
Le cluster Spark managé que propose Azure Databricks permet l’exécution de code, présent dans des notebooks, dans des scripts Python ou bien packagés dans des artefacts JAR (Java) ou Wheel (Python). Si l’on imagine une architecture de production, il est nécessaire de disposer d’un ordonnanceur (scheduler) afin de démarrer et d’enchaîner les différentes tâches automatiquement.
Nous connaissions déjà les jobs Databricks, nous pouvons dorénavant enchaîner plusieurs tasks au sein d’un même job. Chaque task correspond à l’exécution d’un des éléments cités ci-dessus (notebook, script Python, artefact…). Comme il s’agit à ce jour (mars 2022) d’une fonctionnalité en préversion, il est nécessaire de l’activer dans les Workspace Settings de l’espace de travail.
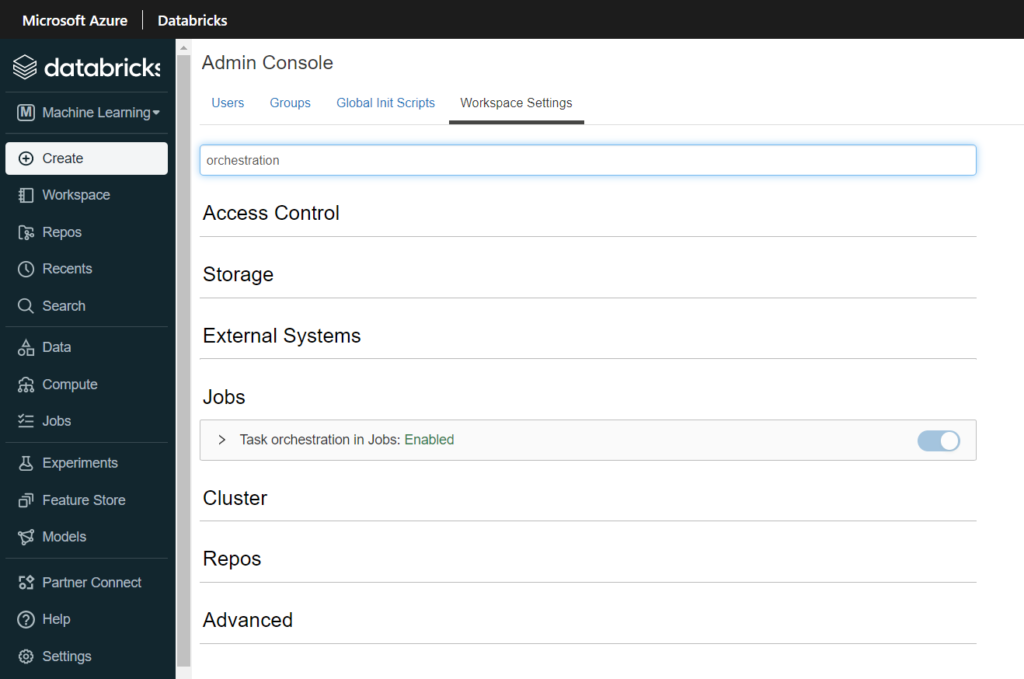
Le principal intérêt d’enchainer des tasks à l’intérieur d’un même job est de conserver le même job cluster, qui se différencie des interactive clusters par… sa tarification ! En effet, celui-ci est environ deux fois moins cher qu’un cluster utilisé par exemple pour des explorations menés par les Data Scientists.
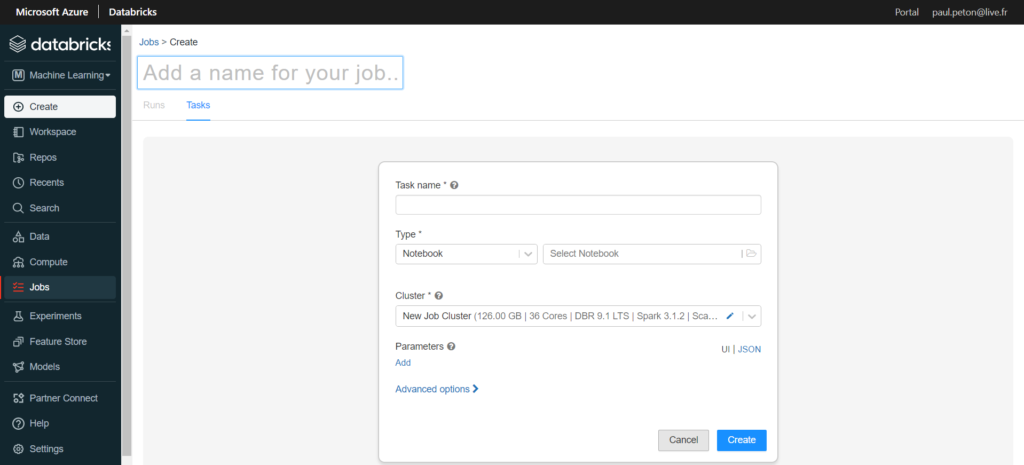
Le menu latéral nous permet de lancer la création d’un nouveau job (pensez à bien le nommer dans la case située en haut à gauche).
