Azure Data Factory est un service managé du cloud Azure, de type “low code”, aussi bien utile pour ses fonctionnalités d’ETL/ELT que d’ordonnanceur. On appréciera particulièrement d’y intégrer toute une chaîne de traitements et d’avoir ainsi un espace centralisé de lecture des logs d’exécution.
Si ce service commence à prendre de l’importance dans vos projets data, vous souhaiterez certainement développer dans une ressource qui n’est celle de production. Se posera donc alors la question du déploiement continu entre ressources.
Lier Data Factory à un repository
Avant de déployer, il est bien sûr nécessaire de versionner les développements ! Cela sera possible dans l’un des deux outils du monde Microsoft : GitHub ou Azure DevOps. Il est possible de définir le repository à la création de la ressource mais nous pouvons le faire, plus facilement, après l’instanciation.
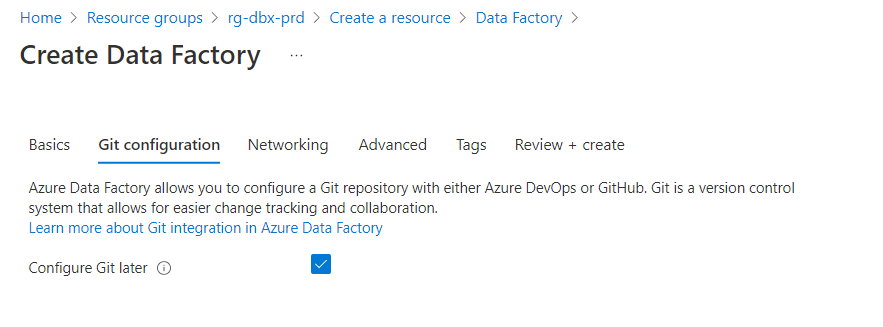
A la première connexion au Studio Data Factory, nous configurons le repository, en choisissant ici une organisation et un projet Azure DevOps. Il n’est pas nécessaire d’importer le contenu de ce repository qui doit être vide pour l’instant.
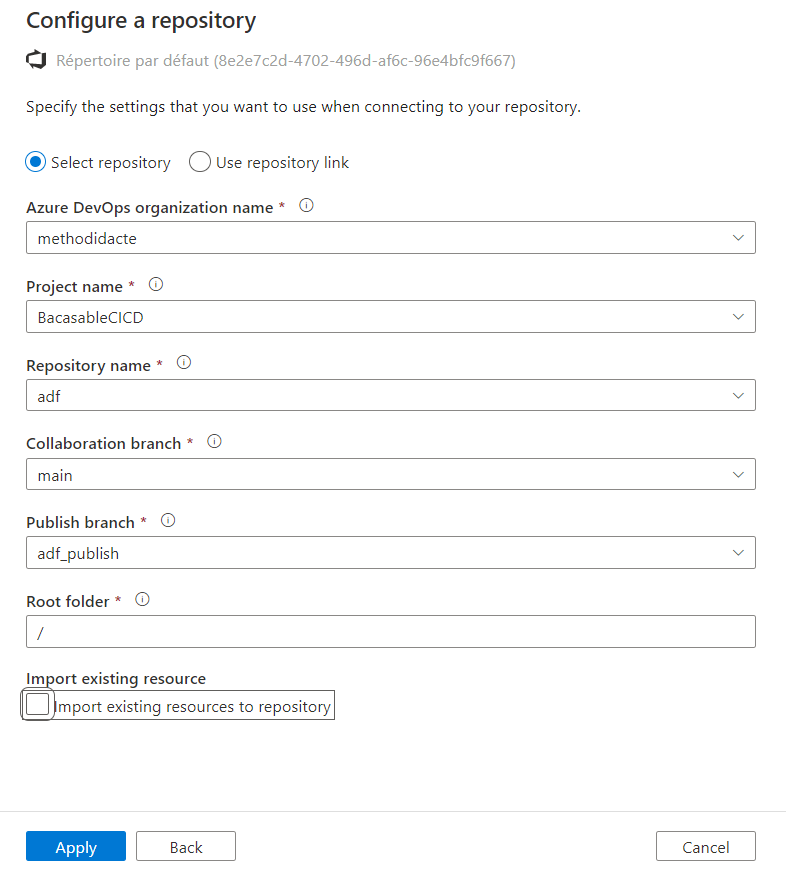
Notons tout de suite un fonctionnement propre à Data Factory que sera le travail sur deux branches :
- une branche principale (nommée ici main), de collaboration
- une branche de “publication” au nom réservé : adf_publish
Nous verrons lors du déploiement le rôle joué par cette seconde branche. Nous terminons la configuration en définissant la branche main comme la branche de travail.
