
Microsoft Fabric est la nouvelle plateforme data & IA de Microsoft, permettant de travailler de bout en bout (de la collecte à la visualisation) des données, selon différentes expériences, correspondant à différents personae du monde de la data : Data Engineer, Data Analyst et également Data Scientist.
Les Scientifiques de données ont la possiblité de lancer un environnement de travail basé sur des notebooks, qui s’exécuteront sur un cluster Spark. Les données pourront bien sûr être stockées dans One Lake, le système central de stockage sur lequel s’appuie Fabric.
Les personnes habituées des environnements comme Azure Machine Learning ou Azure Databricks connaissent bien le produit Open-Source MLFlow, outil devenu un standard pour tracer les hyperparamètres d’entrainement ainsi que les métriques d’évaluation et pour stocker tous les artefacts liés à un modèle de Machine Learning : fichier des requirements, binaire du modèle sauvegardé, définition des input et output…

Microsoft a donc également intégré MLFlow au sein de la plateforme Fabric. Et pour simplifier son utilisation, il n’est même pas nécessaire d’appeler explicitement la session MLFlow pour déclencher le suivi des logs ! Il s’agit du mécanisme d’autologging documenté ici.
Pour autant, il peut être intéressant de définir explicitement les entrainements et les éléments (paramètres et métriques) que l’on veut voir enregistrés dans MLFlow.
Dans cet article, nous allons détailler ces deux modes de travail avec MLFlow intégré dans Microsoft Fabric.
Création implicite d’une expérience
Pour illustrer les différentes fonctionnalités, nous allons utiliser du code généré par ChatGPT, à l’aide du prompt suivant :
Ecris-moi un code Python qui illustre une classification Sklearn en utilisant un dataset de ce package
Nous pouvons maintenant exécuter le notebook contenant ce code.
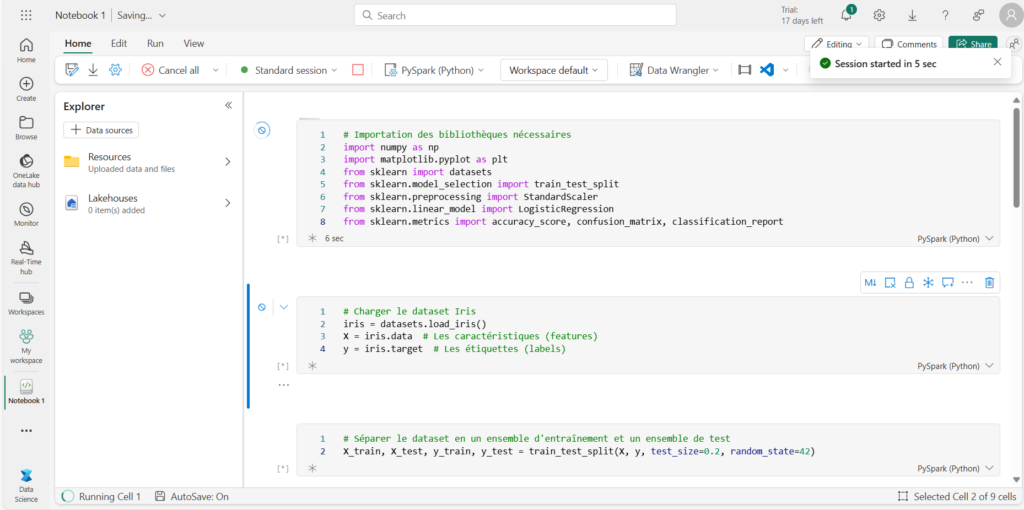
La méthode .fit() de la librairie Scikit-learn déclenche l’enregistrement d’un run (exécution) au sein d’une experiment (expérience) dont le nom est, par défaut, celui du notebook (ici “Notebook-1”).
