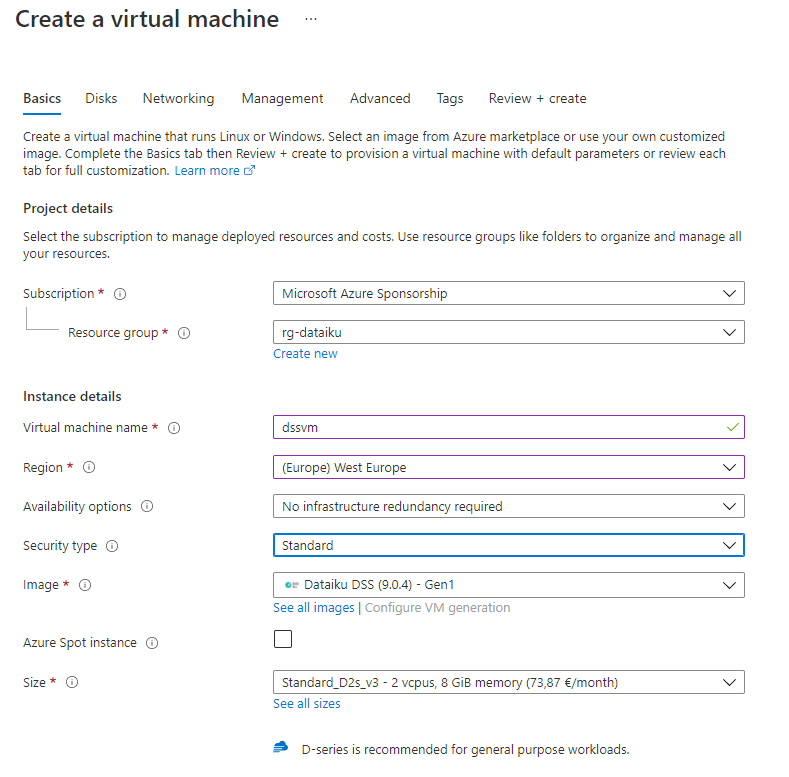
Suite à l’article initial sur l’installation de la sandbox Dataïku DSS, nous allons maintenant voir comment faire interagir le studio avec un compte de stockage Azure Blob Storage. Nous souhaiterons bien sûr lire des fichiers de données mais aussi écrire des données dite “raffinées” suite aux opérations de nettoyage et de transformation pouvant être réalisées par la plateforme de Dataïku.
Les tests relatés ci-dessous ont été réalisés avec ma collègue Sulan LIU.
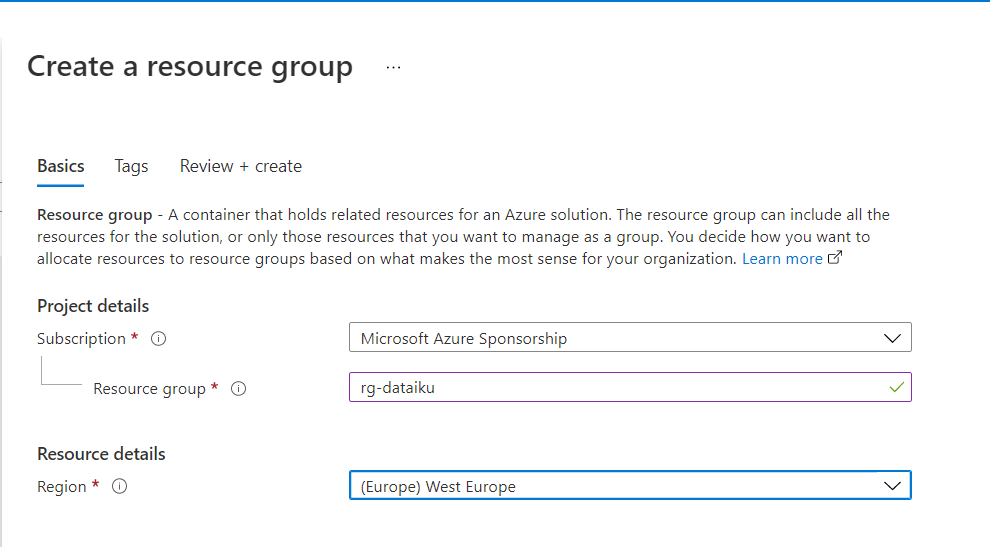
Création d’un compte de stockage blob
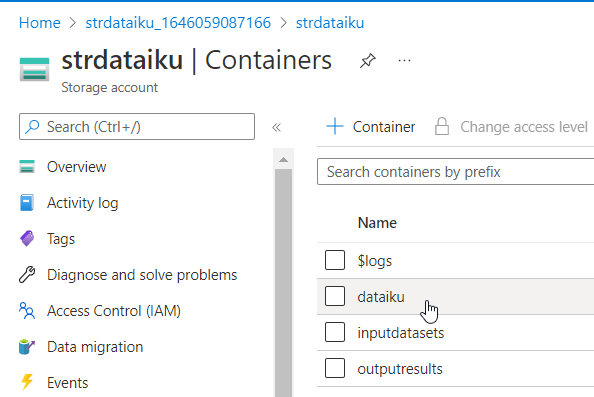