Il sera possible par la suite de créer des branches apportant de nouvelles fonctionnalités ou réalisant des corrections puis d’effectuer des opérations de merge (fusion) avec la branche principale.
Terminons cette première partie sur une notion fondamentale : les environnements de destination lors du déploiement (pré-production, production…) ne doivent pas être liés au repository. C’est en effet une opération spécifique (un pipeline de release) qui viendra déposer le code, mais ce dernier ne doit pas pouvoir être modifié en dehors de l’environnement de développement.
Créer un premier service lié
Les services liés sont les premiers éléments à créer dans Data Factory car ils “hébergent” les datasets ou représentent une ressource de calcul comme c’est le cas pour le service de clusters Spark managé Azure Databricks. Ce sont aussi les services liés qui sont les plus dépendants des environnements (dev, uat, prod…) car ils pointent vers d’autres ressources auprès desquelles une authentification est bien souvent nécessaire.
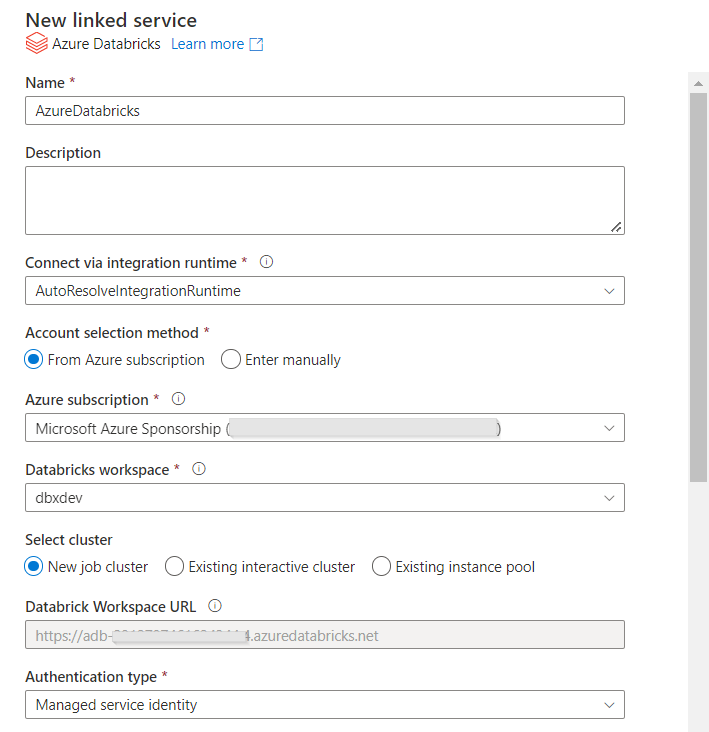
Voici une bonne pratique : ne pas utiliser un nom spécifique à l’environnement (par exemple ls_DatabricksDev) car ce nom doit refléter la ressource dans chaque environnement et nous ne pourrons pas le modifier.
En revanche, plusieurs propriétés ainsi que l’authentification devront être modifiées lors du déploiement entre environnements.
Pour un service lié Databricks, nous choisissons de nous authentifier à l’aide d’une identité managée, qu’il faudra déclarer en tant que “Contributor” au niveau de l’access control (IAM) de la ressource Databricks.