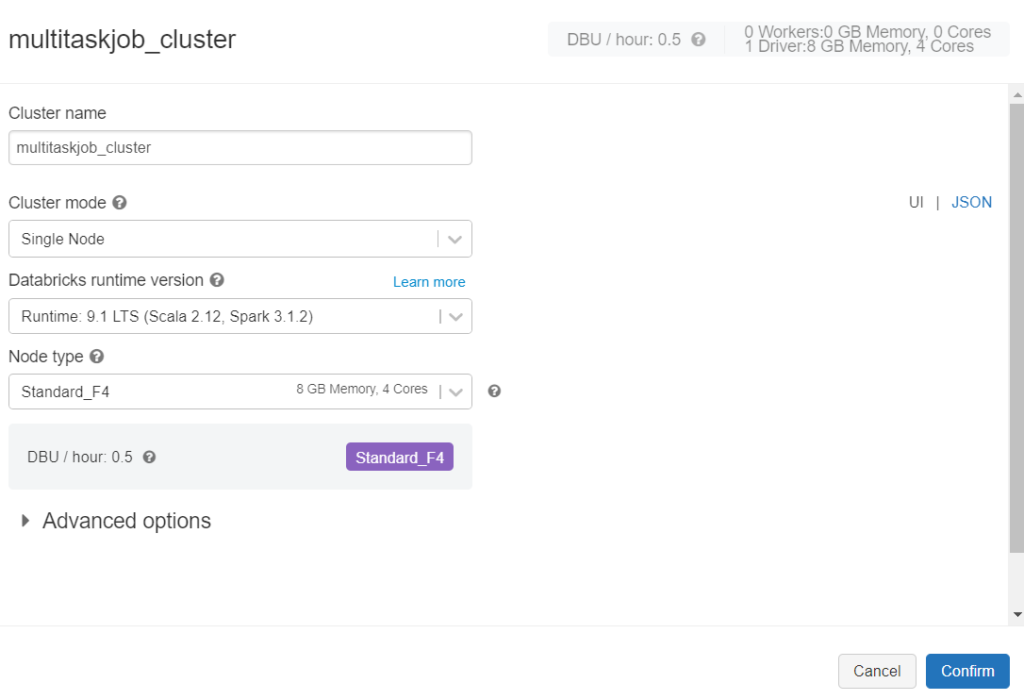
Pour réaliser nos premiers tests, nous utiliserons un job cluster de type “single node”, associée à une machine virtuelle relativement petite.
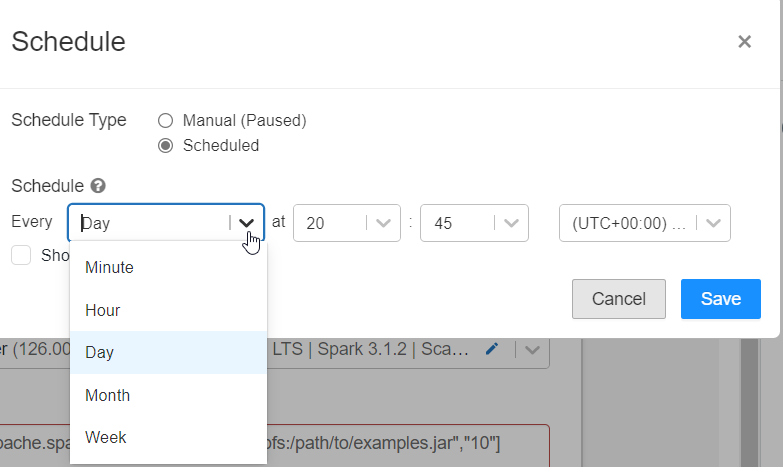
Le job se planifie à un moment donné, défini par une interface graphique ou une syntaxe classique de type CRON telle que : 31 45 20 * * ?
