
Le portail Azure Machine Learning propose une interface graphique (UI) pour réaliser de premières modèles d’apprentissage dans trois cas de figure :
- régression
- classification
- forecasting
Nous allons nous intéresser ici au forecasting, c’est-à-dire à la prévision sur des données issues d’une série temporelle (ou dite encore série chronologique).
Une série temporelle est un jeu de données composé tout simplement de deux colonnes : une mesure numérique et une variable de temps indiquant le moment de cette mesure. Il est indispensable que les intervalles de temps soient réguliers. Par exemple, nous pouvons disposer d’une mesure par jour, par semaine ou bien par mois, ou encore à des granularités plus fines comme l’heure, la minute, voire la seconde.
S’il existent des valeurs manquantes, il sera nécessaire de les “imputer” avant d’utiliser le jeu de données pour l’apprentissage automatisé.
Depuis le menu latéral, nous lançons une nouvelle exécution (“run“) d’automated ML.
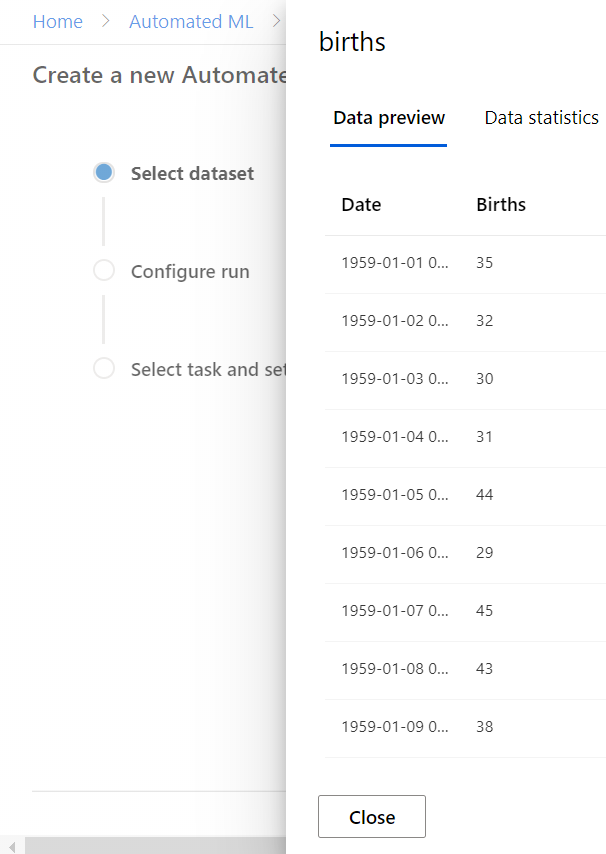
Nous sélectionnons ensuite le jeu de données (“dataset“) répondant à la définition donnée ci-dessous d’une série temporelle.
Pour un premier exemple d’utilisation, nous choisirons le jeu de données du nombre de filles nées par jour en Californie en 1959, disponible sur ce lien.
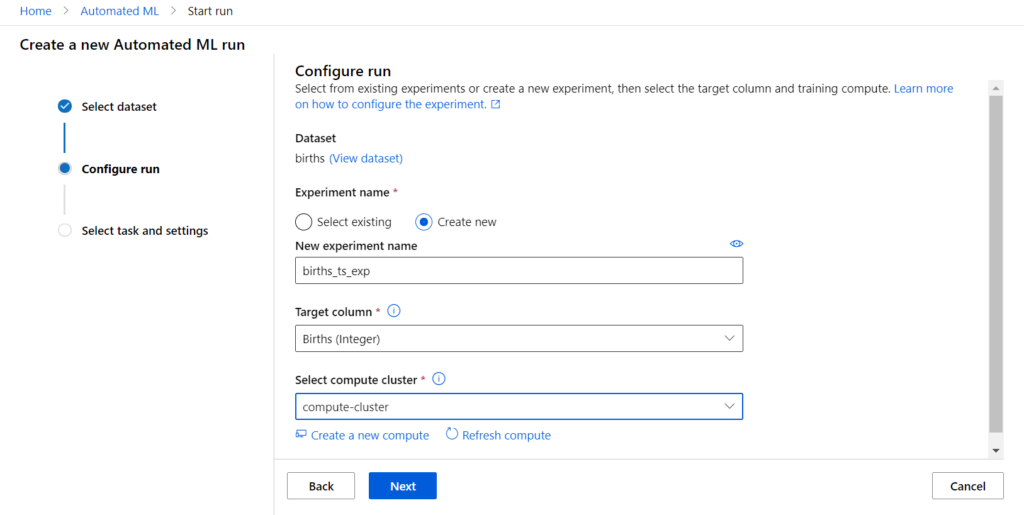
Il faut ensuite donner un nom pour l’expérience (la trace de l’exécution dans le portail) et choisir une ressource de calcul de type compute cluster.