Nous disposons d’un compte de stockage créé sur le portail Azure, dans lequel nous pourrons définir plusieurs conteneurs (containers). Nous verrons ci-dessous l’intérêt de disposer de plusieurs de ces répertoires physiques.
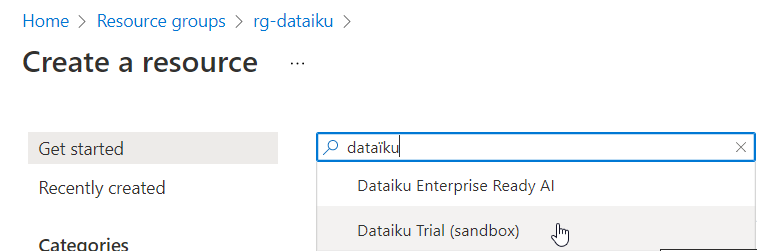
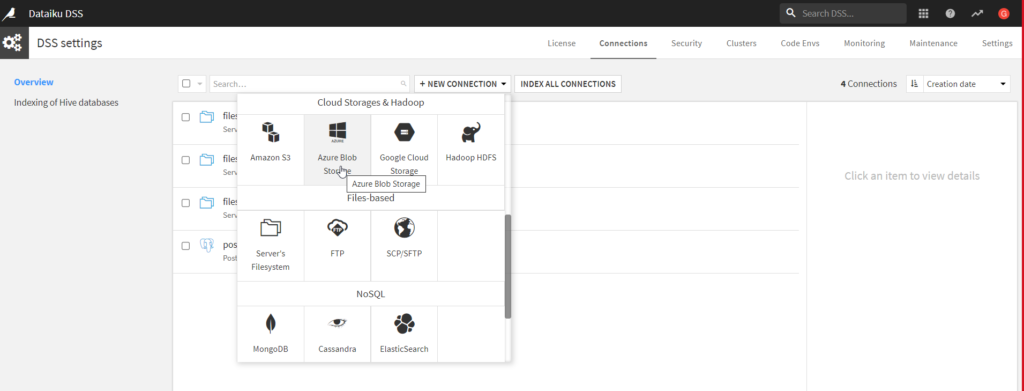
A partir du menu DSS settings puis Connections, nous pouvons cliquer sur le bouton “+NEW CONNECTION” et choisir le cloud storage Azure Blob Storage.
Nous allons maintenant détailler les principales options disponibles pour définir cette connexion.
Connection
La première information attendue est le nom que portera cette connexion du sein du Data Science Studio.