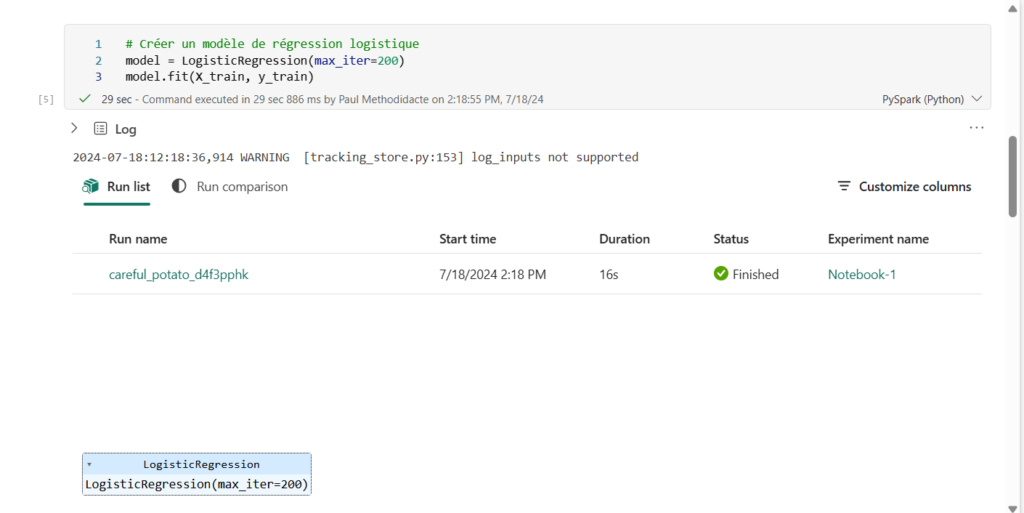
Ces deux éléments sont des liens cliquables qui vont nous permettre de naviguer dans d’autres éléments maintenant stockés dans l’espace de travail utilisé pour ce notebook.
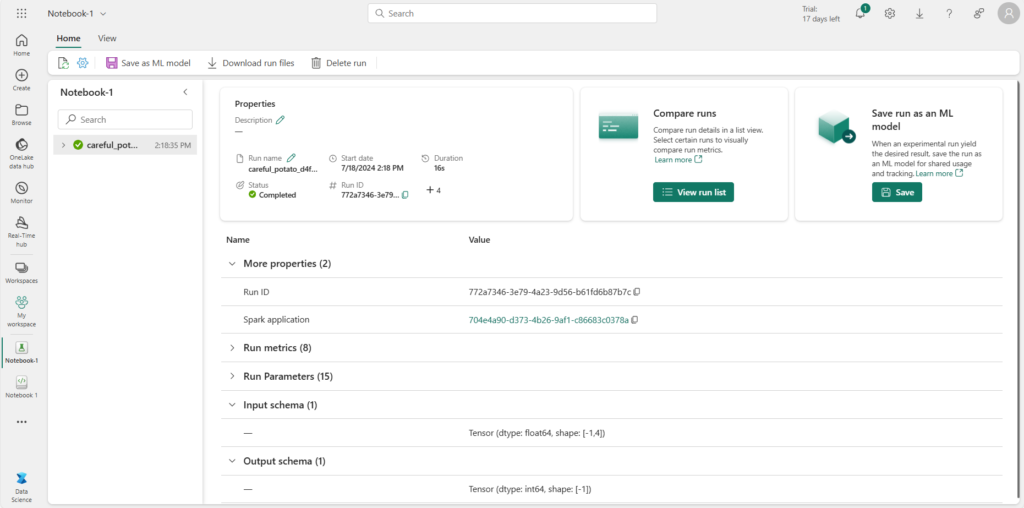
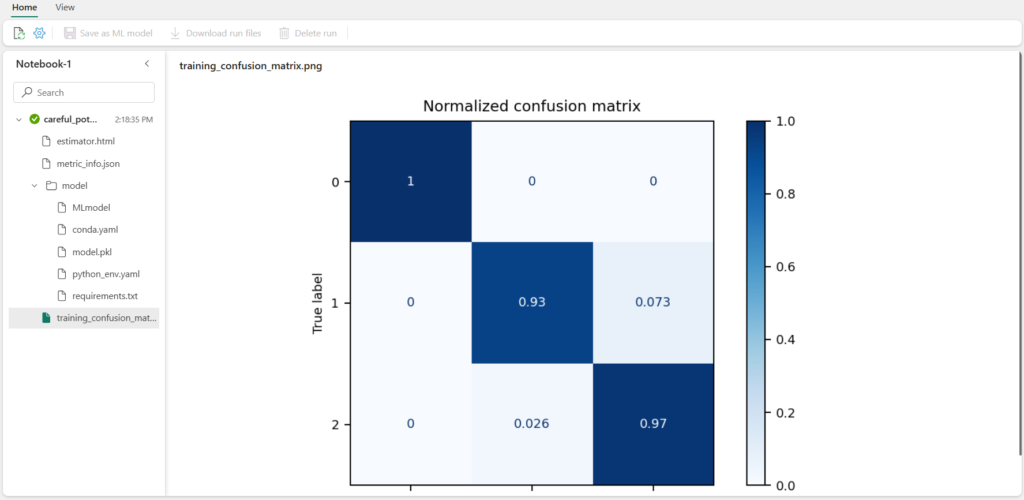
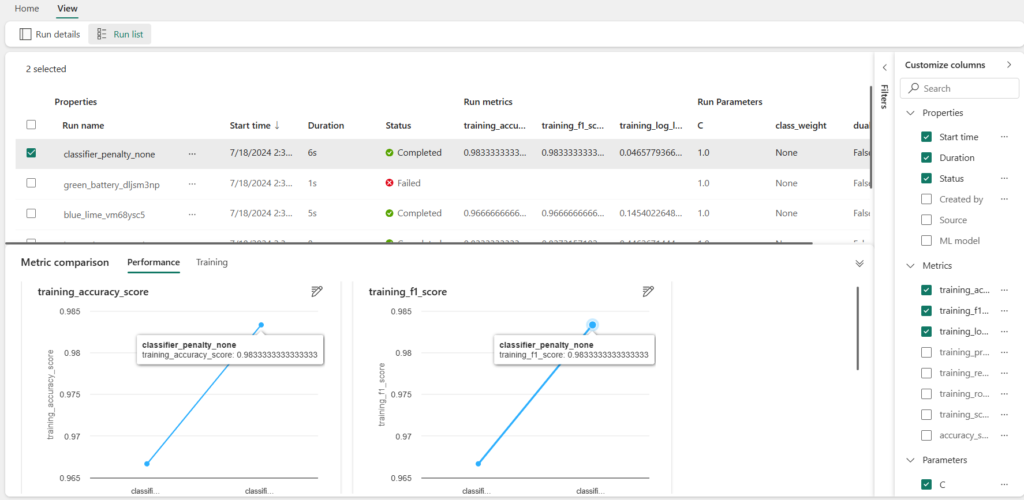
Les différents artefacts sont liés au run et l’on retrouve en particulier les graphiques générés dans le notebook.