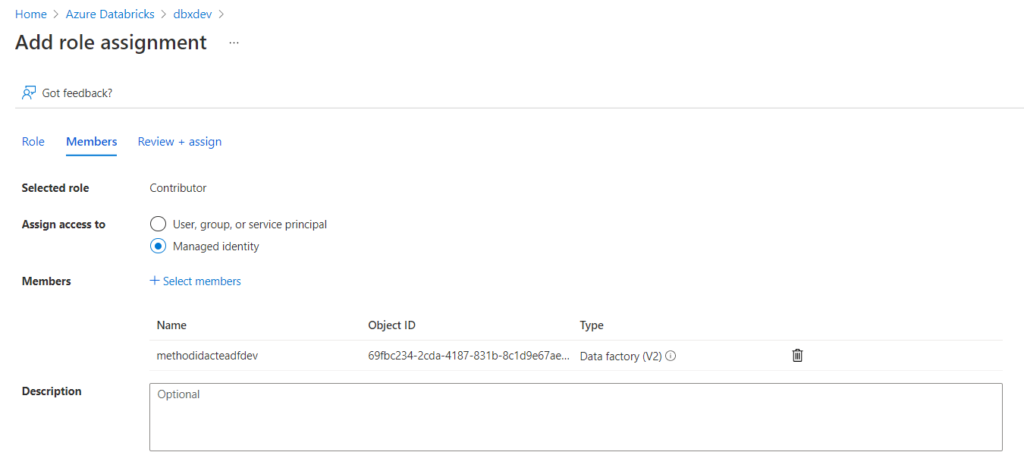
Pour vérifier que l’authentification est bien réalisée, nous déroulons les listes “cluster version” et “cluster node type”, remplacées par un message “failed” si la connexion n’est pas valide.
Il s’agit là d’une autre bonne pratique : privilégier les identités managées car celles-ci ont un périmètre très bien défini, appartiennent à l’annuaire Azure Active Directory et ne demanderont pas de manipulation lors du déploiement continu, à l’inversion d’un token ou d’un password.
Lors de la création ou de la modification d’éléments dans le Studio Data Factory, nous pouvons sauvegarder ces changements à tout moment puis réaliser une publication à l’aide du bouton “Publish”.
L’action Publish correspond à un “commit – push” sur le repository lié.
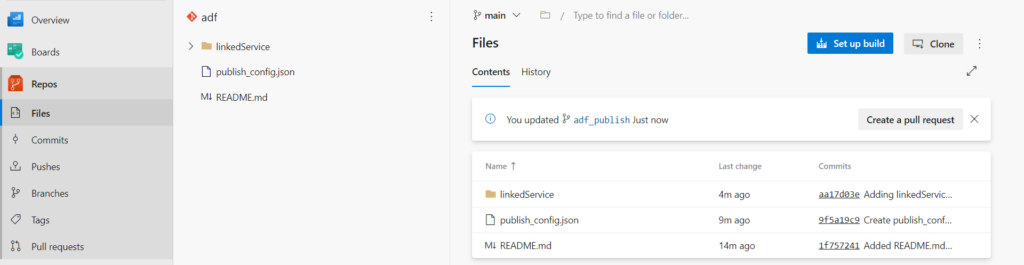
Nous retrouvons dans le repository les deux branches évoquées lors de l’association à Azure DevOps.
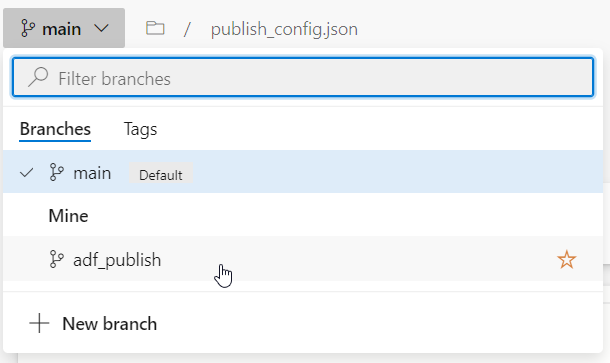
La branche adf_publish contient en particulier deux fichiers nommés respectivement ARMTemplateForFactory.json et ARMTemplateParametersForFactory.json. Ceux-ci contiennent les noms propres à l’environnement et qui devront donc être remplacés lors du déploiement.
Afin de pousser la démonstration, nous ajoutons et démarrons un trigger dans le Studio Data Factory (nous verrons son importance un peu plus tard dans cet article).
Déployer par pipeline de release
Le pipeline de release convient à ce que nous cherchons à faire : déployer un environnement vers un autre, à partir d’un code versionné.
Nous démarrons le pipeline avec un “empty job”.
