
En décembre 2022, tout le monde ou presque s’est mis à interroger ChatGPT et à tester sa “culture générale” allant jusqu’à… sa date d’entrainement, située à début 2022. Impossible donc de savoir qui avait remporté la Coupe de Monde de la FIFA à l’été 2022 !
Très rapidement, les entreprises se sont projetées sur un cas d’usage professionnel : l’amélioration de la recherche au sein de leur documentation interne. En effet, il existe bien souvent des montagnes de fichiers Word ou PDF, contenant des trésors d’informations, restées inexploitées car les mécanismes de recherche ne pouvaient les atteindre. Et lorsque la recherche est efficace, il est bien utile de disposer d’un bot capable de reformuler, synthétiser, vulgariser ou encore traduire les résultats les plus pertinents.
Le 19 juin 2023, une nouvelle fonctionnalité dédiée à ce scénario est apparue dans Azure OpenAI Service. Voici comment l’utiliser.
Nous allons ici déposer deux fichiers PDF, l’un en anglais, l’autre en français, contenant des procédures informatiques.
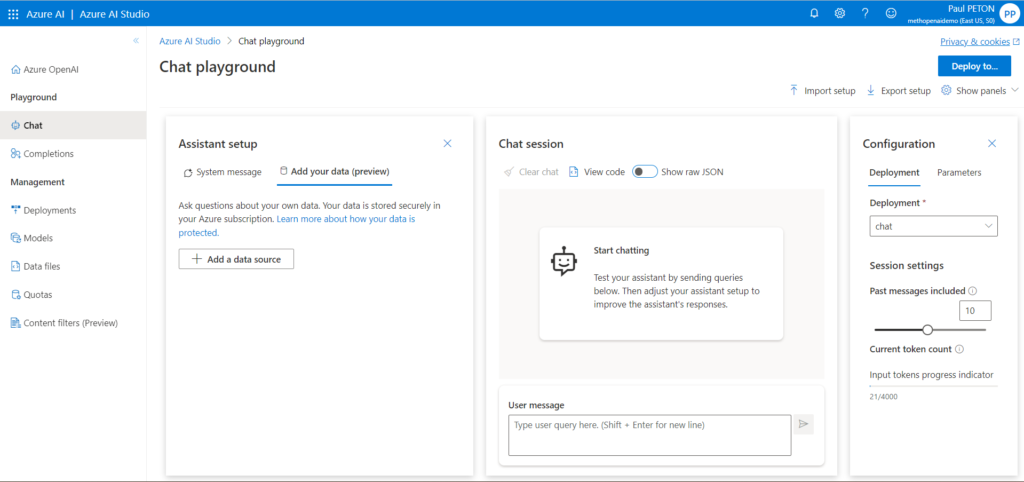
Depuis le playground Azure OpenAI, dans le menu Chat (conversation), nous trouvons un nouvel onglet “Add your data (preview)“.
Les aspects de sécurité de vos données et la gestion de la modération de la discussion sont présentés dans la documentation officielle de Microsoft.
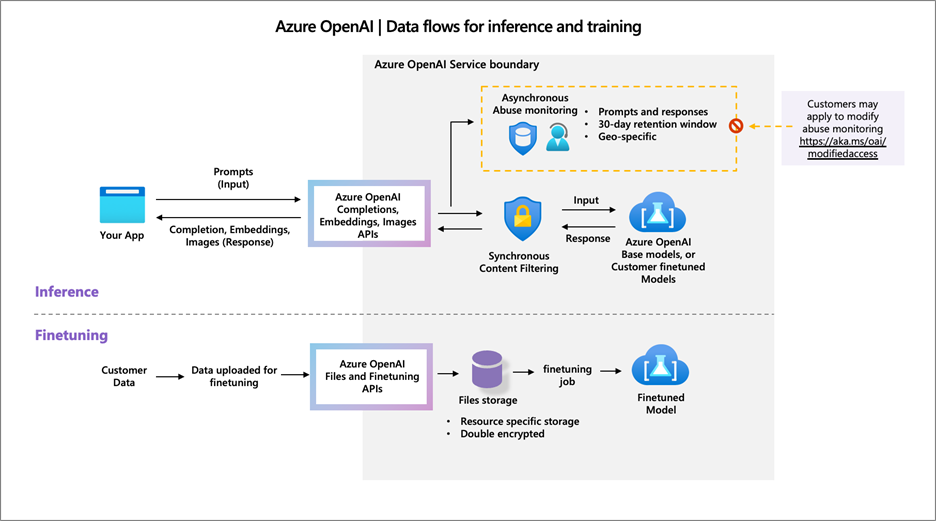
Il est important de comprendre que le chargement de ses propres documents n’entraine pas de fine-tuning du modèle. Une revue des couples prompts – completions peut être faite par Microsoft mais il est possible de demander la désactivation de cette revue et donc du stockage temporaire des échanges avec le bot. Voici le formulaire de demande : https://aka.ms/oai/modifiedaccess
Cliquons sur le bouton “Add a datasource”.
