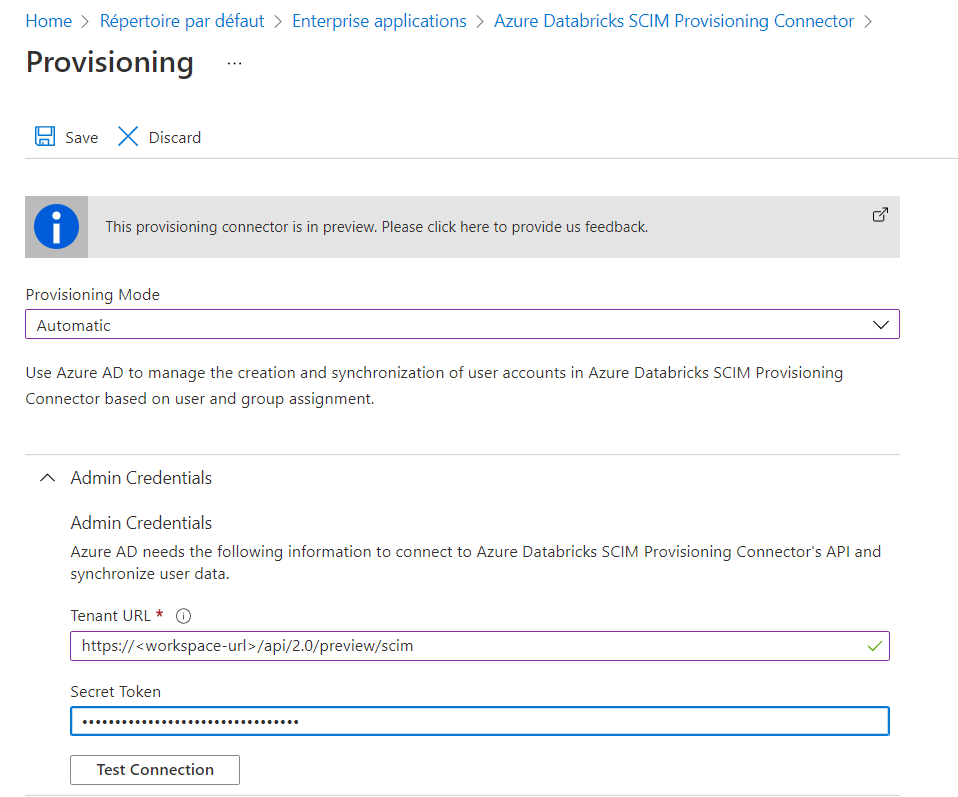
Nous devons fournir ici deux informations :
- l’URL du workspace à laquelle sera ajoutée le point de terminaison de l’API SCIM
- un Personal Access Token qui aura été généré depuis les user settings de Databricks
Nous testons la connexion puis clic sur “Save” pour conserver le paramétrage.

Nous laissons par défaut les autres options disponibles.
Le provisioning peut maintenant être démarré.
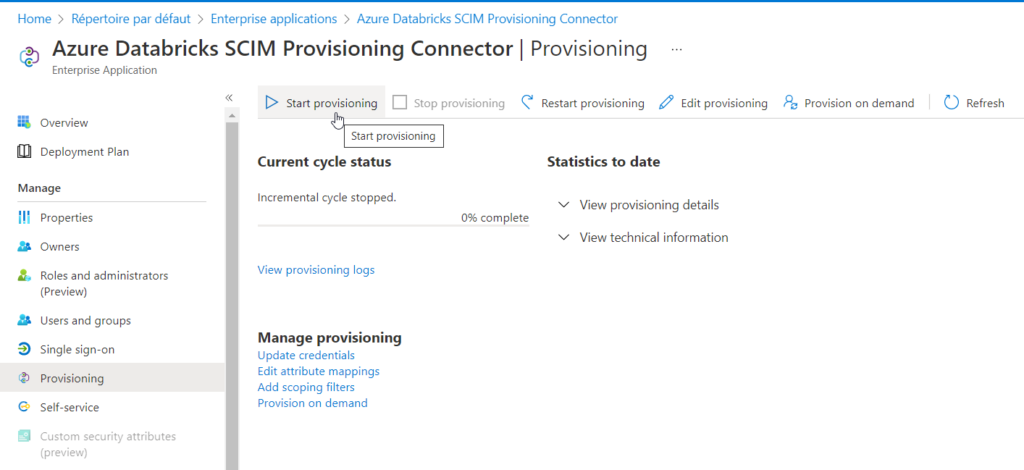
Il ne reste plus qu’à positionner des users ou groups directement dans cette application pour qu’ils soient automatiquement synchronisés avec la console d’administration Databricks ! Il est toutefois nécessaire d’attendre quelques minutes (cela peut aller jusqu’à 40 minutes). On privilégiera les “groupes de sécurité” plutôt que de type “M365” et les “nested groups” ne sont pas aujourd’hui supportés.