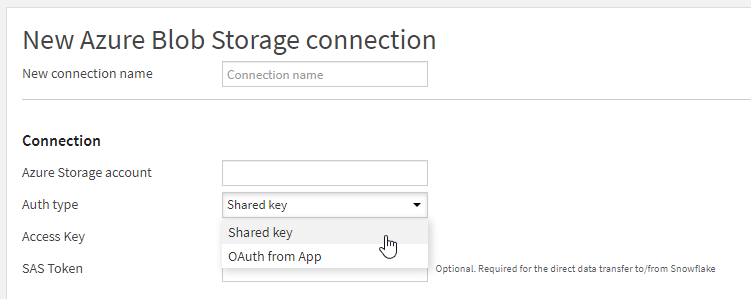
Nous pouvons ensuite choisir entre deux modes d’authentification vis à vis de la ressource Azure.
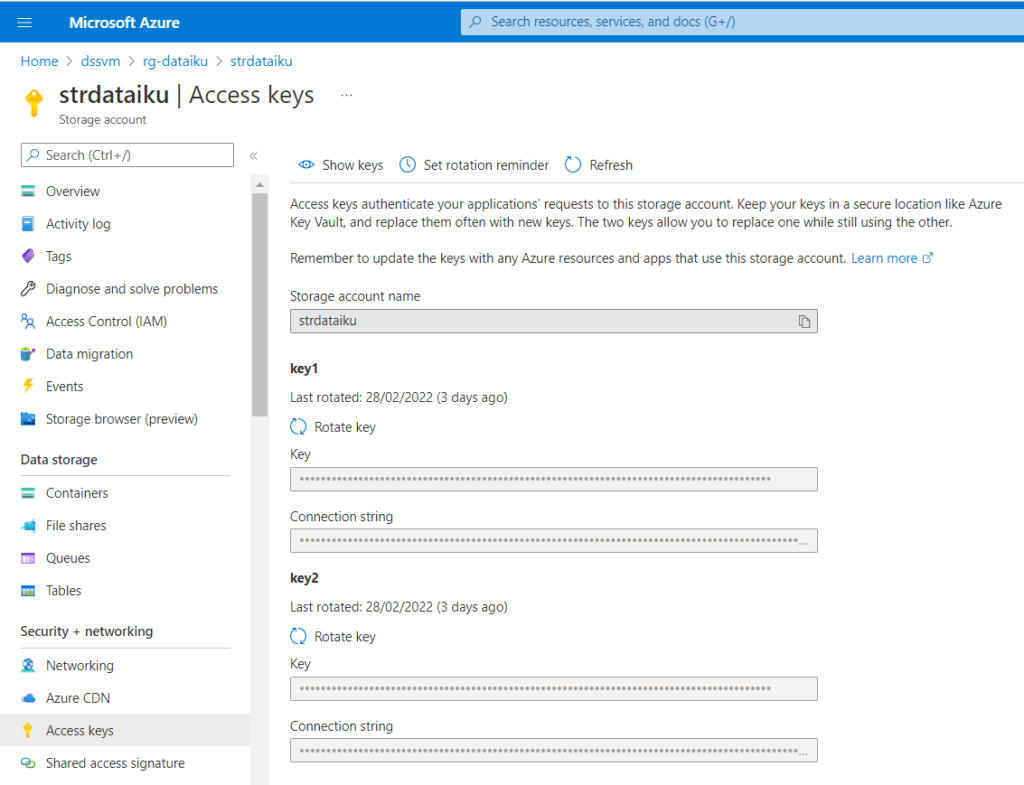
Le premier mode donne un accès total au compte de stockage au moyen du nom du compte de stockage et de la clé d’accès du compte de stockage. Selon les données contenues sur ce stockage, ce mode de connexion ne sera sans doute pas recommandé.