Nous pourrons retrouver tous les logs d’exécution dans l’interface “jobs” de l’espace de travail.
Passer des informations d’une tâche à une autre
L’enchainement de tâches nous pousse rapidement à imaginer des scénarios où une information pourrait être l’output d’une tâche et l’input de la suivante. Malheureusement, il n’existe pas à ce jour de fonctionnalité native pour répondre à ce besoin. Nous allons toutefois explorer ci-dessous deux possibilités. Il existe également quelques variables réservées pouvant être passées en paramètres de la tâche : job_id, run_id, start_date…
Passer un DataFrame à une autre tâche
Nous nous orienterons tout naturellement vers le stockage d’une table dans le metastore de l’espace de travail Databricks.
- écriture d’un DataFrame en table : df = spark.read.parquet(‘dbfs:/databricks-datasets/credit-card-fraud/data/’)
- lecture de la table : df = spark.table(“T_credit_fraud”)
Ceci ne peut être réalisé avec une vue temporaire, créée au moyen de la fonction createOrReplaceTempView(), celle-ci disparaissant en dehors de l’environnement créé pour son notebook d’origine.

Passer une valeur à une autre tâche
Nous profitons du fait que le job cluster soit commun aux différentes tâches pour utiliser le point de montage /databricks et y écrire un fichier. Nous pouvons ainsi exploiter les commandes dbutils et shell (magic command %sh) :
- dbutils.fs.mkdirs() permet de créer un répertoire temporaire
- dbutils.fs.put() écrit une chaîne de texte dans un fichier
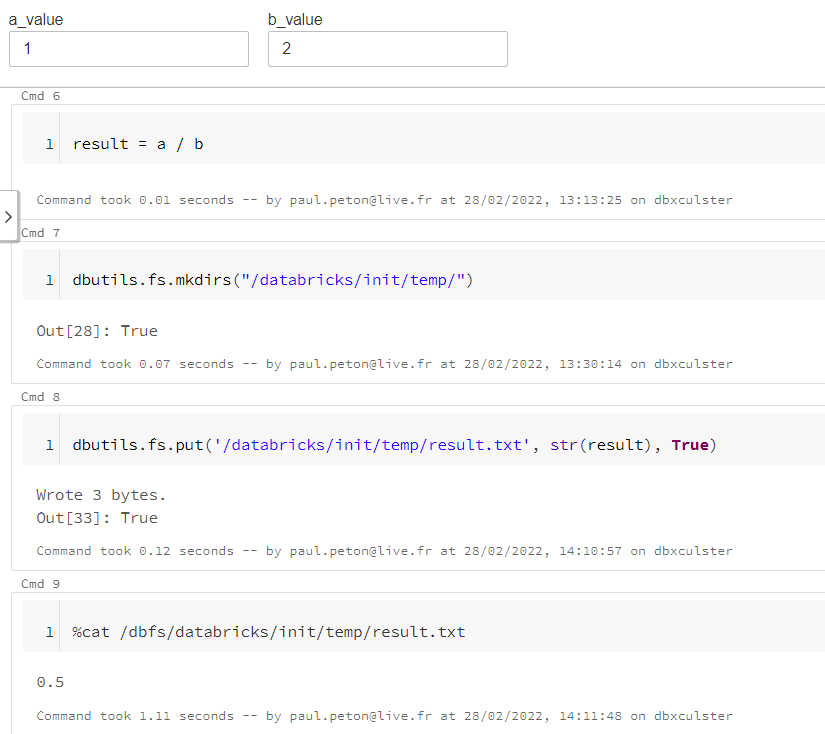
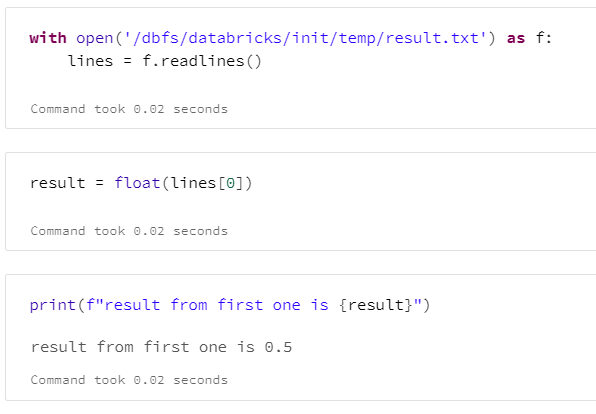
Nous vérifions ici la bonne écriture de la valeur attendue mais la commande shell cat ne permet pas de stocker le résultat dans une variable. Nous utiliserons une commande Python open() en prenant soin de préfixer par /dbfs le chemin du fichier créé lorsla tâche précédente. Attention également à bien récupérer le premier élément de la liste lines avec [0] puis à convertir la valeur dans le type attendu.