Il est aussi possible de “provisionner à la demande” un utilisateur.
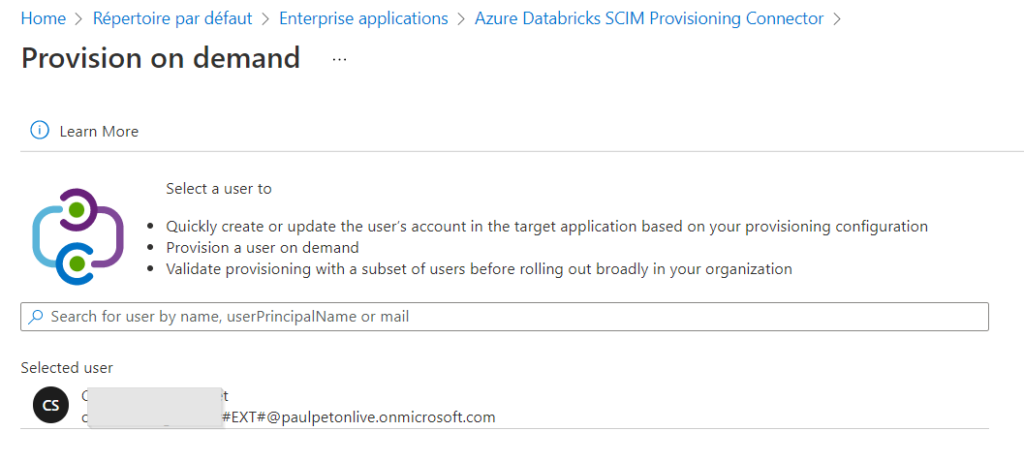
Un écran vient ensuite confirmer que l’action a bien été réalisée et l’utilisateur est directement ajouté au workspace.
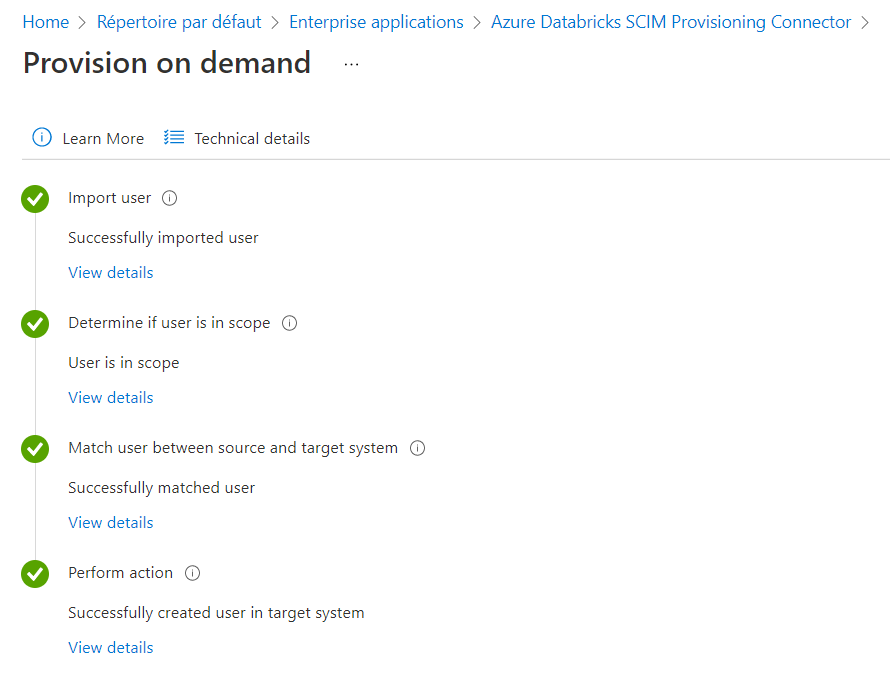
A noter que le nouvel utilisateur est restreint sur ses droits, par défaut.
