
Lors de la conférence Build 2023, Microsoft a annoncé la sortie d’un nouveau produit dans le monde de la Data & AI. Si l’on excepte le rebranding de SQL Datawarehouse en Synapse Analytics et la sortie plus confidentielle de Data Explorer, il faut sans doute remonter à 2015 et l’arrivée de Power BI pour assister à un tel chamboulement dans l’offre de la firme de Redmond.
Dans ce premier article dédié à Microsoft Fabric, nous allons revenir sur les architectures cloud dites Modern Data Platform et Lakehouse pour bien comprendre le positionnement du produit. Ensuite, nous verrons en quoi ce nouveau service se différencie de l’existant, que ce soit Azure Synapse Analytics ou Power BI, et à qui il s’adresse.
Voici d’ores et déjà le nouveau logo avec lequel nous allons nous familiariser.

Modern Data Platform
L’architecture Modern Data Platform enchaine quatre étapes fondamentales : ingestion > stockage > calcul > exposition auxquelles peut s’ajouter une étape d’enrichissement grâce à l’intelligence artificielle (services cognitifs, machine learning).
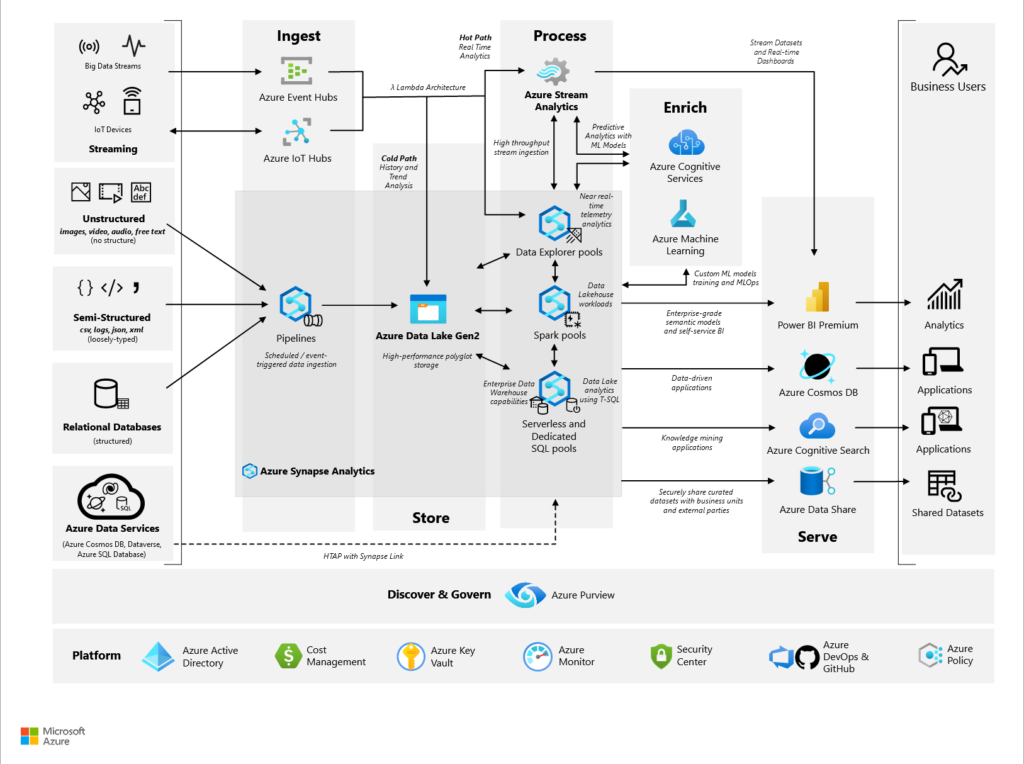
Cette architecture, bien que très complète et performante dans le cloud, par son découpage des tâches, montre une certaine complexité, non pas dans l’utilisation des différents services mais bien dans la communication entre ces services (les fameuses flèches entre les logos !). Une première réponse a été apportée avec le produit Azure Synapse Analytics qui regroupe :
- l’ingestion de données au travers d’un module similaire à Azure Data Factory
- le calcul avec les moteurs SQL (dedicated ou serverless) et Spark
- la gestion des données de streaming avec Data Explorer
Ce ne sont pas des formats propriétaires
Et vous, êtes-vous plutôt tables ou plutôt fichiers ? Il n’est plus nécessaire de choisir depuis l’essor des formats de fichiers orientés colonnes comme Apache Parquet ou Delta (ce dernier étant très fortement soutenu par la société Databricks). Plutôt que de dupliquer le contenu des fichiers dans des tables (avec tous les problèmes que cela implique : gestion des mises à jour, espace de stockage, ressources de calcul différentes…), il est beaucoup plus judicieux de travailler avec la logique d’une metastore qui contiendra uniquement les métadonnées nécessaires et autorisera l’accès aux données en langage SQL.