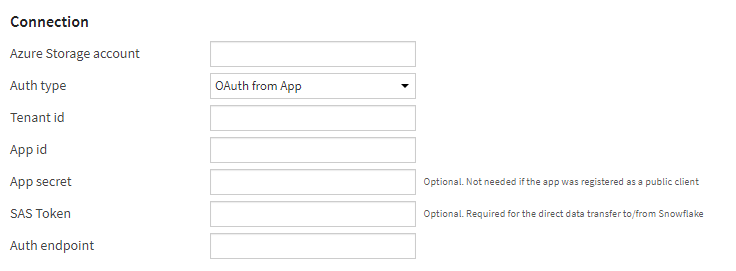
Nous pourrons préférer le mode de connexion “OAuth from App” correspondant à un principal de service déclaré dans l’annuaire Azure Active Directory.
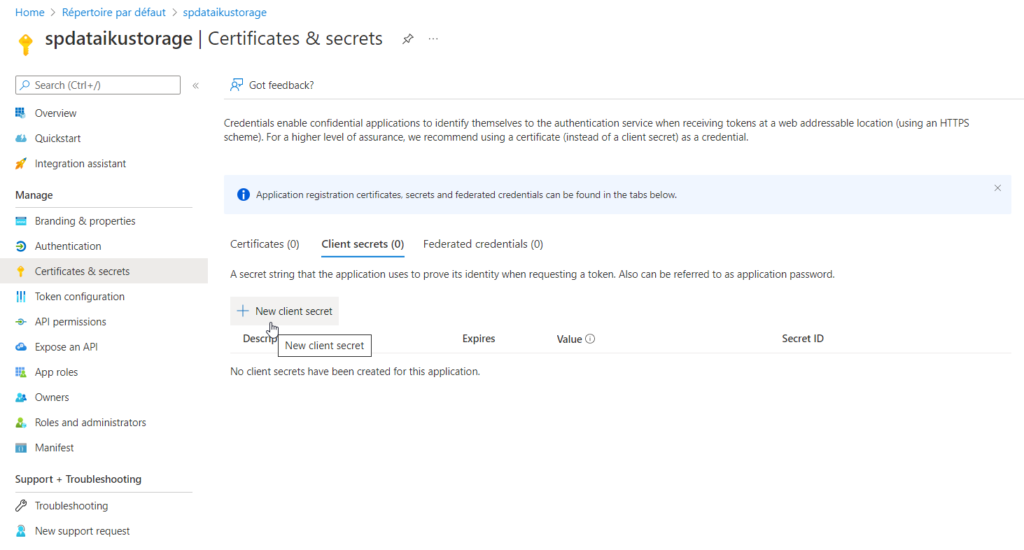
Après la création du principal de service (menu “app registration”), il faut créer un secret associé.
Il sera bien sûr nécessaire de donner à cette identité des droits “Storage Blob Data Contributor” sur la ressource de stockage Azure.
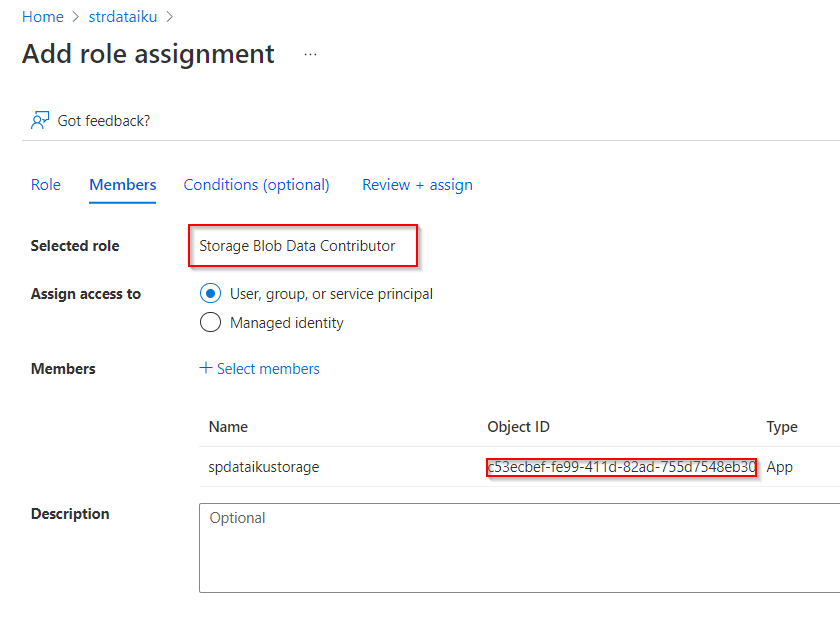
Path restriction and default container
Une connexion peut être définie vers la totalité des containers ou avec une restriction sur l’un d’eux. Une bonne pratique me semble être de définir une connexion par conteneur, afin de bien isoler les rôles (données brutes en entrée, données préparées intermédiaires, prévisions en batch…).