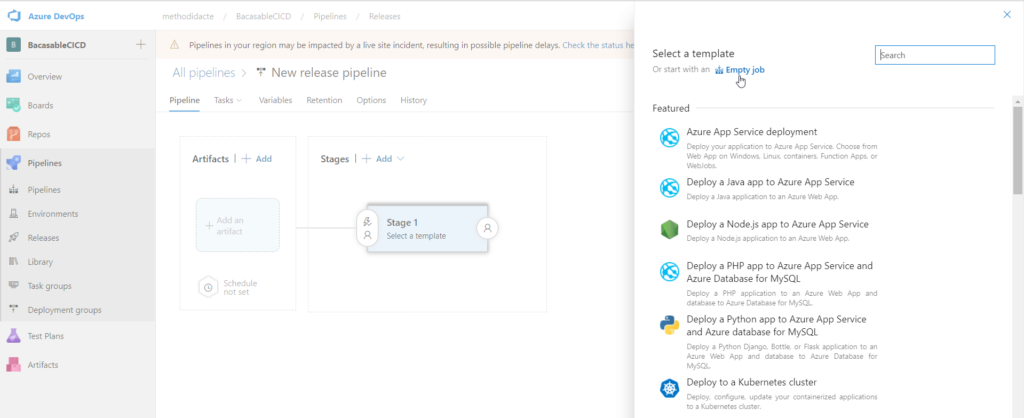
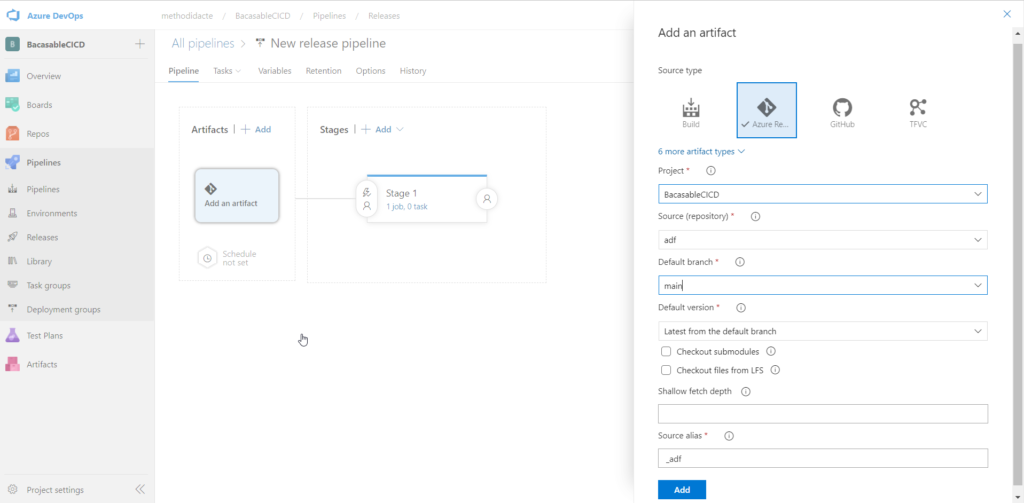
La première chose à faire est de lier l’artefact (le code versionné) au pipeline. Attention, c’est bien la branche main et non adf_publish qui est attendue ici.
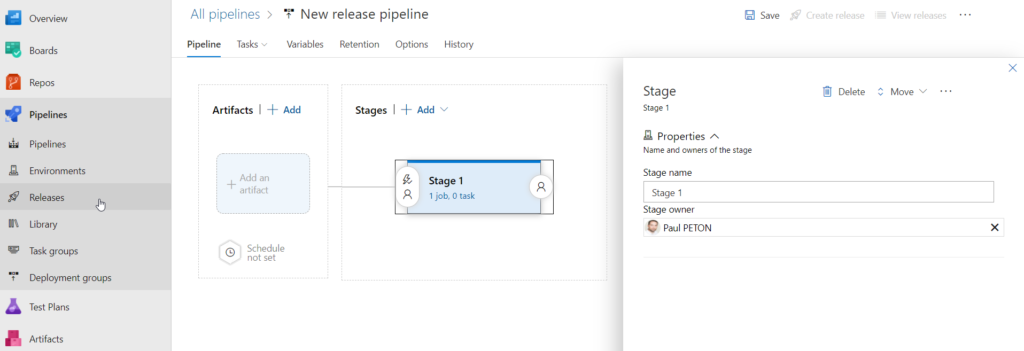
Passons ensuite au paramétrage du stage, qui pourra être renommé par le nom de l’environnement cible (uat, prod…).
