
Azure Databricks se positionne comme une plateforme unifiée pour le traitement de la donnée et en effet, le service de clusters managés permet d’aborder des problématiques comme le traitement batch, mais aussi le streaming, voire l’exposition de données à un outil de visualisation comme Power BI.
La capacité de mise à l’échelle (scalabilité ici horizontale) d’Azure Databricks est également un argument de poids pour établir cette solution dans un contexte de forte volumétrie. Par forte volumétrie, nous entendons ici le fait qu’un tableau de données, ou les opérations qui permettraient d’y parvenir, dépasse la mémoire disponible sur une seule machine. La solution sera donc de distribuer la donnée ou les traitements. Mais attention, il va falloir bien choisir ses armes avant de se lancer dans un premier notebook !
Le choix des armes
A la création d’un notebook sur Azure Databricks, quatre langages sont disponibles.
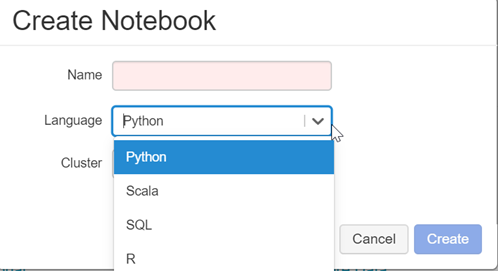
Sauf à ne vouloir faire que du SQL, je vous déconseille de prendre ce type de notebook puisqu’il sera très simple d’exécuter une commande SQL dans une cellule à l’aide la commande magique %sql.
Si vous venez de la Data Science « traditionnelle » (rien de péjoratif, c’est d’ailleurs mon parcours, comprendre ici l’approche statistique antérieure à l’ère de la Big Data), vous serez attirés par le langage R. Mais vous savez sûrement que R est un langage, de naissance, single-threaded et peu apte à paralléliser les traitements. Microsoft a pourtant racheté la solution RevoScaleR de Revolution Analytics et l’a intégrée en particulier à SQL Server. Dans un contexte Spark, on peut s’orienter vers l’API SparkR mais celle-ci ne semble pas soulever un très gros engouement (contredisez-moi dans les commentaires) dans la communauté.
Python remporte aujourd’hui une plus forte adhésion, en particulier auprès des profils venant du monde du développement. Attention, coder un traitement de données en Python ne vous apportera aucune garantie d’amélioration par rapport au même code R ! Ici, plusieurs choix se présentent à nouveau.
Une première piste sera d’exploiter la librairie Dask qui permet de distribuer les traitements.
Une deuxième possibilité est de remplacer les instructions de la librairie pandas par la librairie développée par Databricks : koalas. Je détaillerai sûrement l’intérêt de cette librairie dans un prochain article.
Le troisième choix possible sera à mon sens le meilleur : l’API pyspark. Cette API va vous permettre :
- de créer des objets Spark DataFrames
- d’enregistrer ces DataFrames sous formes de tables (locales ou globales dans Databricks)
- d’exécuter des requêtes SQL sur ces tables
- de lire des fichiers au format parquet
Les API Spark permettent d’écrire dans un langage de plus haut niveau et plus accessible pour les développeurs (data scientists ou data engineers) qui sera ensuite traduit pour son exécution dans le langage natif du cluster.
Les différents codes possibles
Je vous propose ci-dessous un comparatif des approches pandas et pyspark pour un même traitement de données. Le scénario est de charger les données de la base open data des accidents corporels, soit deux dossiers de fichiers csv : les usagers et les caractéristiques des accidents. Une fois les fichiers chargés, une jointure sera réalisée entre les deux sources sur la base d’une clé commune.
L’objectif est ici d’établir un parallèle entre les syntaxes et non d’évaluer les performances. La librairie pandas n’est d’ailleurs pas la plus optimale pour charger des fichiers csv et on mettra à profit les méthodes plus classiques de lecture de fichiers.
A l’import, création d’un dataframe
# pandas
df = pd.read_csv(filename)
# pyspark
df = spark.read.format("csv") \
.option("header", "true").option("inferSchema", "true").load("filename")
Avec pandas, il pourra être nécessaire de caster certaines colonnes dates suite à l’import.