Microsoft Fabric est donc logiquement bâti autour de l’approche dite lakehouse et c’est même le nom du composant de stockage que l’on pourra déployer dans les espaces de travail (workspaces).
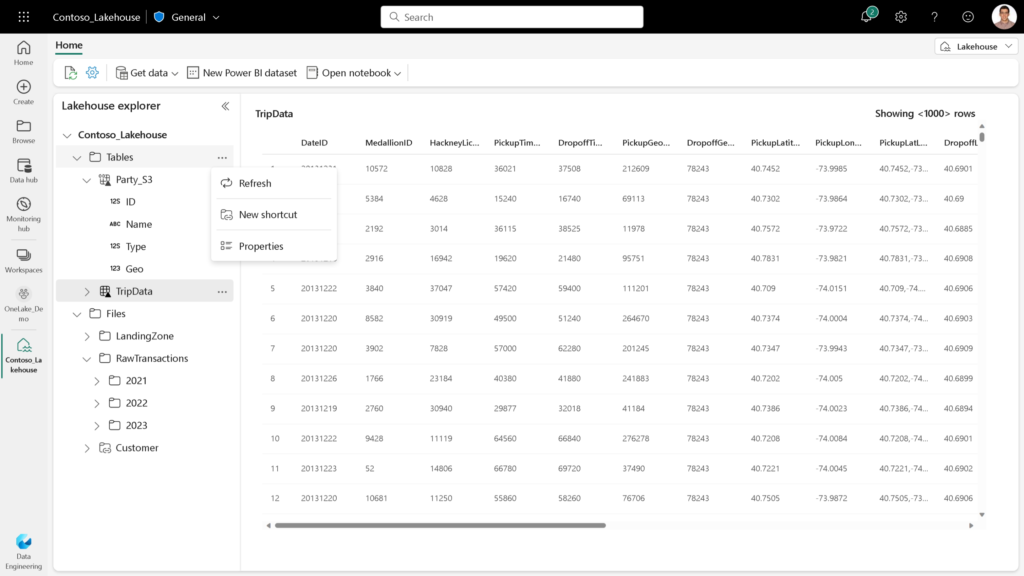
Ce n’est pas (que) Synapse Analytics
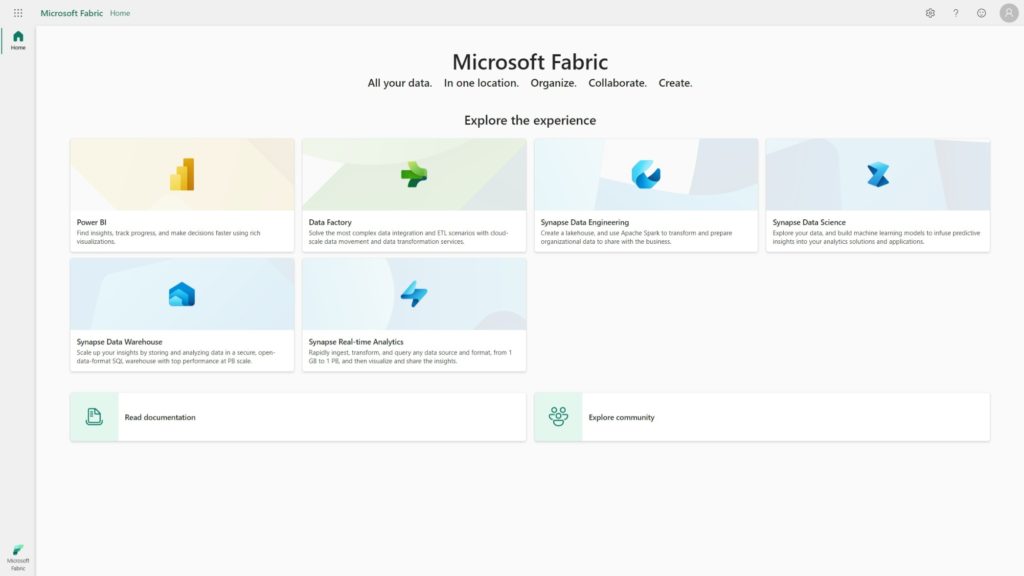
Avec Microsoft Fabric, le niveau d’intégration de ces différentes briques est maintenant complet, puisque le produit gère simultanément :
- le stockage sous le nom de “OneLake” (il faut voir ici une similitude, au moins dans le nom, avec OneDrive)
- l’ingestion avec toujours Data Factory (ses nombreux connecteurs, ses pipelines visuels)
- le calcul, toujours avec Spark ou SQL, mais cette fois sans distinction dedicated ou serverless
- la data science s’appuyant sur Azure Machine Learning
- le stockage et calcul des données de streaming avec Synapse Data Explorer
- l’exposition avec le service Power BI
- l’ordonnancement avec un nouveau composant à venir, nommé Data Activator, que l’on peut rapprocher par exemple du rôle d’un service comme Azure Logic Apps
Un nouveau service Power BI ?