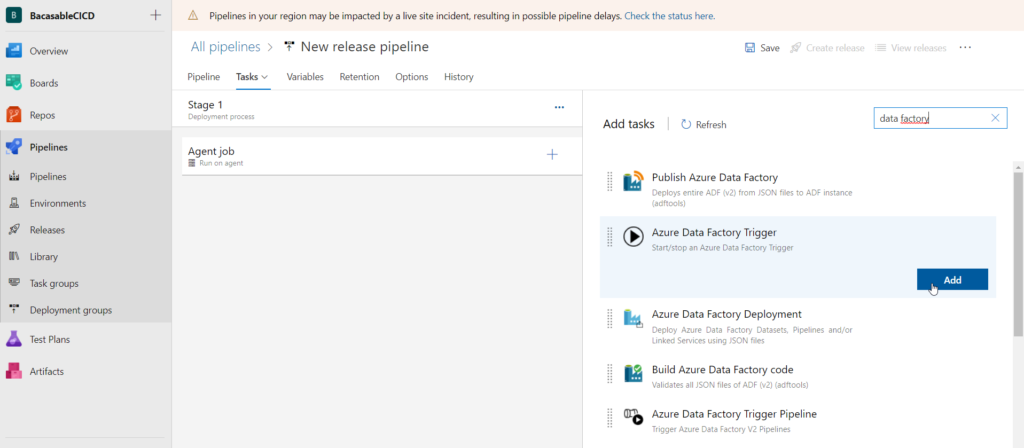
Nous recherchons dans la Market Place les tâches correspondant à Data Factory. Une installation sera nécessaire à la première utilisation.
Je vous recommande le produit développé par SQLPlayer. En effet, nous allons voir de multiples avantages (et un inconvénient…).
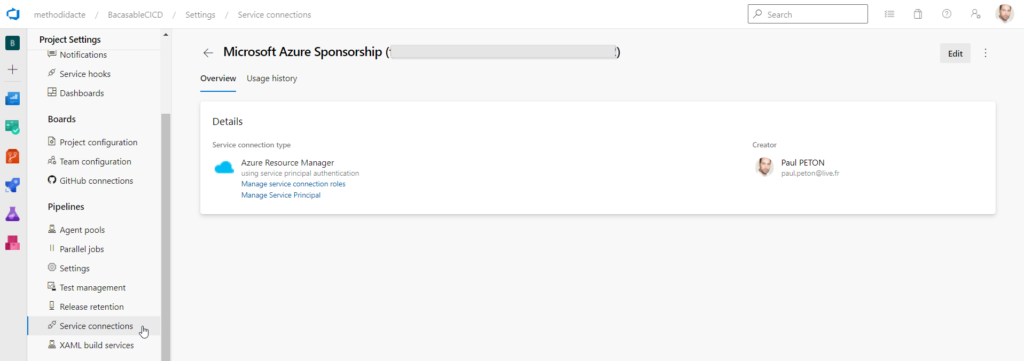
Autoriser le composant à accéder à une ressource Azure va demander de créer une service connection. Des droits suffisants sur Azure sont nécessaires pour réaliser cette opération.