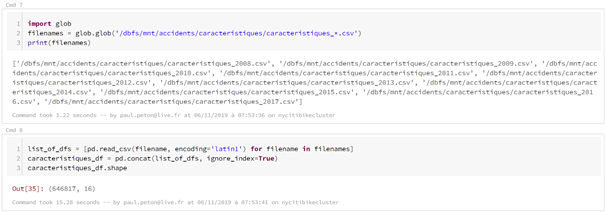
La lecture en Spark autorise l’emploi de caractères génériques ( ? ou *) pour lire et concaténer automatiquement plusieurs fichiers. Les archives .zip contenant par exemple un fichier .csv peuvent être chargées sans décompression préalable, ce qui ne sera pas le cas avec pandas.
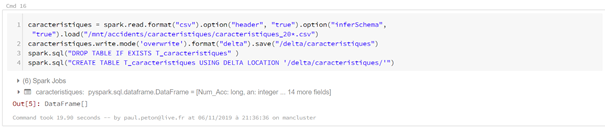
Fusion de deux dataframes
# pandas df = pd.merge(df1, df2, on='key', how='inner') # pyspark df = df1.join( df2, 'key', how='inner')
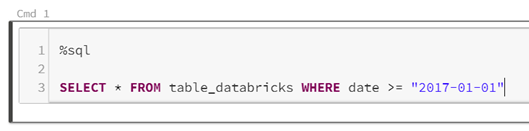
L’avantage de Databricks sera de pouvoir persister certains dataframes sous forme de vues (« tables locales ») ou de tables (« tables globales). En particulier, le format delta pourra être mis à profit. Dès lors, il devient très simple de travailler en Spark SQL pur, toujours en débutant la cellule par la commande magique %sql.
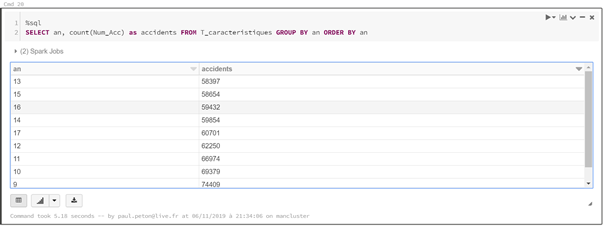

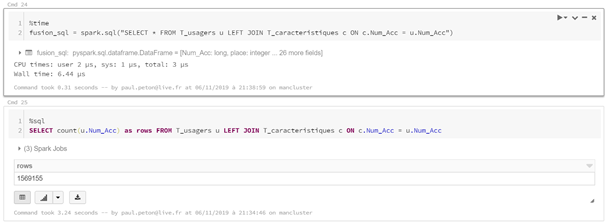
Vérification du dataframe
# pandas df.shape df.info # pyspark df.count() len(df.columns) df.printSchema
Pandas se montre ici à son avantage avec des résultats plus simples à obtenir pour connaître les dimensions du dataframe (shape) ou des informations sur le schéma et les valeurs manquantes.
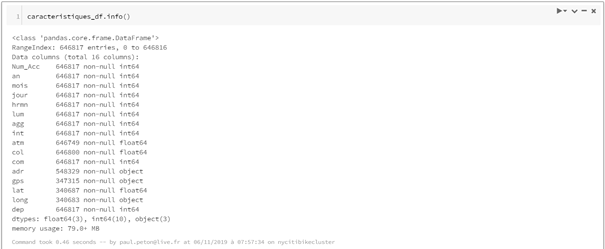
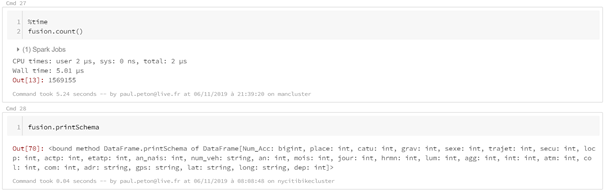
En conclusion
Lorsqu’on pose à certains érudits musicaux la sempiternelle question « Stones ou Beatles », il n’est rare d’entendre la réponse suivante : « ni l’un, ni l’autre, mais les Kinks ! »
A la question non moins sempiternelle « R ou Python », je répondrai donc… Scala ! C’est en effet le langage natif de Spark et donc le plus proche du moteur d’exécution.
Malgré tout, le choix se fera aussi en fonction de critères plus pragmatiques comme la puissance nécessaire au traitement, le coût de travailler sur l’exhaustivité des données (pourquoi par un échantillon représentatif ?) ou la maîtrise des différents langages par les personnes en charge des développements.
Magnifique ! Vraiment très instructif… 🙂