Modifions maintenant la valeur d’un hyperparamètre de l’entrainement afin de comparer deux runs :
model = LogisticRegression(max_iter=200, penalty='None')Une bonne pratique consiste alors à modifier les noms des runs afin de savoir à quoi ceux-ci correspondent.
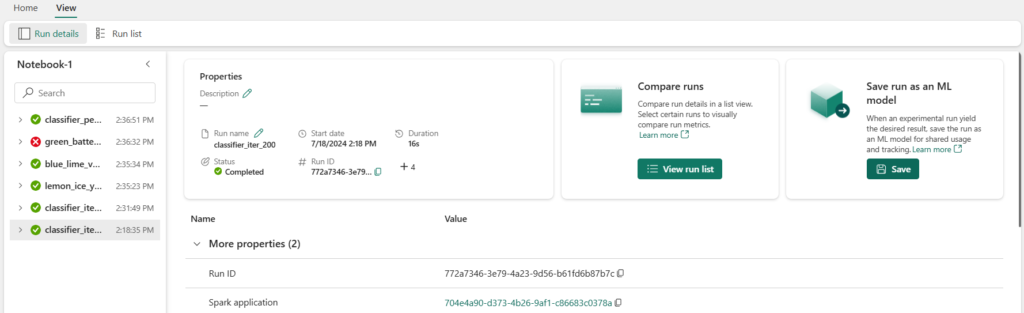
Une action manuelle sera nécessaire pour enregistrer le modèle, depuis la vue du run.