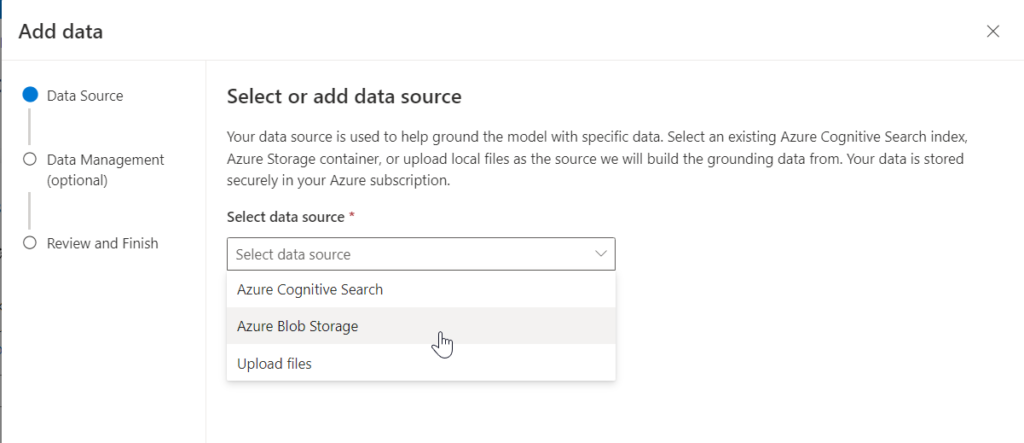
Nous disposons de trois sources possibles mais toutes aboutiront à un index Azure Search. Il est en effet possible de sélectionner :
- un index Azure Cognitive Search déjà réalisé
- le container d’un Azure Blob Storage
- l’upload de fichiers locaux dans… un Azure Blob Storage
Cette dernière fonctionnalité sera utile si les utilisateurs n’ont accès qu’au playground du service Azure OpenAI.
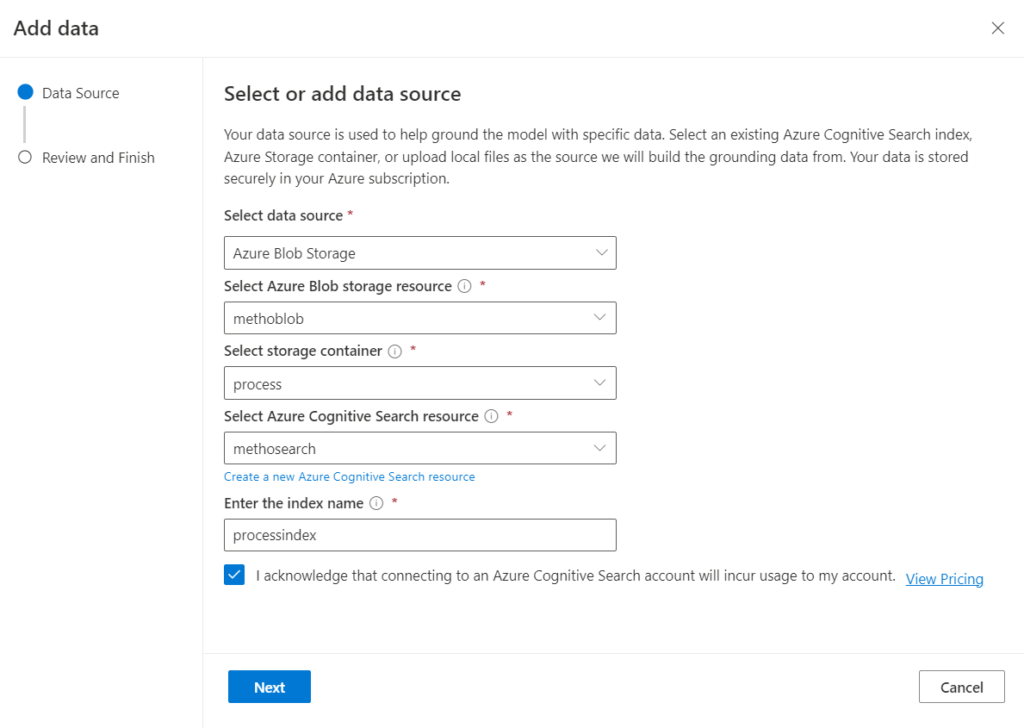
Les fichiers du container sont alors indexés en tâche de fond.