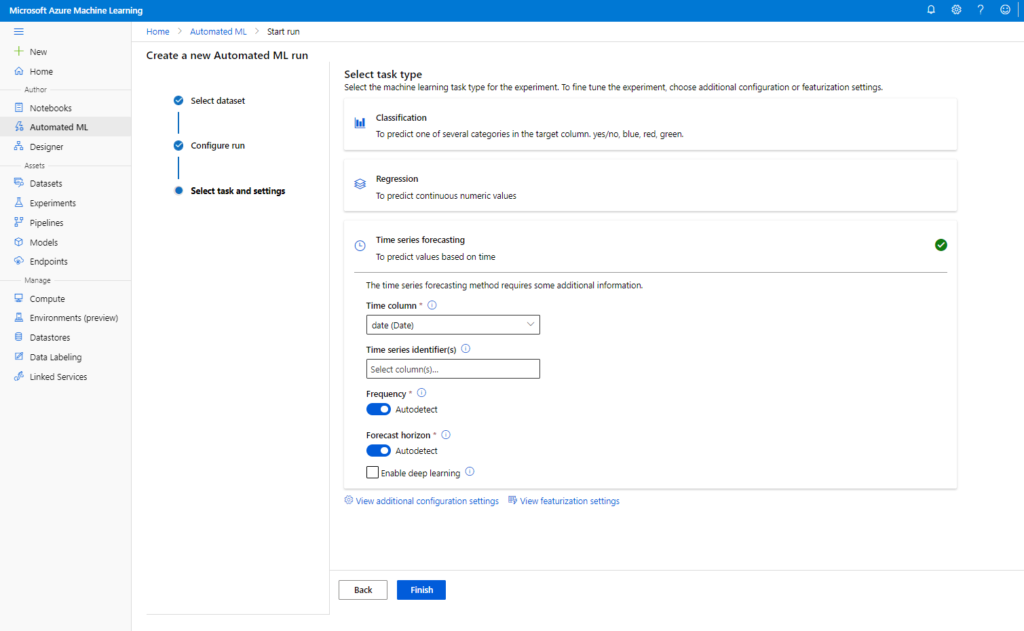
C’est à l’écran suivant que l’on choisira explicitement une tâche de type “time series forecasting“.
Avant de lancer l’exécution (bouton Finish), nous pouvons réaliser quelques paramétrages (attention, aucun retour arrière ne sera ensuite possible !).
Si les données ne sont pas agrégées pour ne disposer que d’une seule ligne par échelon de temps, il sera nécessaire de lister les “time series identifiers“, c’est-à-dire les colonnes qui permettraient de traiter plusieurs séries temporelles au travers de la même expérience. <Cela se traduira par la présence d’autres paramètres en entrée du service web prédictif.>
Deux options sont par défaut positionnées sur “autodetect” :
- Frequency : il s’agit de la granularité temporelle du jeu de données. Les valeurs possibles sont présentées ci-dessous. Utilisez explicitement ce paramètre si un doute est possible ou qu’une agrégation est nécessaire (sum, min, max, mean).
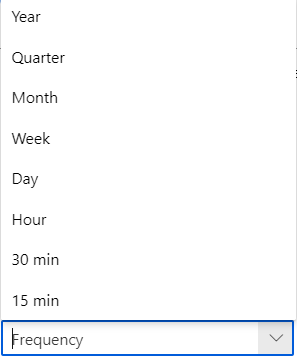
- Forecast horizon : il s’agit du nombre de périodes (dans l’unité du paramètre Frequency) qui seront prédites. La documentation officielle ne mentionne pas la règle appliquée dans le cas de l’auto-détection. Je vous recommande de le spécifier explicitement, en étant “raisonnable”, c’est-à-dire en ne dépassant pas le tiers de votre historique (ex.: pour 3 années d’entrainement, se limiter à une année de prévision).
Nous pouvons enfin définir des éléments de configuration additionnelle (cliquer sur “View additional configuration settings”).
Pour bloquer des algorithmes, il suffit de cliquer dans la liste déroulante.