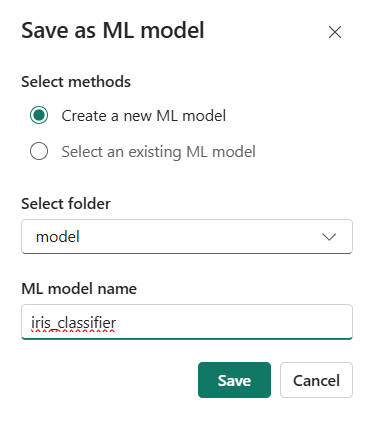
Au premier enregistrement du modèle, il est nécessaire de lui attribuer un folder (dossier) puis un nom.
La modèle est alors enregistré en version 1.
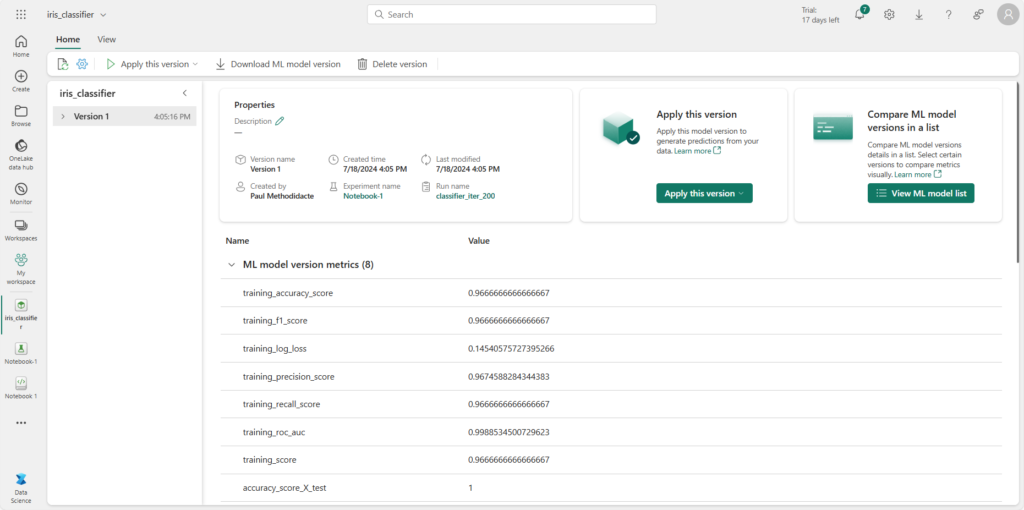
L’interface permet alors de déclencher un assistant qui génèrera le code nécessaire à l’inférence (i.e. l’utilisation du modèle pour générer des prévisions).
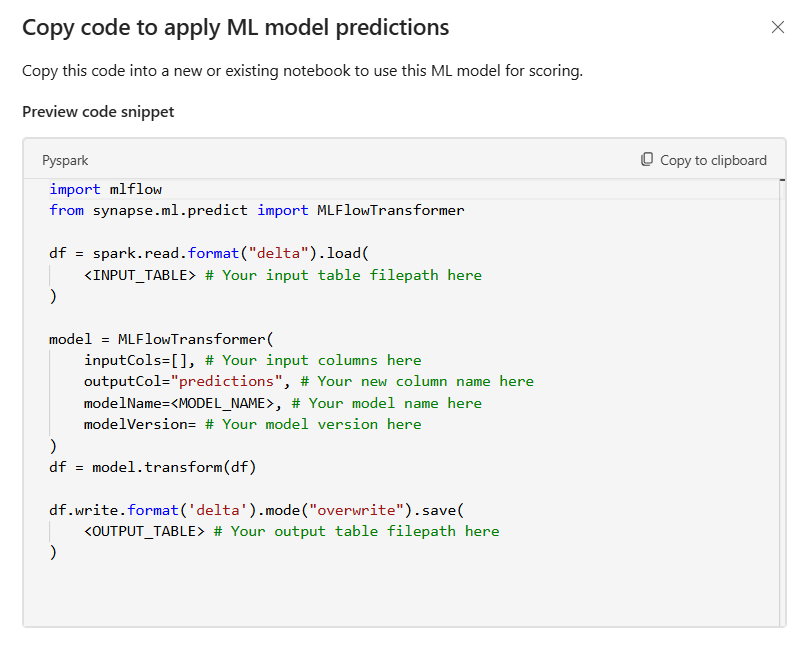
Le code généré est basé sur la librairie synapseml développé par Microsoft.