Microsoft Fabric est un produit de type Software as a Service (SaaS). Il n’y a donc pas de client à installer localement, tout se fait au travers d’un navigateur web. Si vous connaissez bien Power BI, vous savez qu’historiquement, deux actions ont longtemps été absentes de l’édition des rapports dans le navigateur : la modélisation et les calculs DAX. Ces opérations sont désormais réalisables dans l’interface en ligne.
Les utilisateurs de Power BI ont également dû longtemps choisir entre rapidité d’affichage (mode import) et donnée fraîche (mode Direct Query). Le mode hybride avec par exemple, la gestion de tables d’agrégats a pu permettre de trouver un compromis mais il fallait un niveau d’expertise assez avancée pour se lancer dans une telle approche. Aujourd’hui, Microsoft Fabric propose le concept de Direct Lake, qui, comme son nom l’indique, propose de travailler sur un mode “Direct Query” sur les sources disponibles dans OneLake.
Malgré l’existence des pipelines de déploiement (licence Premium exigée), l’approche DevOps dans Power BI a toujours été très laborieuse. Nous disposerons, avec Microsoft Fabric, d’un source versioning dans les repositories Azure DevOps (autres gestionnaires à venir sans doute prochainement). Reste à voir en pratique comment se mettra en place le travail collaboratif.
Autre nouveauté sur le plan de la gouvernance et de l’organisation des différents projets : la notion de domain. Les traditionnels groupes de travail (workspaces) peuvent maintenant être assignés à des domaines (sous-entendus fonctionnels), facilitant ainsi la structuration des éléments au sein du tenant.
Qui sont les personae ?
C’est bien toute la famille de la data qui va se réunir au sein de Microsoft Fabric !
Les data engineers vont trouver leur marque dans les menus issus de Synapse Analytics : ingestion de données, pipelines de transformation voire jobs Spark pour les plus codeurs.
Les data scientists manipuleront les environnements, les expériences et les modèles tout comme dans Azure Machine Learning.
Les data analysts connaissent déjà bien l’interface du service Power BI et n’auront plus à basculer du client desktop à l’interface web.
Enfin, les différents modules no code conviendront parfaitement aux “data citizen“, qui pourront travailler sur l’ensemble de la chaîne sans avoir à coder.
Dans quelles langues parlons-nous ?
On peut parfois redouter le passage à un nouveau produit car celui-ci implique un temps d’apprentissage en particulier quand il est nécessaire d’appréhender de nouveaux langages. Avec Microsoft Fabric, nous sommes en terrain connu. Voyons cela en détail.
Data engineering (chargement des données)
Il existe quatre modes de chargement de la donnée au sein d’un lakehouse :
- les dataflow (de génération 2) : no code ou langage M
- les data pipelines (Data Factory) : no code voire low code si l’on considère les quelques formules qui peuvent être utilisées
- les notebooks s’exécutant dans un environnement Apache Spark, avec les langages Scala, Python (API pyspark) ou Spark SQL
- les shortcuts (no code) qui permettent de pointer vers une source déjà présente au sein de OneLake ou bien vers une source externe comme ADLS gen2 ou Amazon S3
Data Warehouse
Ici, et comme depuis un demi-siècle, le langage SQL est roi ! Nous sommes bien évidemment dans la version T-SQL de Microsoft, enrichi par quelques fonctions propres à Synapse Analytics.