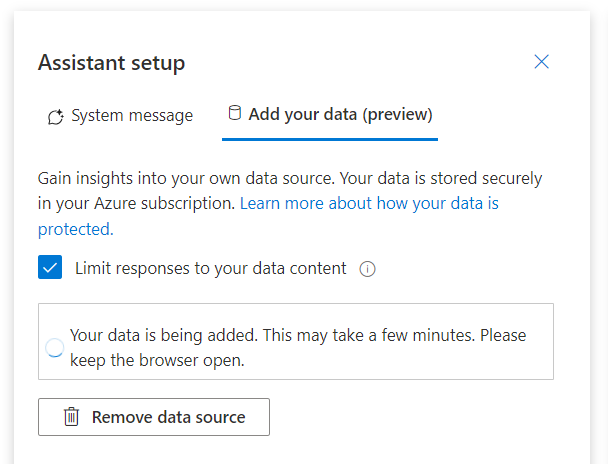
Il faut bien comprendre qu’il s’agit ici, pour l’instant, d’un index basé sur les mots clés (keywords) ou bien le semantic search si cette fonctionnalité a été ajoutée dans Azure Cognitive Search. Nous ne parlons donc pas pour l’instant d’embeddings ni de vector search.
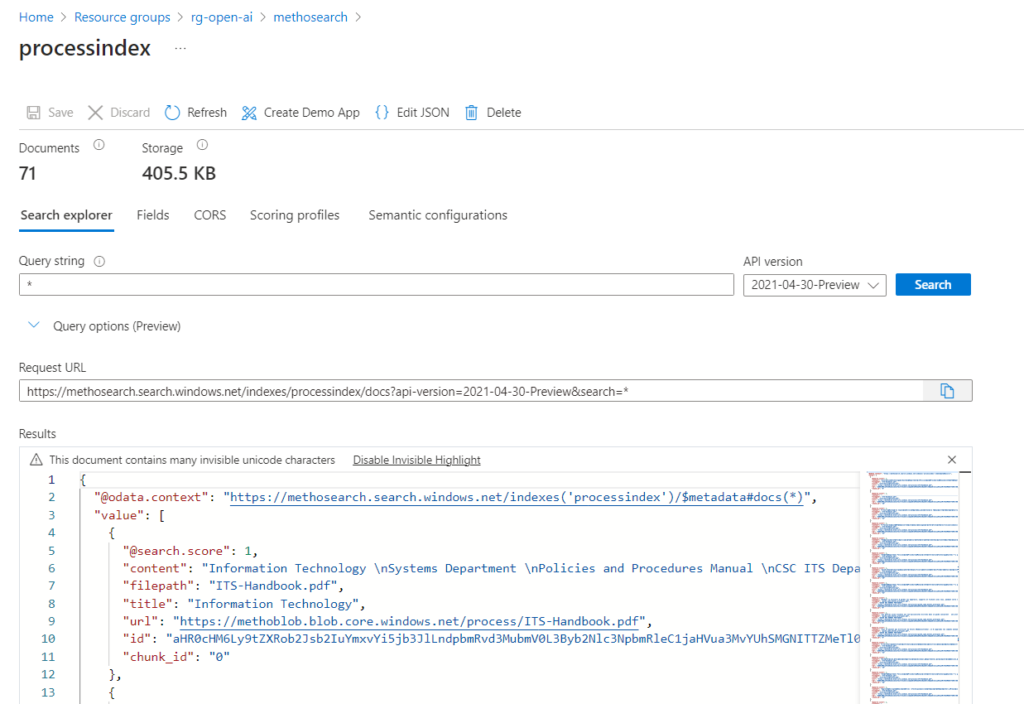
La case à cocher “Limit responses to your content” permet de s’assurer que le modèle n’ira pas chercher d’informations complémentaires dont il disposerait déjà, lors de son entrainement initial.