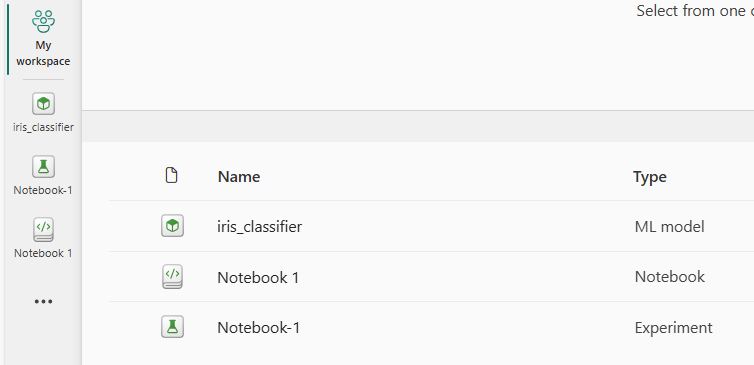
Nous disposons maintenant de trois éléments dans le workspace :
- notebook
- experiment (tous les runs)
- ML model
Syntaxes explicites MLFlow
Explorons maintenant les différentes syntaxes MLFlow qui nous permettront de :
- visualiser l’URI du serveur
- choisir les entrainements à tracer
- choisir les hyperparamètres et métriques recueillies
- enregistrer une nouvelle version du modèle
Le code exécuté de manière implicite était le suivant :
import mlflow
mlflow.autolog(
log_input_examples=False,
log_model_signatures=True,
log_models=True,
disable=True,
exclusive=True,
disable_for_unsupported_versions=True,
silent=True
)Nous commençons par importer la librairie MLFlow, déjà pré-installée sur le cluster Spark.
Le paramètre le plus important est sans doute “disable” qui permet de désactiver les logs automatiques à l’échelle du notebook (nous verrons plus tard comment le faire au niveau du workspace).
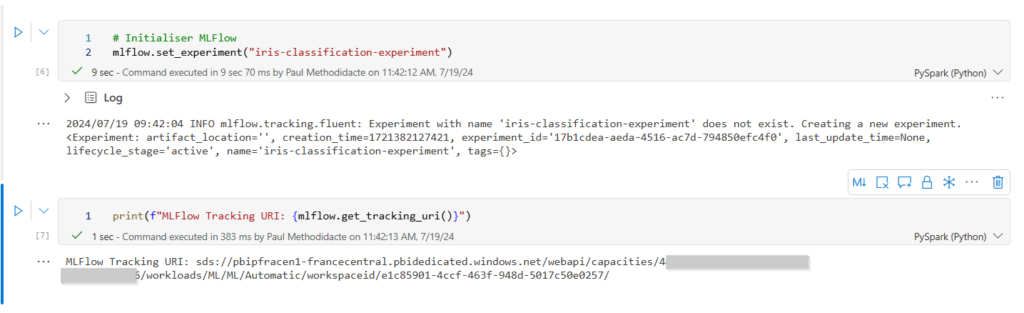
Nous pouvons maintenant définir le nom de l’experiment à l’aide de l’instruction set_experiment() et visualiser l’URI de tracking avec la syntaxe get_tracking_uri().