Si l’on ne définit pas de conteneur dans la connexion, il est impératif qu’un conteneur par défaut existe. Sans modification de la valeur par défaut, celui-ci doit être nommé dataiku (sans tréma sur le i).
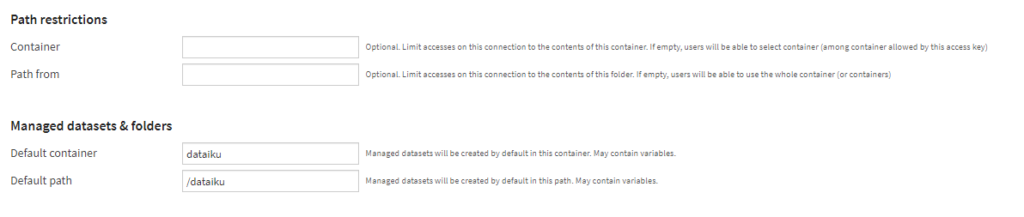
Security settings
Les paramètres de sécurité vont enfin permettre de donner des droits d’utilisation à tous les utilisateurs “analysts” ou bien seulement à des groupes.
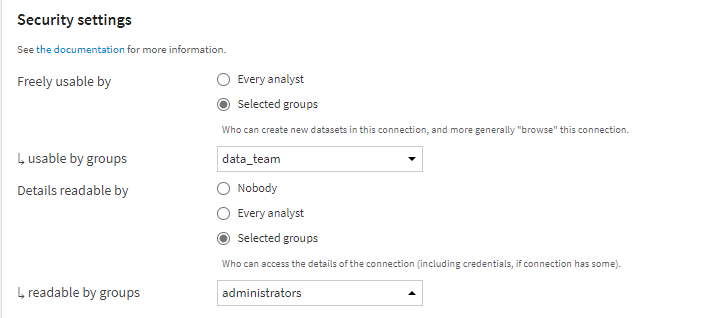
Une bonne pratique consistera à ne donner l’autorisation “Details readable” qu’à un groupe administrateur de la plateforme. En effet, ce droit donne accès à la configuration de la connexion et donc par exemple à l’App ID (client ID) du principal de service.
Lecture et écriture de jeux de données
Nous pouvons maintenant démarrer un nouveau projet au sein du Data Science Studio et nous commençons logiquement par la définition d’un premier dataset.
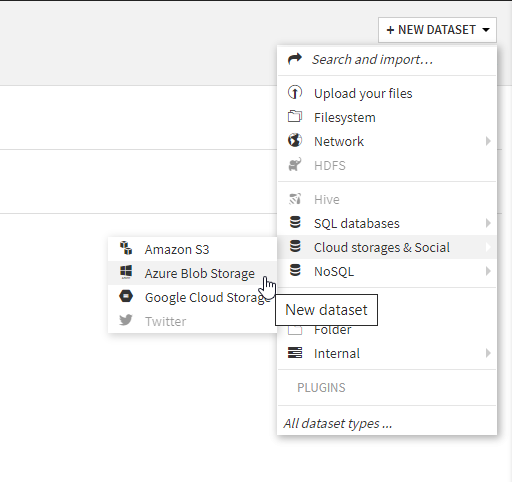
Nous vérifions que la connexion précédemment définie apparaît bien dans la première liste déroulante.
