
Avec l’arrivée du CLI et du SDK V2, Azure Machine Learning s’est orientée vers une utilisation centrée sur le MLOps, cette démarche visant à automatiser les étapes du cycle de vie d’un modèle de Machine Learning.
Plutôt que d’alourdir le code Python, ce sont maintenant des opérations décrites dans des fichiers YAML qui se chargent de l’exécution des scripts de préparation de données ou d’entrainement.
L’utilisation du CLI est en particulier efficace pour des tâches comme la création d’un compute cluster ou le déploiement d’un point de terminaison dédié à l’inférence (les prévisions, en temps réel ou en mode batch).
GitHub s’impose quant à lui comme la ressource permettant le versioning des scripts (repositories) mais aussi leur déploiement continu, grâce aux GitHub Actions.
Authentifier GitHub vis à vis du workspace Azure ML
C’est une identité de type Service Principal (SPN) qui va réaliser l’authentification de l’action GitHub vis à vis du workspace Azure ML.
Pour cela, notez le client ID lors de la création du SPN ainsi que le tenant ID et la subscription ID correspondant au déploiement du service Azure ML.
Créez ensuite un secret associé à SPN et notez sa valeur (attention, ce n’est pas le secret ID).
Structurez ces informations de la manière suivante :
{
"clientId": "xxx",
"clientSecret": "xxx",
"subscriptionId": "xxx",
"tenantId": "xxx"
}Dans l’interface GitHub, nous allons définir un ensemble de credentials, dans le menu Settings > Secrets and variables.
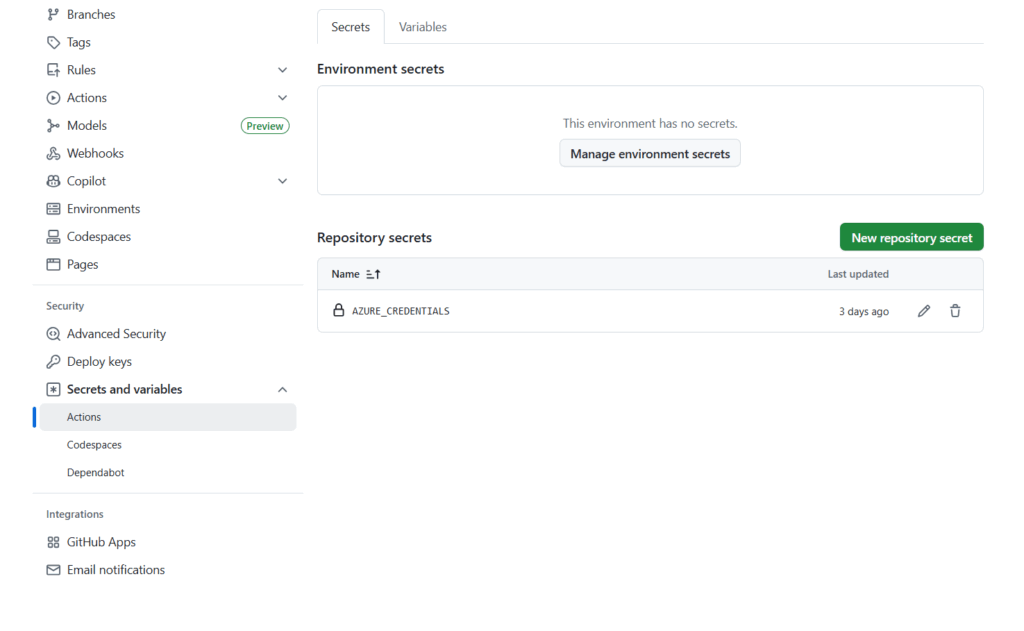
Le secret doit être nommé AZURE_CREDENTIALS.
En parallèle, le SPN doit disposer d’un droit de type Contributor sur le workspace ML.