Voici le code de la classification, adapté pour utiliser explicitement les commandes MLFlow. Le prompt suivant a permis de générer ce code :
Ajoute les éléments nécessaires au tracking des hyperparamètres et métriques dans MLFlow
with mlflow.start_run():
# Hyperparamètres
max_iter = 200
# Créer un modèle de régression logistique
model = LogisticRegression(max_iter=max_iter)
model.fit(X_train, y_train)
# Prédire les étiquettes pour l'ensemble de test
y_pred = model.predict(X_test)
# Évaluer la performance du modèle
accuracy = accuracy_score(y_test, y_pred)
conf_matrix = confusion_matrix(y_test, y_pred)
class_report = classification_report(y_test, y_pred, output_dict=True)
# Enregistrer les hyperparamètres et les métriques dans MLFlow
mlflow.log_param("max_iter", max_iter)
mlflow.log_metric("accuracy", accuracy)
for label, metrics in class_report.items():
if isinstance(metrics, dict):
for metric_name, metric_value in metrics.items():
mlflow.log_metric(f"{label}_{metric_name}", metric_value)
# Enregistrer la matrice de confusion comme une image
plt.figure(figsize=(8, 6))
plt.imshow(conf_matrix, interpolation='nearest', cmap=plt.cm.Blues)
plt.title('Confusion Matrix')
plt.colorbar()
tick_marks = np.arange(len(iris.target_names))
plt.xticks(tick_marks, iris.target_names, rotation=45)
plt.yticks(tick_marks, iris.target_names)
fmt = 'd'
thresh = conf_matrix.max() / 2.
for i, j in np.ndindex(conf_matrix.shape):
plt.text(j, i, format(conf_matrix[i, j], fmt),
ha="center", va="center",
color="white" if conf_matrix[i, j] > thresh else "black")
plt.ylabel('True label')
plt.xlabel('Predicted label')
plt.tight_layout()
plt.savefig("confusion_matrix.png")
mlflow.log_artifact("confusion_matrix.png")
# Enregistrer le modèle entraîné
mlflow.sklearn.log_model(model, "iris-classifier-model")
# Affichage des coefficients de la régression logistique
print("Coefficients de la régression logistique:")
print(model.coef_)
# Afficher les coefficients sous forme graphique
plt.figure(figsize=(10, 5))
plt.bar(range(len(model.coef_[0])), model.coef_[0])
plt.xlabel('Features')
plt.ylabel('Coefficient Value')
plt.title('Coefficients de la Régression Logistique pour chaque Feature')
plt.savefig("coefficients.png")
mlflow.log_artifact("coefficients.png")
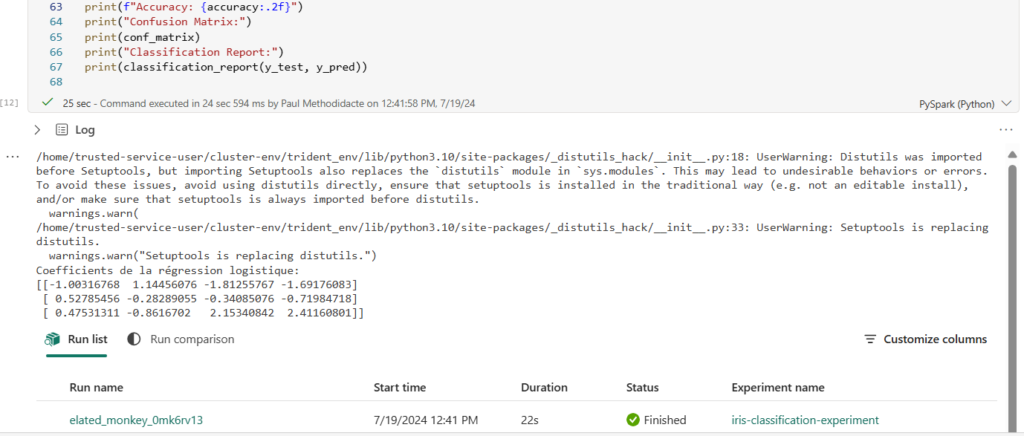
print(f"Accuracy: {accuracy:.2f}")
print("Confusion Matrix:")
print(conf_matrix)
print("Classification Report:")
print(classification_report(y_test, y_pred))
Les liens sont toujours disponibles dans les logs de la cellule du notebook.
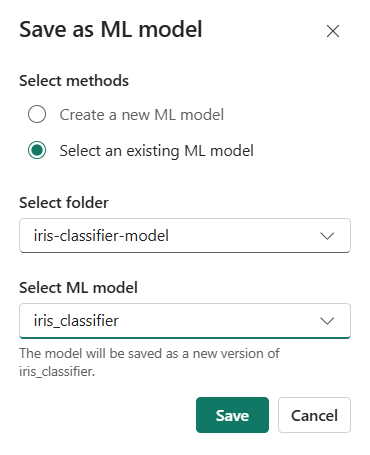
Le modèle est ainsi déjà enregistré, il n’est plus nécessaire de réaliser l’étape manuelle vue précécemment.