En analysant l’exemple de code proposé dans l’interface, nous ne remarquons rien de particulier : pas de nouvel “engine” (ici GPT 3.5 turbo et la fonctionnalité ne semble pas disponible avec GPT-4), pas de nouvelle méthode (ChatCompletion.create en Python).
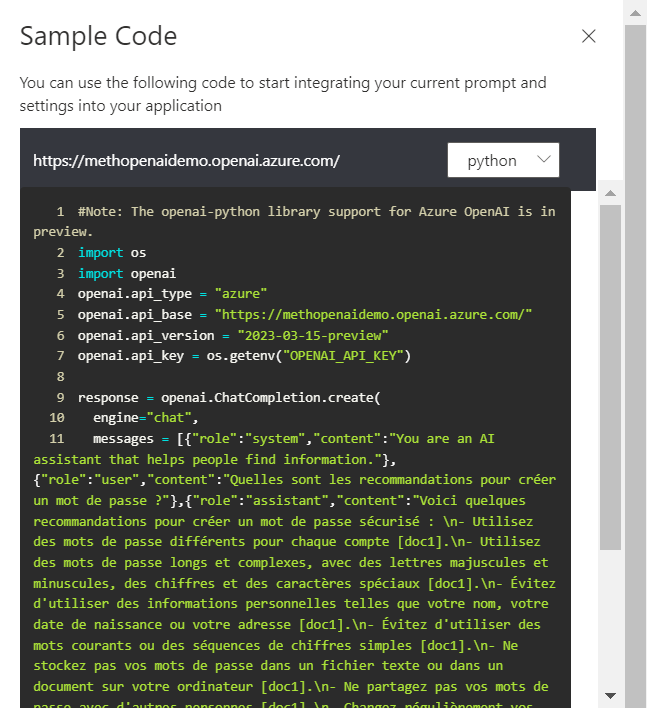
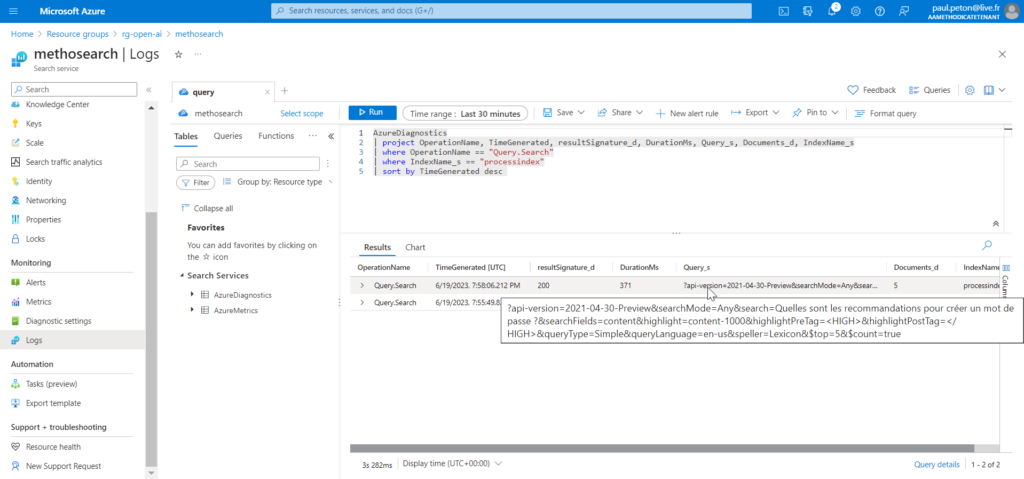
Il y a donc un mécanisme sous-jacent qui transmet à l’API les bonnes informations issues du search pour réaliser la réponse du bot. En interrogeant les logs d’Azure Search, nous pouvons retrouver la requête soumise.
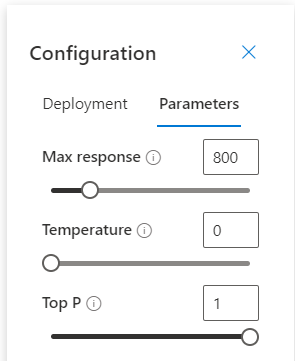
Une rapide vérification des paramètres permet de voir que la température est à 0, afin d’assurer l’aspect déterministe du modèle et donc d’espérer obtenir les mêmes réponses lorsque l’on répète les questions.