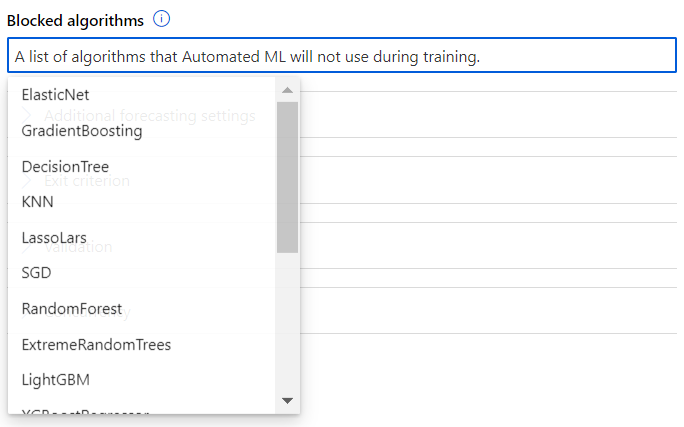
Je vous conseille de conserver les méthodes dites “naïves” qui donneront un premier seuil pour les métriques d’évaluation. Vous pouvez également choisir de ne pas utiliser les méthodes non linéaires comme les RandomForest ou KNN. Les méthodes traditionnelles du domaine des séries temporelles sont présentes (autoARIMA, exponential smoothing) ainsi que la librairie issue de Facebook : Prophet.
Les méthodes d’apprentissage profond seront également évaluées en cochant la case “enable Deep Learning”. Ces méthodes ont montré leur efficacité mais rappelons qu’elles sont coûteuses en temps d’entrainement puis d’inférence et sur des problématiques relativement simples, elles ne donneront sans doute pas un gain significatif de performance.
Les trois métriques de comparaison des modèles sont :
- normalized RMSE
- R2
- normalized MAE
Nous retrouverons cette métrique comme critère d’arrêt de l’expérience. Il faut alors renseigner un seuil entre 0 et 1 (les métriques sont normalisées et le R2 est par définition compris entre 0 et 1).

Il est important de ne pas se limiter à un seul indicateur d’évaluation, tous seront accessibles quand les différents modèles seront entrainés.
Je vous recommande aussi de borner le temps d’entrainement, afin de limiter les coûts mais également parce que vous obtiendrez sans doute assez rapidement une idée des modèles adaptés à vos données. Il sera ensuite plus efficace de bloquer les algorithmes les moins efficaces.
Si les deux critères sont utilisés, c’est le premier atteint qui arrêtera l’expérience.
Trois paramètres additionnels de configuration sont ensuite disponibles.
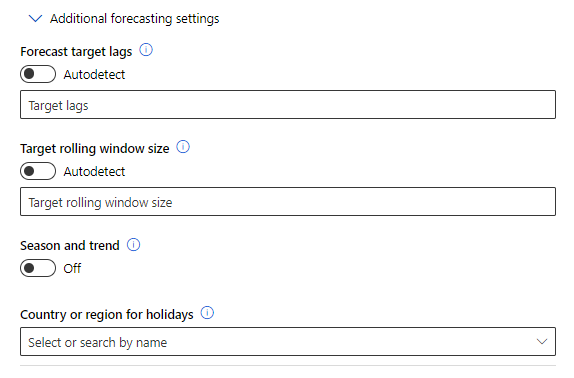
Ils correspondent respectivement à :
- target lags : il s’agit ici d’exploiter des valeurs précédentes pour prédire les nouvelles valeurs. Par exemple, un lag de 1 permettra d’utiliser la valeur à t pour prédire t+1. Je vous recommande cet article pour approfondir ce sujet.
- rolling window size : permet de ne tenir compte que d’une partie des données d’apprentissage. Par défaut, l’intégralité du jeu de données est considéré. Plus de détails sur cette méthode ici.
- season and trend : active la méthode de décomposition STL (“Seasonal and Trend decomposition using Loess”), permettant d’isoler saisonnalité, tendance et bruit.
Une dernière case permet de sélectionner un (et un seul) pays pour tenir compte des vacances dans les calculs de saisonnalité, ce que fait par exemple le modèle Prophet.
La seule méthode de validation du modèle est la méthode ce validation croisée “k-fold”, avec k = 5 par défaut.
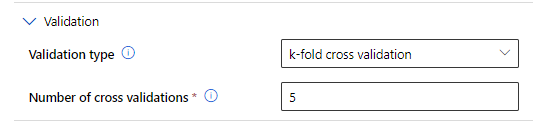
Enfin, les algorithmes se paralléliseront en fonction du nombre de nœuds du compute cluster défini préalablement.