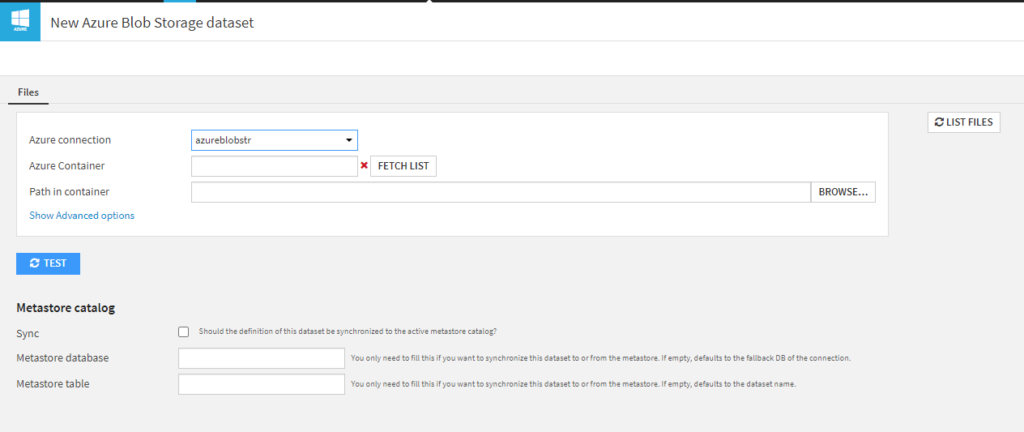
Il sera ensuite nécessaire de cliquer sur le bouton FETCH LIST pour voir apparaître les containers autorisés.
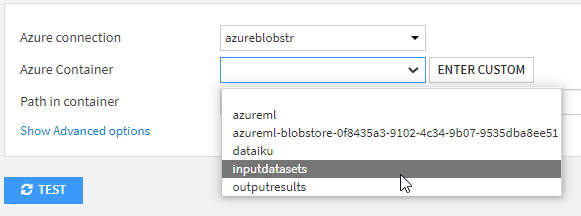
Le bouton BROWSE permet alors de choisir le fichier voulu.
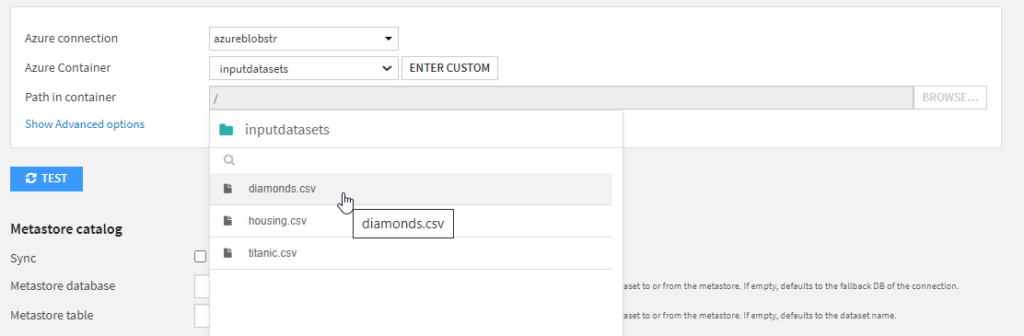
Un message nous informe du bon parsing (séparation des colonnes) du fichier.