Quand continuer à utiliser Azure Data Factory ?
Dans une architecture data classique sous Azure, et orientée autour des outils PaaS, c’est le service Azure Data Factory qui est généralement utilisé comme ordonnanceur.
Si l’enchainement des tâches peut se conditionner en utilisant le nom des tâches précédentes, celui-ci n’aura lieu qu’en cas de succès des autres tâches.
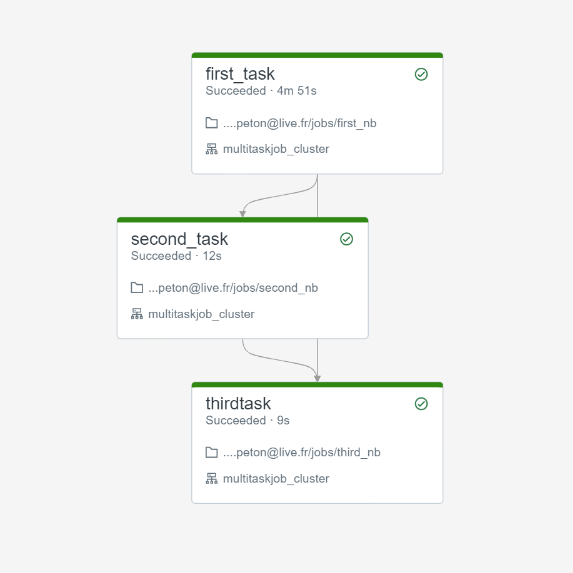
Il n’est donc pas possible de prévoir un scénario similaire à celui présenté ci-dessous, où l’enchainement se ferait sur échec d’une étape précédente.
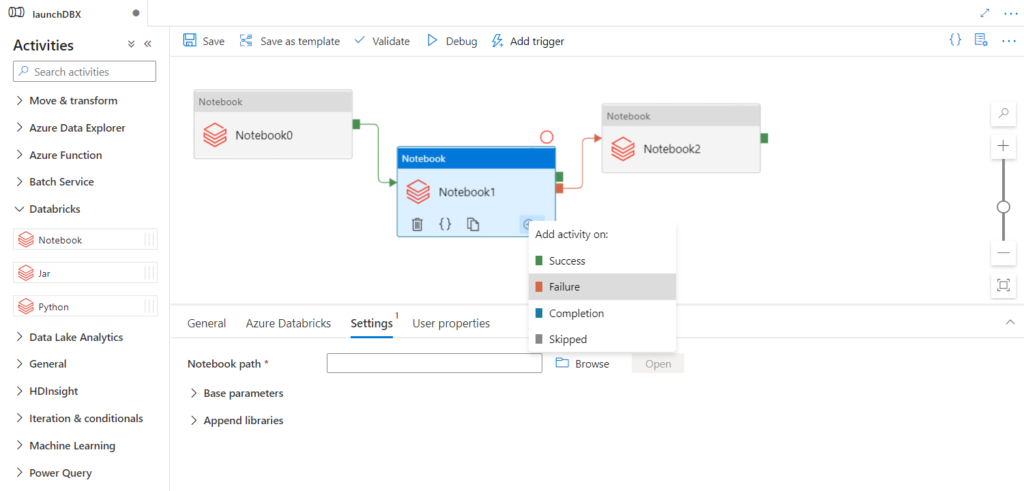
Les déclenchements de jobs Databricks ne se font que sur une date / heure alors qu’il serait possible dans Azure Data Factory de détecter l’arrivée d’un fichier, par exemple dans un compte de stockage Azure, puis de déclencher un traitement par notebook Databricks.
Côté fonctionnalité de Data Factory, nous attendons que les activités Databricks puissent exécuter également des packages Wheel, comme il est aujourd’hui possible de le faire pour les JAR. Une solution de contournement consistera à utiliser la nouvelle version de l’API job de Databricks (2.1) dans une activité de type Web.
En conclusion, il s’agit là d’une première avancée vers l’intégration dans Databricks d’un nouvel outil indispensable à une approche DataOps ou MLOps, même si celui-ci est pour l’instant incomplet. Les fonctionnalités de Delta Live Tables, encore en préversion également, viendront aussi compléter les tâches traditionnellement dévolues à un ETL.