Nous pouvons maintenant analyser les sorties produites par l’expérience d’automated ML.
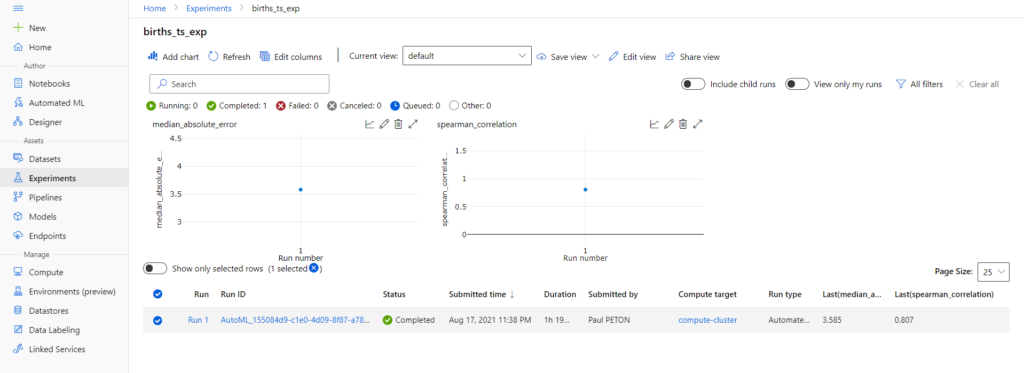
Le run principal est constitué de children runs, correspondant chacun à un algorithme, précédé éventuellement d’une préparation de données (PCA, MinMaxScaler, etc.) , et avec un choix d’ hyperparamètres. L’onglet Models présente ces différentes exécutions, triées selon la valeur décroissante de la métrique principale.
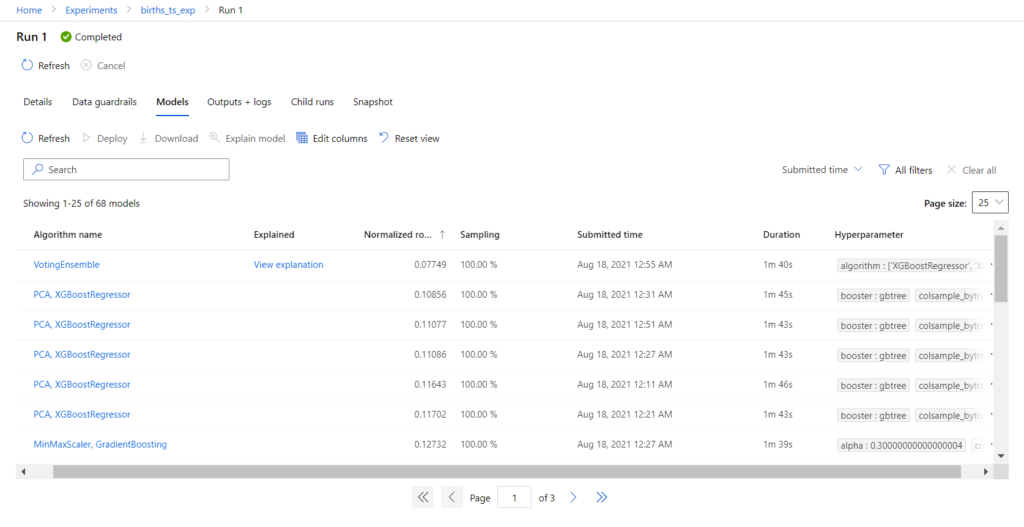
Notons également l’onglet Data guardails (garde-fous) qui nous avertit sur d’éventuels problèmes de constitution de notre jeu de données initial (historique trop court, valeurs manquantes, etc.).
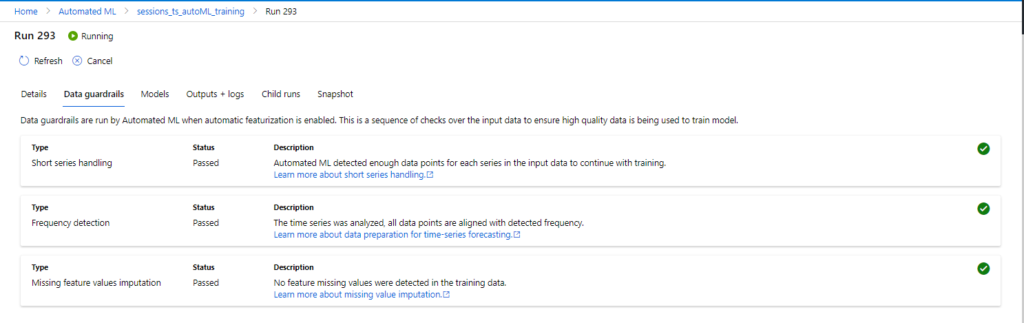
Il est très vraisemblable que le modèle “VotingEnsemble” soit le meilleur. C’est en effet un “méta-modèle” qui utilise plusieurs modèles simples et les fait voter pour obtenir les meilleures prévisions. C’est également un modèle plus lourd à exposer.