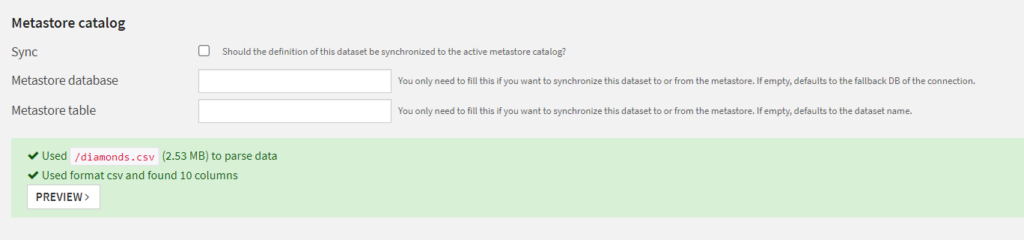
Un aperçu du jeu de données (PREVIEW) est alors disponible et nous pouvons voir que les colonnes ont été automatiquement typées. Un rapide contrôle visuel sera toutefois souhaitable. Nous pouvons par exemple rencontrer une colonne dont les premières valeurs (celles de l’aperçu) seraient vides.
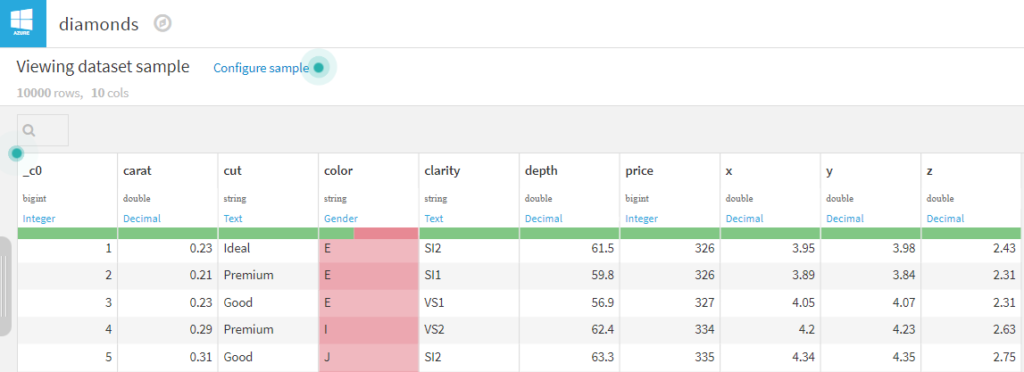
Nous pouvons maintenant construire un premier flow basé sur ce jeu de données.
Nous ajoutons quelques opérations de transformation au sein d’une “recipe“.
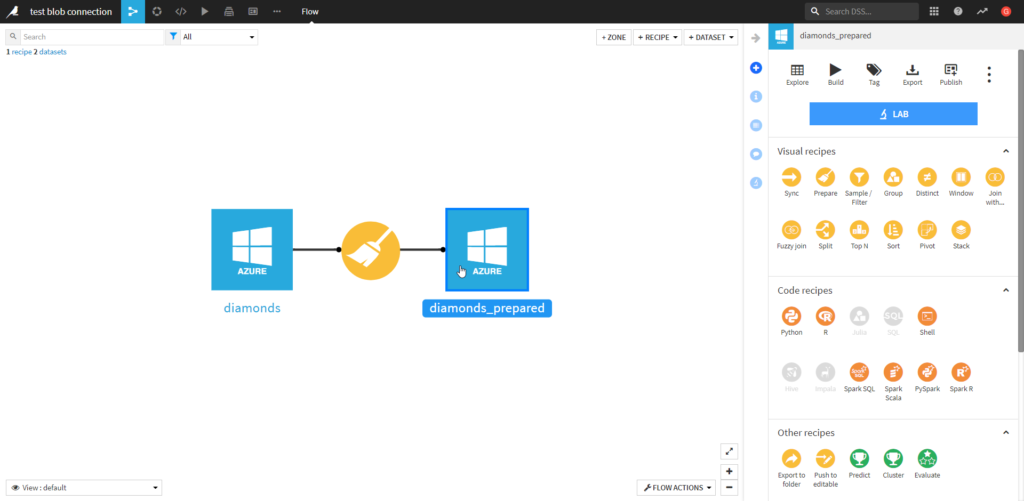
A la fin de la préparation des données, nous définissions l’output dataset. Dans la liste déroulante “Store into”, nous retrouvons naturellement la connexion définie au compte de stockage.