Dans la boîte de dialogue ci-dessous, les champs attendus concernent l’environnement cible :
- nom du groupe de ressource
- nom de la ressource Azure Data Factory
- chemin vers le répertoire des fichiers JSON (branche adf_publish)
- nom de la région où est située la ressource
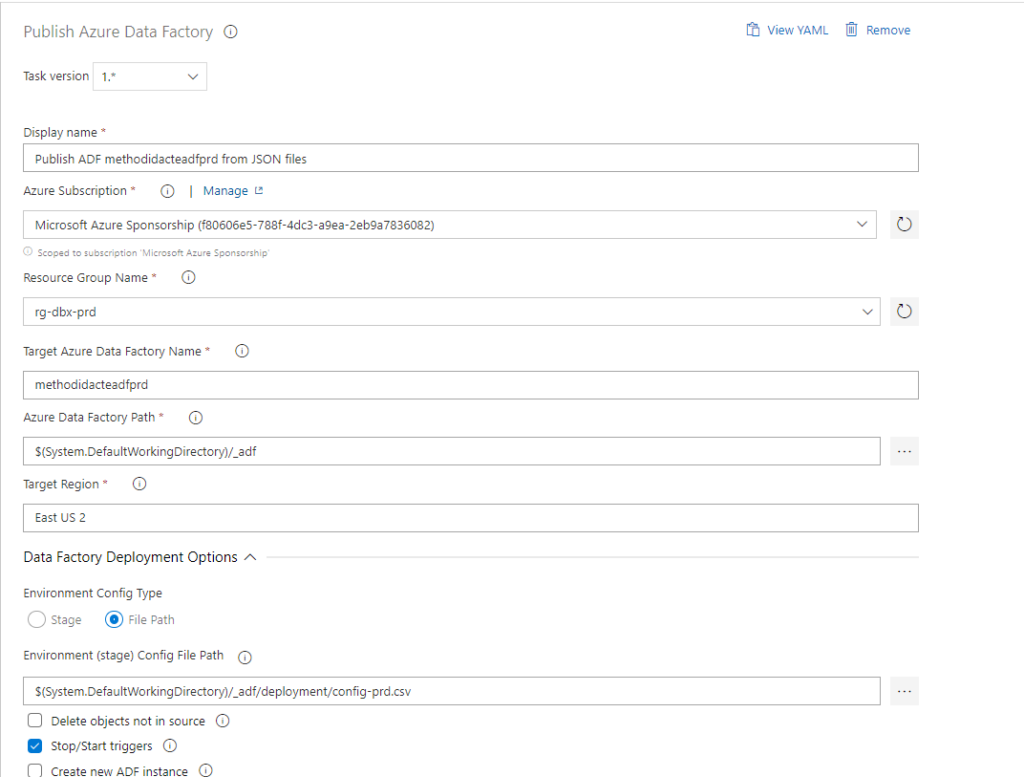
Pour indiquer le path du dossier contenant les fichiers du template ARM, nous utilisons une nouvelle boîte de dialogue, en prenant soin de descendre un cran au-dessous du repository.
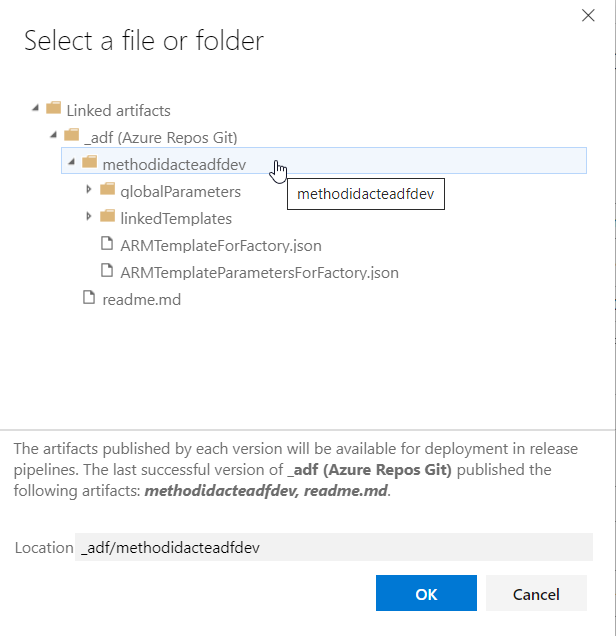
Veillez également à cocher la case “Stop/Start triggers”. En effet, le déploiement ARM ne pourra avoir lieu si des triggers sont actifs. C’est ici un avantage de cette extension : il n’est pas nécessaire d’ajouter par exemple un script PowerShell réalisant le stop puis le start. Une limite de l’approche par PowerShell consiste dans le fait que l’intégralité des triggers sont redémarrés. Il serait donc nécessaire de supprimer les triggers qui ne sont pas utilisés, plutôt que de les mettre en pause.
A ce stade, une première release pourrait être lancée et elle déploiera à l’identique l’environnement de développement.