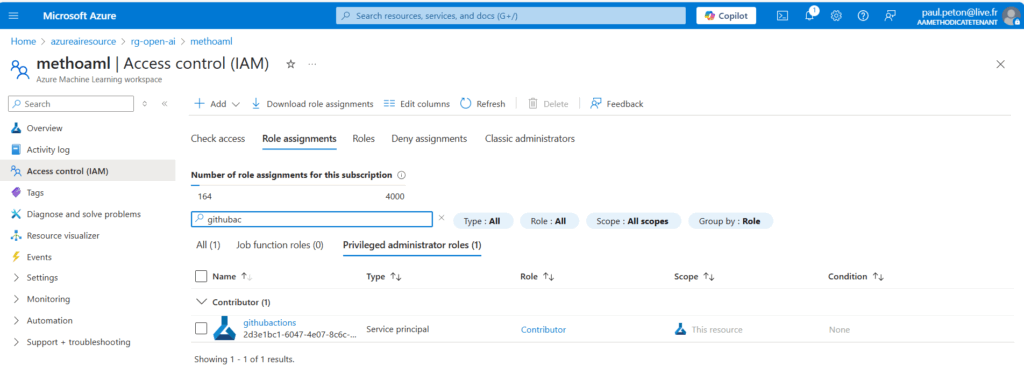
Lancer un premier job
Clonez le répertoire suivant : methodidacte/azmlcli: CLI az ML et déploiement automatisé via GitHub Actions (train & deploy model)
Celui-ci contient un fichier YAML de définition du job. Il s’agit d’un simple affichage de texte “Hello world”.
$schema: https://azuremlschemas.azureedge.net/latest/commandJob.schema.json
command: echo "hello world"
environment:
image: library/python:latestDans une arborescence .github/workflows, un second fichier YAML définit l’action à réaliser.
name: Deploy Azure ML Hello World
on:
push:
branches: [ main ]
permissions:
id-token: write
contents: read
jobs:
deploy:
runs-on: ubuntu-latest
steps:
- name: Checkout repo
uses: actions/checkout@v3
- name: Login to Azure
uses: azure/login@v1
with:
creds: '${{secrets.AZURE_CREDENTIALS}}'
- name: Set up Azure CLI ML extension
run: |
az extension add -n ml -y
az configure --defaults workspace=<WORKSPACE_NAME> group=<RESOURCE_GROUP_NAME>
- name: Submit job to Azure ML
run: |
az ml job create -f job.ymlPensez à bien modifier les deux noms nécessaires pour définir le workspace Azure ML et le groupe de ressources qui le contient.
Par défaut, l’action se lance automatiquement lors d’un commit ou d’un merge sur la branche main.
Contrôler la bonne exécution du job
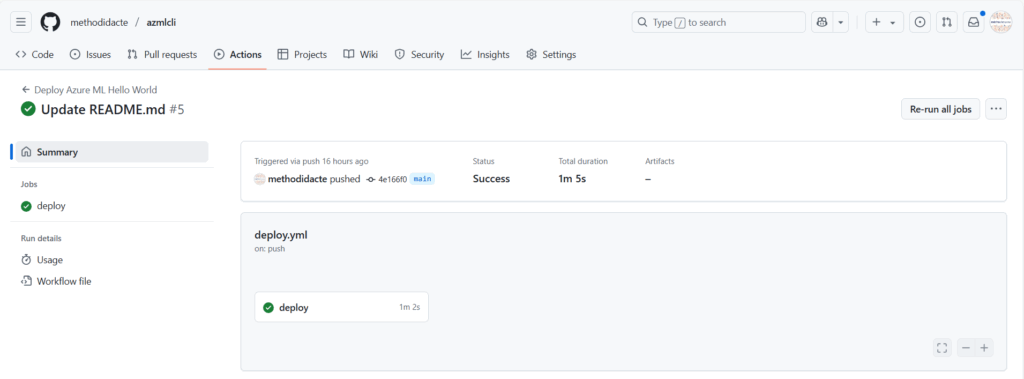
L’action est visible dans le menu Actions.
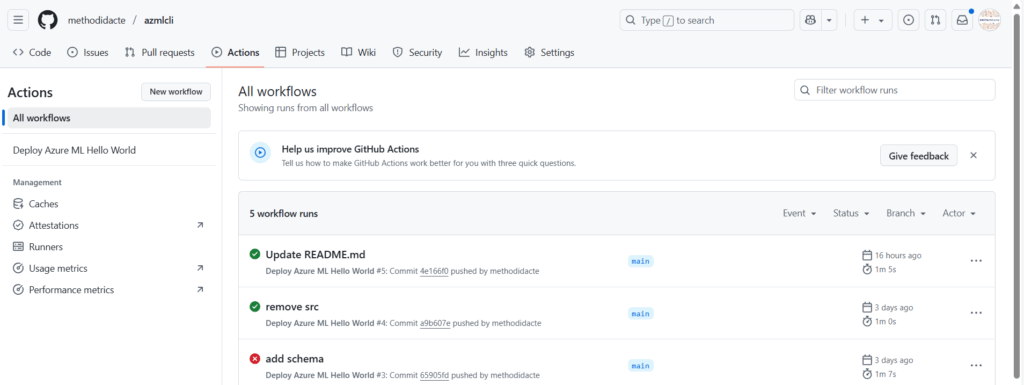
Le statut de l’action doit indiquer “Success”.