Data Science
Nous sommes en terrain connu (et conquis !) pour les scientifiques de données : Scala, Python & R. Pour ces deux derniers, il sera nécessaire d’utiliser les API pyspark et SparkR pour profiter pleinement de la puissance du moteur de calcul distribué.
Streaming
L’intégration du produit Azure Data Explorer s’accompagne bien sûr du langage KustoQL (KQL) pour le chargement et l’interrogation des données.
Modélisation décisionnelles et mesures
Depuis l’arrivée des modèles tabulaires concurrençant les modèles multi-dimensionnels, le langage DAX s’est imposé pour manipuler la couche sémantique de la Business Intelligence. Ici, rien ne change.
OpenAI en copilote ?
Le partenariat entre la société OpenAI et Microsoft s’est renforcé en novembre 2022 et le succès planétaire de ChatGPT a montré tout le potentiels de l’IA générative pour les outils bureautiques (Microsoft Copilot à venir prochainement), comme dans le monde du développement (GitHub Copilot). Microsoft Fabric s’appuie également sur les fundation models tels que GPT ou Codex.
Vous connaissiez la création de visuel en langage naturel depuis plusieurs années dans Power BI ? Voici maintenant la création de rapport ! Le copilot demande une description en quelques mots des attentes en termes de reporting ou d’analyse et la page de rapport se génèrera automatiquement. Tout simplement magique ! Finalement, les spécifications ne sont-elles pas l’étape la plus importante d’un projet de tableau de bord ?
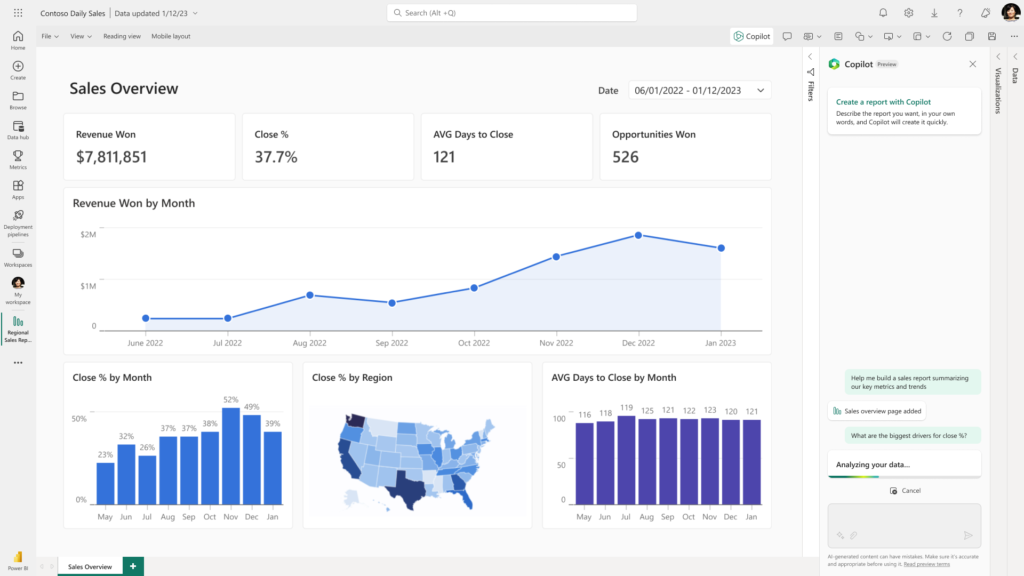
Vous pouvez retrouver plus de détails sur le blog officiel de Power BI.
En attendant la mise en pratique
En conclusion, et avant de passer véritablement aux tests de cette nouvelle plateforme, nous pouvons saluer l’effort de vision de bout en bout de la part de Microsoft, qui vise à fédérer pour les acteurs de la data dans l’entreprise autour d’une même source et d’une gouvernance unifiée.
N’oublions pas non plus le service Azure Databricks qui reste sans doute la plateforme d’entreprise pour les projets Big Data sur Azure, et qui dispose également d’une vision unifiée des usages de la donnée.
De nombreux éléments demandent maintenant à être vérifier dans la pratique :
- le coût exact du produit à l’usage
- la capacité à monter à l’échelle avec la volumétrie ou la vélocité requise
- la collaboration entre les profils data (engineer, analytist, scientist…)
- la simplicité de gouvernance (data discovery, data catalog, lineage…)
- la possibilité de travailler dans des environnements multi-tenants
- … (liste non exhaustive)
Mais que les utilisateurs se rassurent d’ores et déjà : il sera toujours possible d’obtenir les données dans Excel 🙂 !