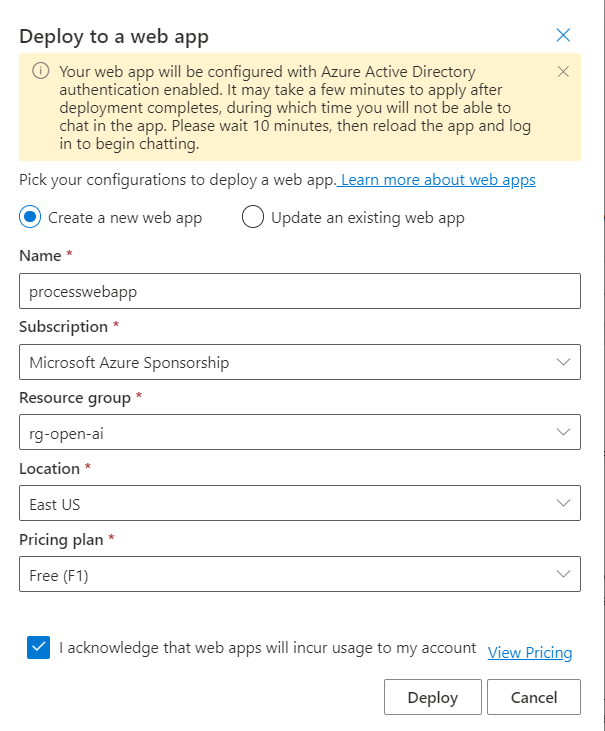
Nous allons utiliser le bouton “Deploy to…” pour créer une application web qui portera la fonctionnalité de chat sur les données. Une authentification par Azure Active Directory sera nécessaire.
L’application est maintenant déployée (il sera possible de la mettre en pause, depuis le portail Azure).
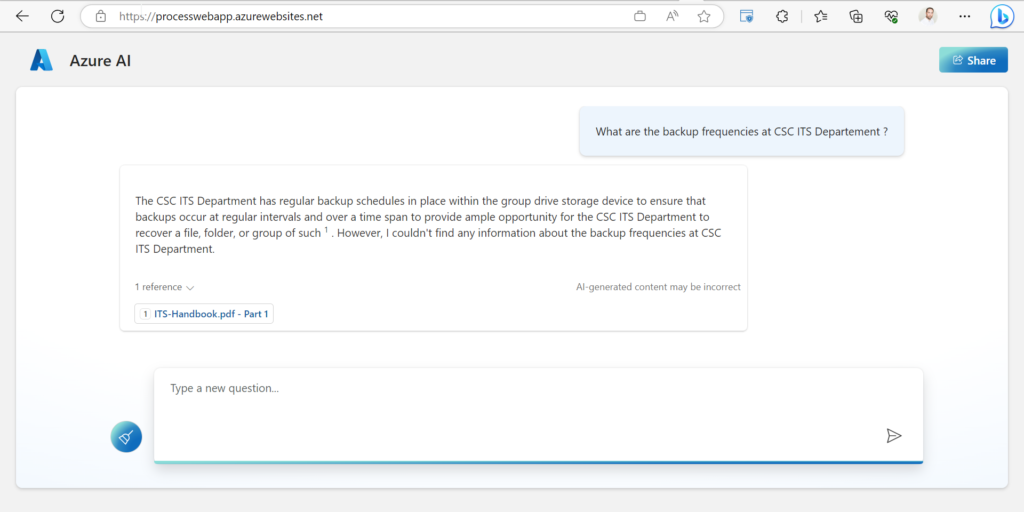
EDIT : le code source de cette application est disponible sur ce repo GitHub.
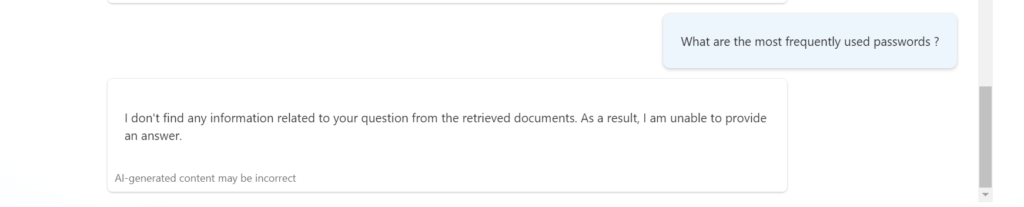
Si la question ne trouve pas réponse dans les documents indexés, le bot ne fournit pas de réponse.