Il est tout à fait possible de choisir un autre modèle pour l’exposer.
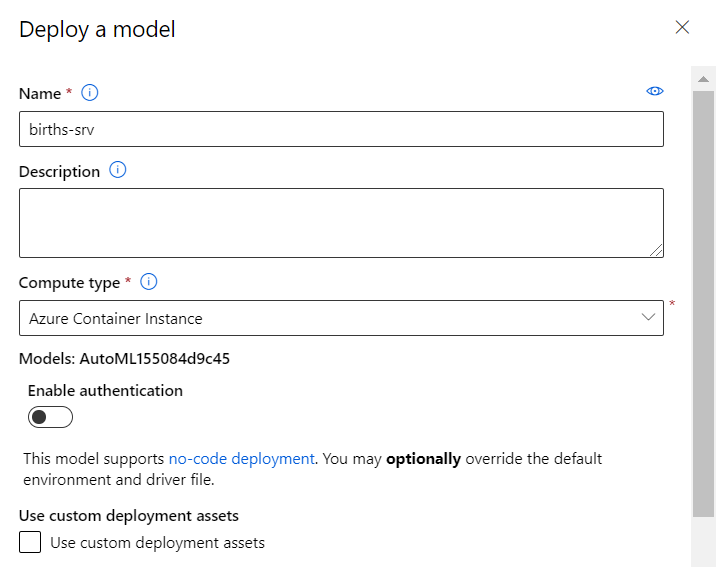
Pour un test simple, nous choisissons une ressource de type Azure Container Instance (ACI) et n’enclenchons pas l’authentification (un jeton serait alors demandé lors de l’appel au service web).
Dans les paramètres avancés, nous pouvons réduire le CPU et la RAM utilisés (et donc la facture associée… mais aussi les performances !).
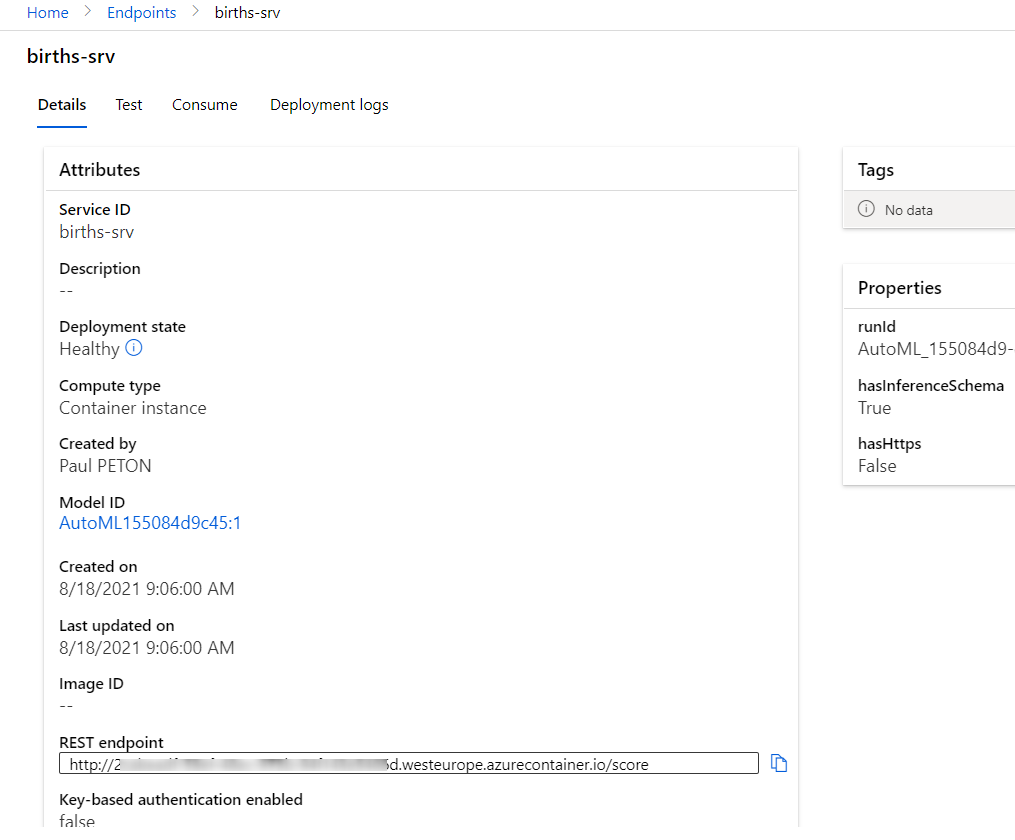
Un clic sur “Deploy” lance le déploiement et nous pouvons basculer sur la page dédiée aux endpoints.