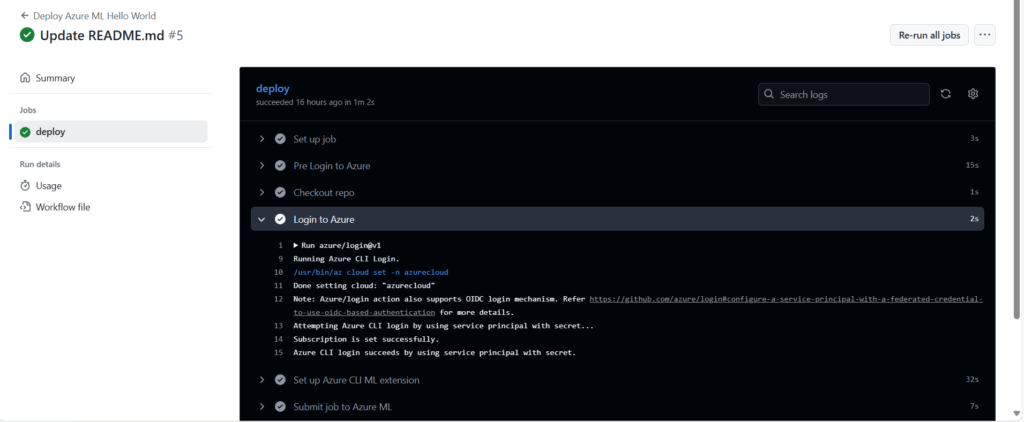
Vérifiez en particulier la bonne authentification de GitHub vis à vis de la ressource Azure.
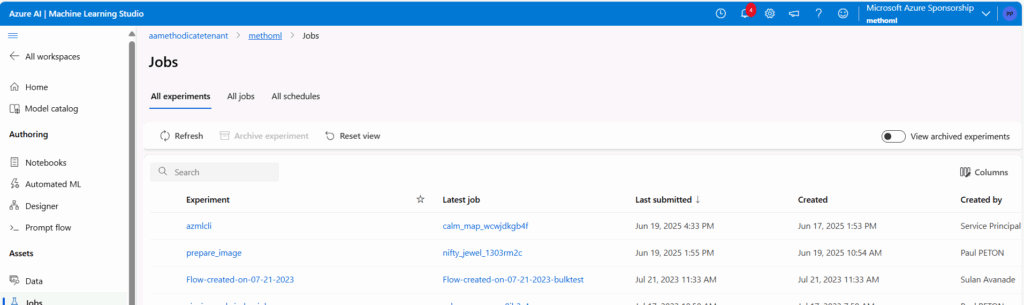
Dans le studio Azure ML, le job est également visible et rattaché à une experiment.
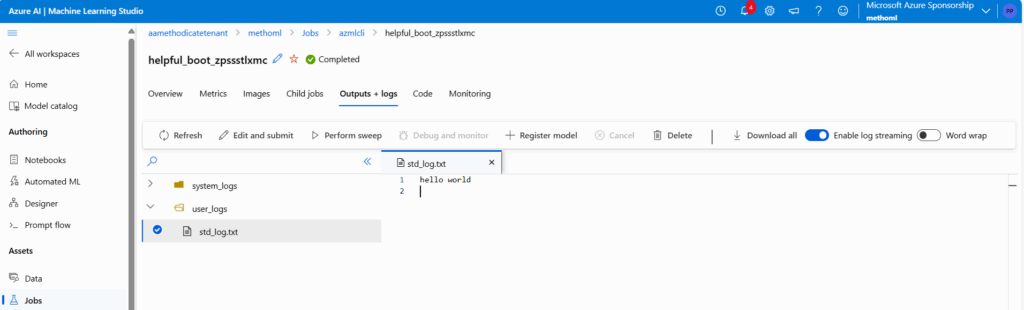
Nous retrouvons le “hello world” dans les logs du job.
Cette stratégie de déploiement continu s’appliquera sur les étapes de préparation de données, d’entrainement ou encore de déploiement du point de terminaison.