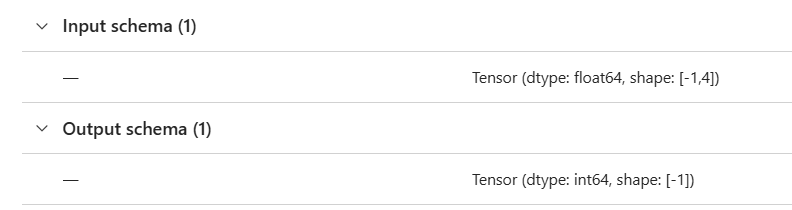
Enfin, il est possible (recommandé) d’améliorer le log du modèle en précisant des exemples d’input et d’output, ce que l’on appelle la signature du modèle.
# Enregistrer le modèle avec sa signature
from mlflow.models.signature import infer_signature
signature = infer_signature(
X_test, y_pred
)
model_name = "orders-outliers-model"
mlflow.sklearn.log_model(
model,
model_name,
signature=signature,
registered_model_name=model_name
)Pour conserver la cohérence avec l’entrainement du modèle, les couples d’objets X_train, y_train ou X_test, y_pred peuvent être utilisés.
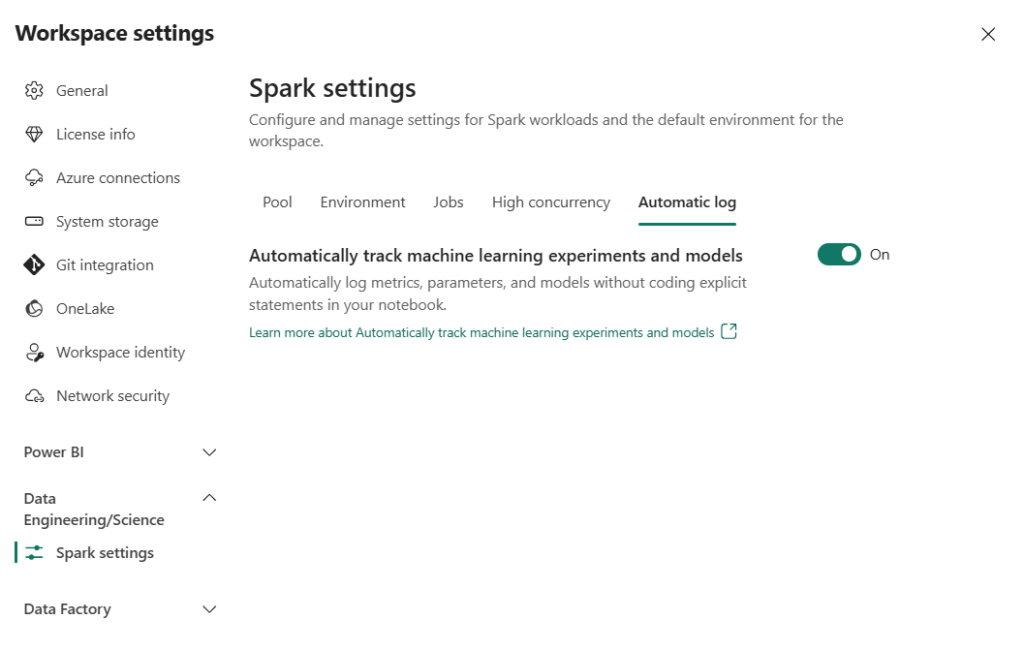
Paramètre du workspace : automatic log
Lorsque votre méthode de travail se sera arrêtée sur l’une ou l’autre des possibilités, vous pourrez jouer avec le paramètre “automatic log”, disponible à la granularité du workspace.
Si vous envisagez de maximiser la portabilité de vos notebooks (les exécuter sur Azure Machine Learning ou bien Azure Databricks par exemple), il sera sans doute plus judicieux de favoriser l’écriture explicite des commandes MLFlow.