Modifier les paramètres propres à l’environnement
Nous avons évoqué ci-dessus les fichiers JSON de la branche adf_publish. Ceux-ci permettent de réaliser un déploiement de template ARM (Azure Resource Manager), qui correspond à une approche dite Infra as Code, propre à l’univers Azure de Microsoft.
Pour déployer les développements vers un autre environnement, nous devons remplacer certaines valeurs :
- nom de la ressource Data Factory
- chaines de connexion
- identifiant et mot de passe
- URL
- certains paramétrages spécifiques (ex.: type et dimension d’un cluster Databricks)
Nous allons ici préciser toutes les modifications à apporter au moyen d’un fichier CSV qui sera stocké sur la branche main du repository, dans un répertoire deployment et nommé config-{stage}.csv où la valeur de stage indique l’environnement cible.

Voici un exemple de fichier CSV qui transforme les informations nécessaires pour changer de workspace Azure Databricks. Les noms de colonnes en première ligne doivent être respectés.
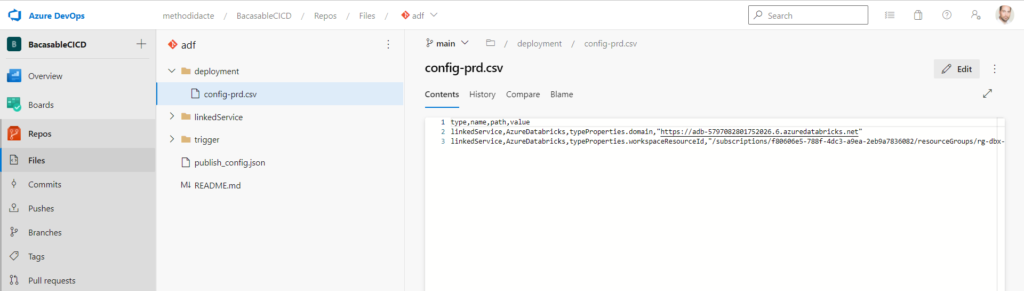
type,name,path,value linkedService,AzureDatabricks,typeProperties.domain,"https://adb-xxx.x.azuredatabricks.net" linkedService,AzureDatabricks,typeProperties.workspaceResourceId,"/subscriptions/xxx-xxx-xxx-xxx/resourceGroups/rg-dbx-prd/providers/Microsoft.Databricks/workspaces/dbxprd"
Une documentation complète, sur la page de l’extension, explique comment renseigner ce fichier. Nous serons particulièrement vigilants quant à la gestion des secrets (tokens, mots de passe, etc.). Une astuce pourra être d’utiliser des variables d’environnement dans ce fichier, elles-mêmes sécurisées par Azure DevOps. Une meilleure pratique consistera à utiliser un coffre-fort de secrets Azure Key Vault, lui-même déclaré comme un service lié.
EDIT : en cas d’utilisation d’un firewall sur la ressource Azure Key Vault, il sera nécessaire d’ajouter l’IP de l’agent DevOps à ce firewall. Or, cette adresse IP n’est pas fixe.
Nous pouvons maintenant lancer la release.
Nous vérifions enfin dans le Studio Data Factory que les éléments développés sont bien présents, en particulier les triggers. Ceux-ci sont alors dans l’état “démarré” ou “arrêté” de l’environnement de développement.