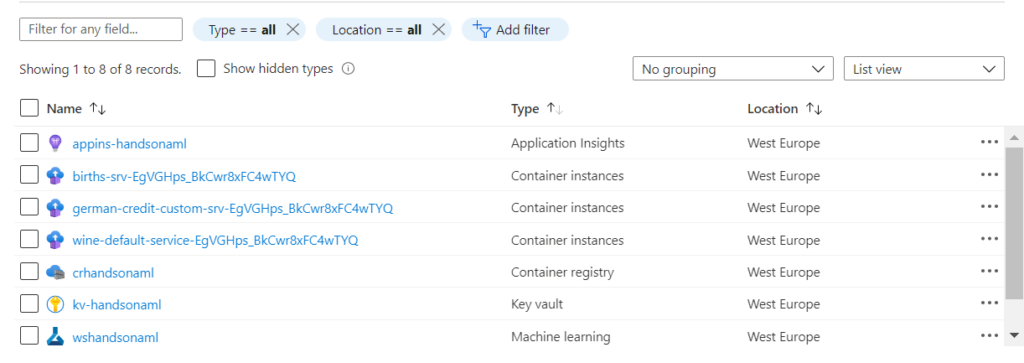
La ressource ACI se retrouvera également dans le portail Azure, dans le même groupe de ressources que le service Azure Machine Learning.
Pour consommer le modèle à partir du service web, nous devons utiliser des dates postérieures à la dernière date ayant servi à l’entrainement. Ceci peut se faire au travers de l’interface de test ou à l’aide des exemples de code donnés dans les langages C#, Python et R.
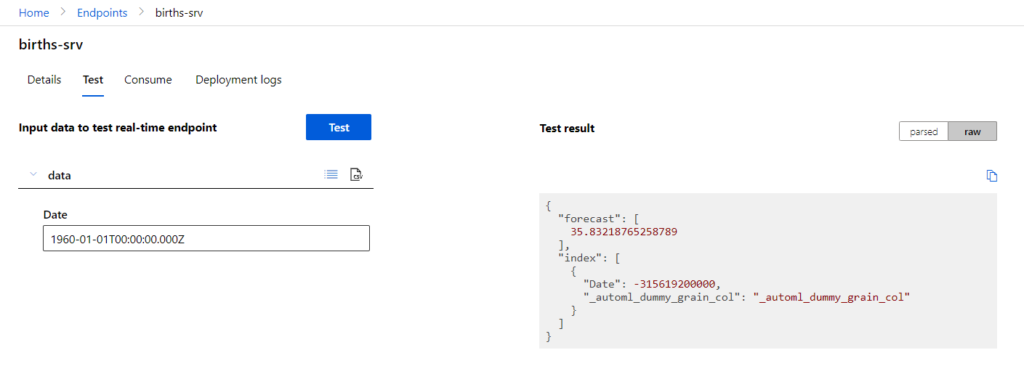
En conclusion, nous avons ici un outil dédié aux “citizen data scientists” puisqu’il n’est jamais nécessaire d’écrire de code mais une (très) bonne connaissance de la théorie des différentes méthodes algorithmes et de l’interprétation des métriques d’évaluation sera indispensable. Nous obtenons très rapidement un service web prédictif efficient qui pourra être exploité par d’autres applications. N’oublions pas enfin que pour “vivre en production”, une telle approche ne sera pas suffisante. Nous ne maîtrisons pas ici en particulier le réentrainement du modèle ni l’archivage de ces versions. Une approche par le code, exploitant les librairies du SDK azureml, sera alors une démarche plus pérenne et respectant les bonnes pratiques du MLOps. Prochain article à venir !