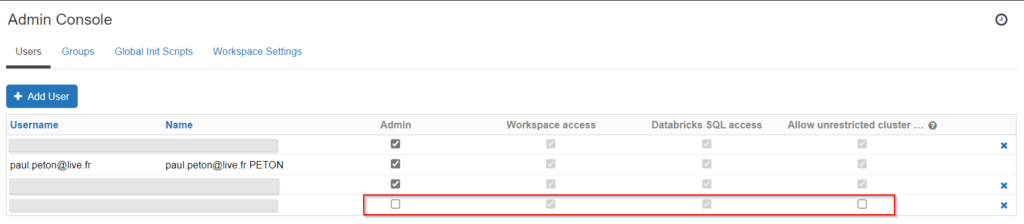
Il n’est pas administrateur du workspace et se trouve restreint sur la création de nouveaux clusters.
EDIT
Il est nécessaire qu’une personne ayant le droit d’enregistrement d’applications réalise la première manipulation. Mais ensuite, d’autres personnes pourront avoir besoin d’utiliser cette interface.
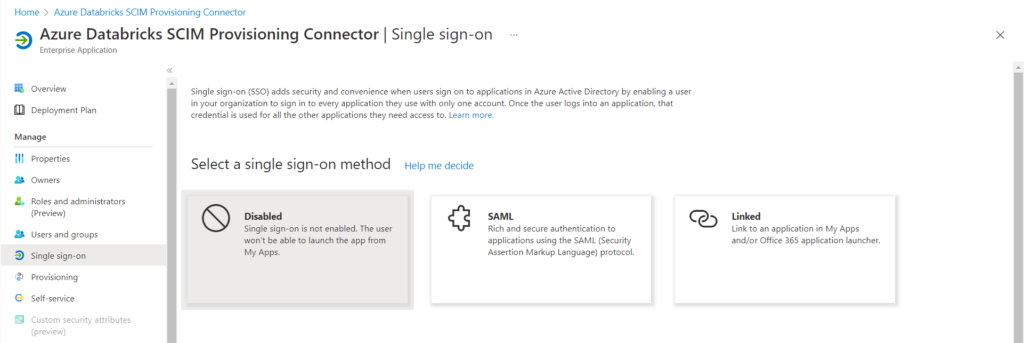
Nous allons donc autoriser d’autres utilisateurs au “self-service” de cette application. Il faut tout d’abord activer le “single sign-on”, en mode “linked”.
Fournir pour cela l’URL de connexion.
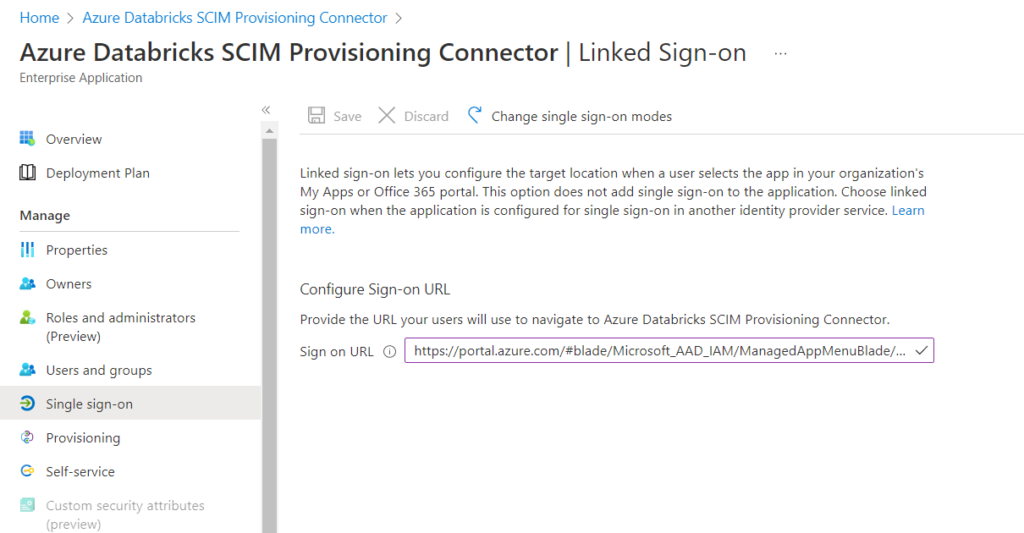
On paramètre enfin le menu Self-service.
Si l’on souhaite plutôt ajouter des users ou des groups de manière programmatique, on pourra se pencher sur ce code PowerShell.