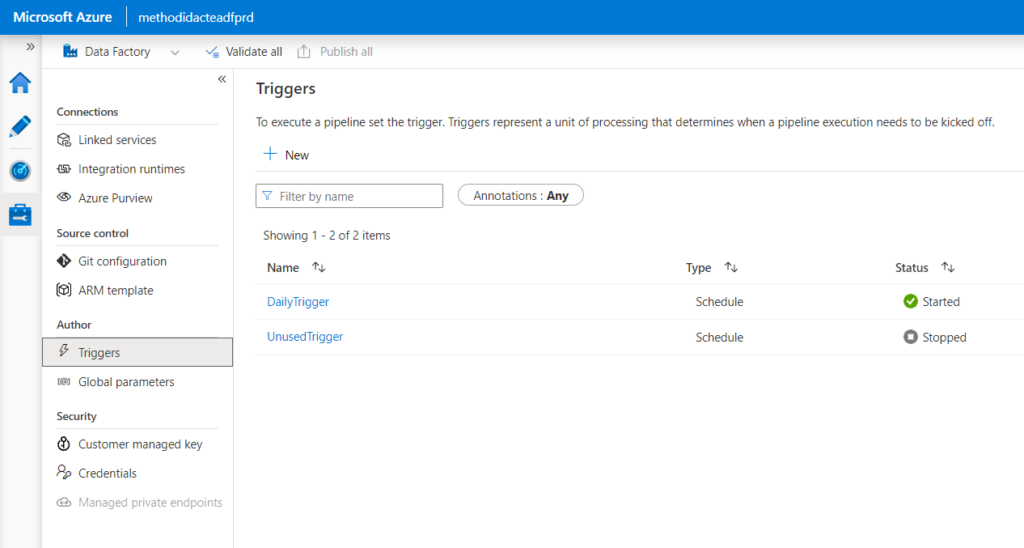
Cette approche pourrait être perturbante si tous les triggers de développement sont arrêtés (les faire tourner ne se justifie sans doute pas). Mais nous avons bénéficier d’une autre fonctionnalité pour améliorer notre déploiement.
Réaliser un déploiement sélectif
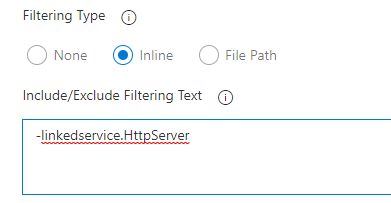
Une autre option de l’extension sera particulièrement intéressante : le déploiement sélectif. Une case de la boîte de dialogue permet de déclarer la liste des objets que l’on souhaite ou non déployer. La syntaxe est explicité sur la page GitHub de l’extension.
Par exemple, nous retirons le déploiement d’un autre service lié, qui ne sera pas utile en production.
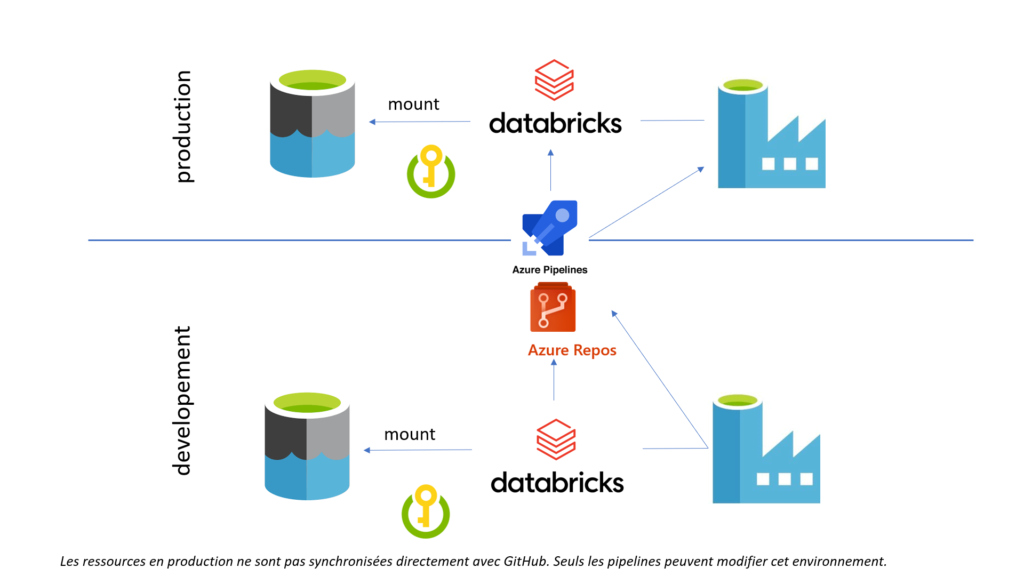
Dans une architecture plus complète, intégrant un Data Lake, nous pouvons obtenir le schéma suivant. Chaque cluster Databricks disposera d’un secret scope, lié à un coffre-fort Azure Key Vault. Celui-ci contiendra la définition d’un principal de service (client ID et client secret) permettant de définir un point de montage vers la ressource Azure Data Lake gen2 de l’environnement.
Pour remplacer certains paramètres avancés des services liés, cet article pourra servir de ressource.