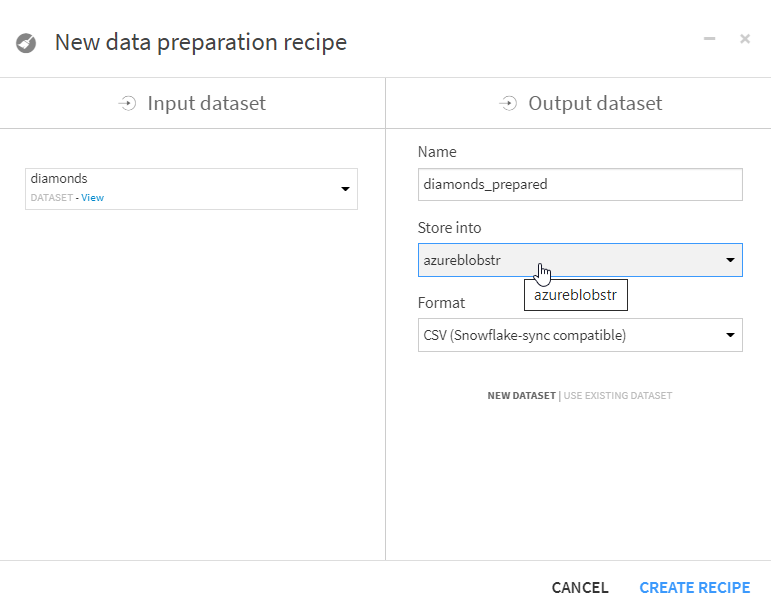
Vous pourriez, à cette étape, rencontrer le message d’erreur ci-dessous.
Dataset error – Failed to check if the new dataset name is safe, there could be a problem with the database: Failed to get information for location '', caused by: NoSuchElementException: An error occurred while enumerating the result, check the original exception for details., caused by: StorageException: The specified container does not exist.
Ce message nous alerte sur le fait que le container nommé “dataiku” n’a pas été créé. Veuillez vérifier ce point, présenté en tout début d’article.
Nous vérifions que le dataset s’est bien enregistré dans le container du compte de stockage.
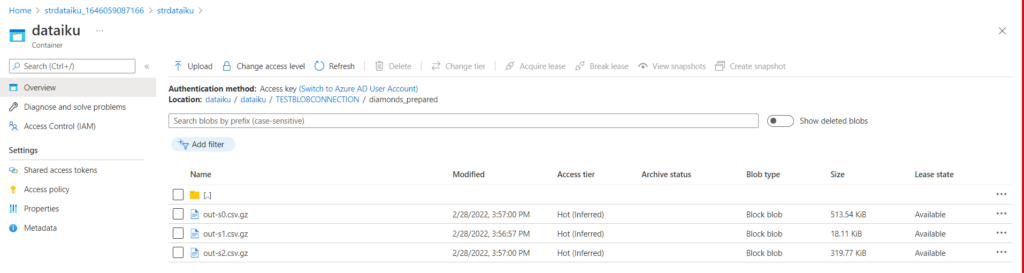
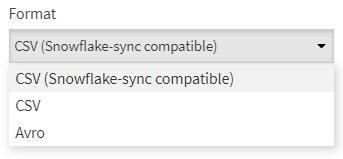
Nous remarquons que le dataset, enregistré au format CSV et compressé (.gz), est partitionné automatiquement. Nous disposons de trois choix de format, le format Avro étant un format dit orienté colonne et également compressé.
Dans la version sandbox de Dataïku DSS, nous ne pourrons en revanche pas utiliser une ressource de type Azure Synapse Analytics pour lire et écrire des données. En effet, un driver JDBC est nécessaire mais les répertoires de la machine virtuelle ne sont pas accessibles. Nous aborderons donc la version Enterprise de Dataïku DSS dans de prochaines articles.