En conclusion, voici les éléments qui limitent encore cet outil et pourraient vous convaincre de réaliser vous-même votre application avec des frameworks comme LangChain ou Semantic Kernel (voir cet article de Kévin BEAUGRAND) :
- le search sur des vecteurs d’embedding n’est pas encore disponible (mais arrivera prochainement)
- le search n’intègre pas la langue dans le paramètre de la requête émise par l’application (la recherche multilingue s’avère délicate)
- il est nécessaire de déplacer tous les documents dans Azure Blob Storage
- en cas d’évolution du contenu des documents, il faut regénérer complètement les index
- l’application se conforme au choix du bouton “Limit responses to your content” mais il n’est pas possible de le changer dynamiquement, une fois l’application déployée
- les documents cités comme sources ne peuvent pas s’afficher dans l’application
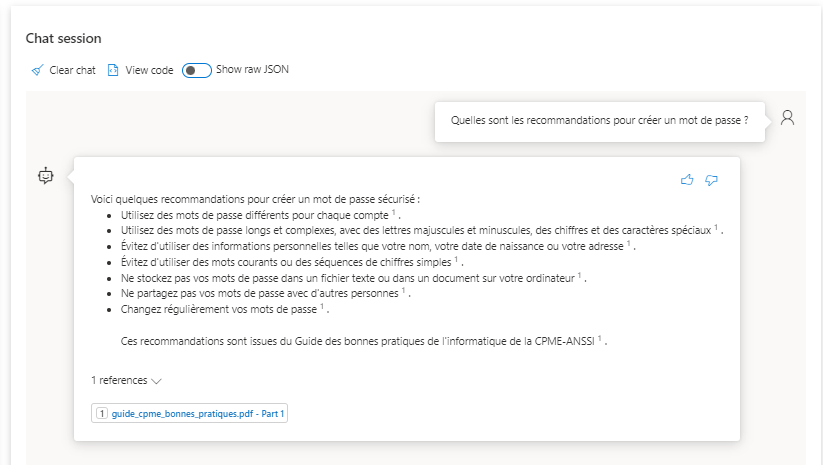
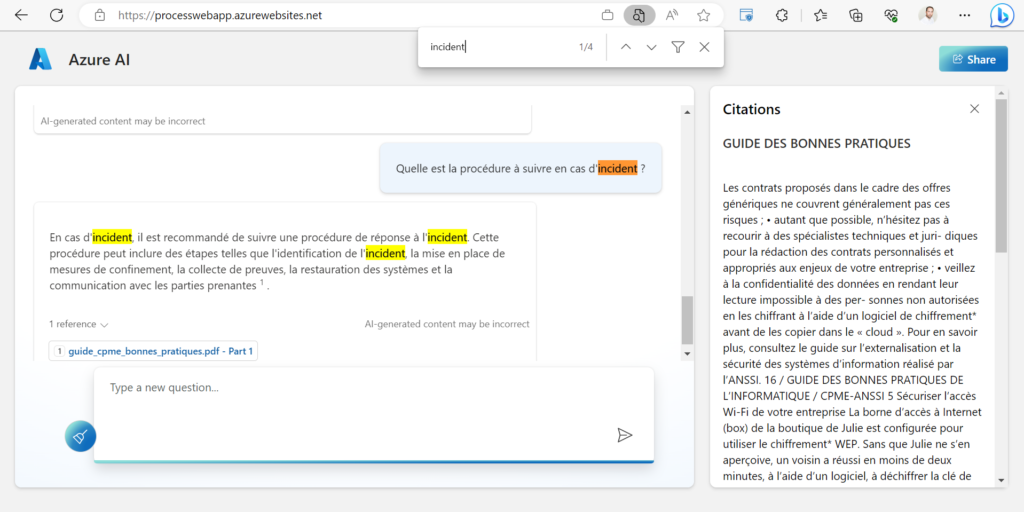
- les citations ne semblent pas toujours pertinentes (voir illustration ci-dessous)
- EDIT sur discussion avec Nicolas ROBERT : les documents contenant des images devraient passer par un processus d’OCR, par exemple avec Azure Form Recognizer
Notons tout de même qu’il s’agit là d’un accélérateur particulièrement efficace pour démontrer les performances des modèles GPT sur des corpus de documents.