
Outil décisionnel self-service, de dataviz ou d’analytics, le débat autour de Power BI n’est toujours pas tranché. Les fonctionnalités étiquetées “IA” sont de plus en plus nombreuses mais souvent frustrantes car limitées dans leur paramétrage, comparée à une approche basée sur le code, en langage R ou Python par exemple.
Il serait bien sûr possible de tout réaliser dans ces langages (préparation de données, visualisation, voire partage) mais dans la pratique, nous naviguons souvent entre plusieurs outils. Et si votre seul outil est un marteau…
Depuis le menu External Tools, lancer l’outil DAX Studio. Dans le menu Advanced, cliquer sur « Export Data ».
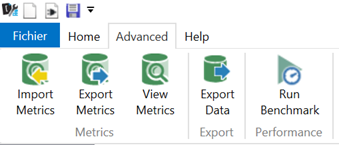
Choisir ensuite un export en fichier CSV et spécifier le séparateur attendu. Nous choisirons le séparateur virgule (comma) pour respecter la valeur par défaut de la méthode read_csv() de la librairie pandas.
Depuis un notebook, par exemple à partir de Jupyter Lab, nous exécutons le code détaillé ci-dessous. La première étape consiste à lister le contenu du répertoire où ont été exportées les différentes tables.
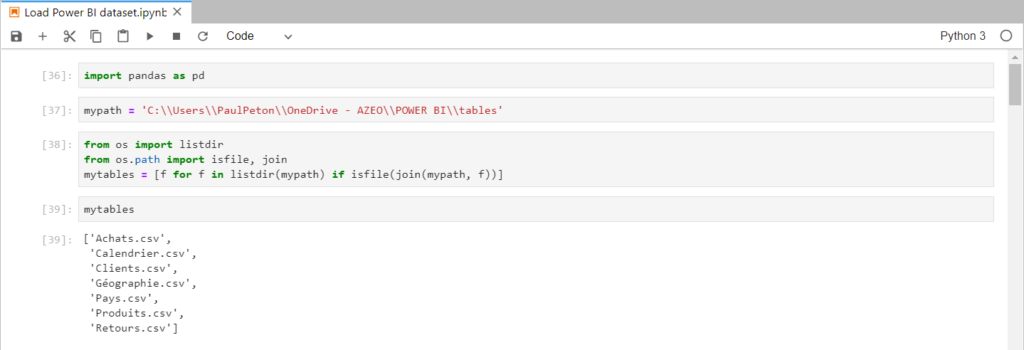
La création d’un pandas dataframe par fichier se fait ensuite de manière itérative. Le nom du fichier est utilisé pour nommer l’objet en mémoire. La fonction globals() permet de vérifier la liste des variables globales définies dans la session.
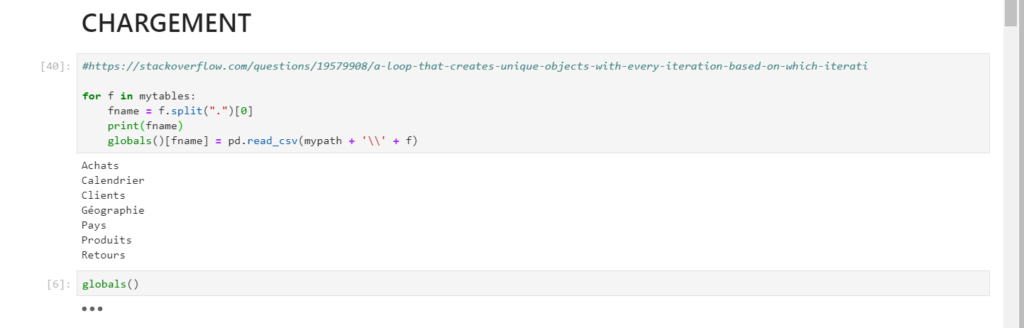
Nous retrouvons alors le “modèle sémantique” à l’identique : noms de tables, de colonnes, à l’exception d’éventuelles mesures. Les colonnes calculées apparaissent quant à elles, comme une “copie en valeur”.
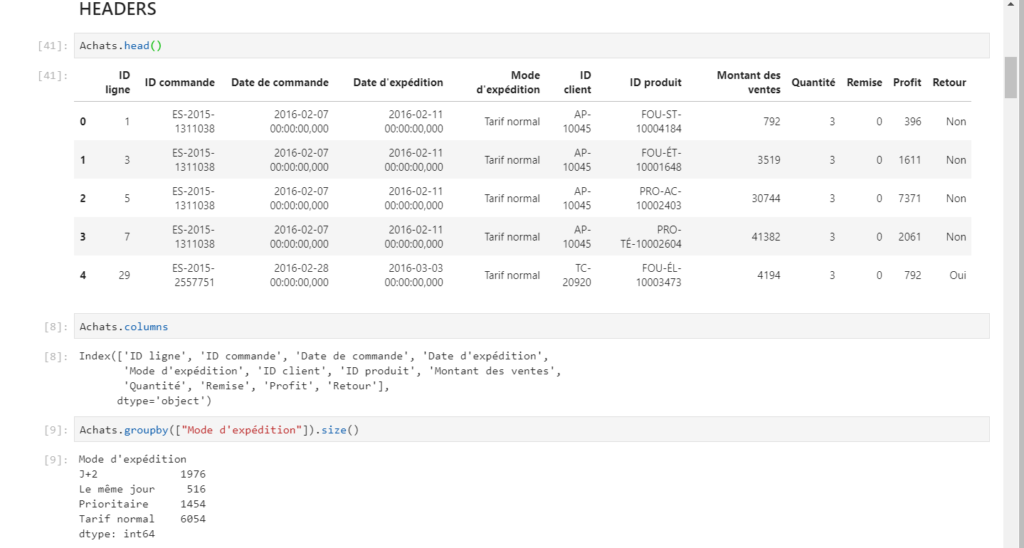
Les relations entre tables pourront être remplacées par des jointures entre dataframes à l’aide de la fonction merge().
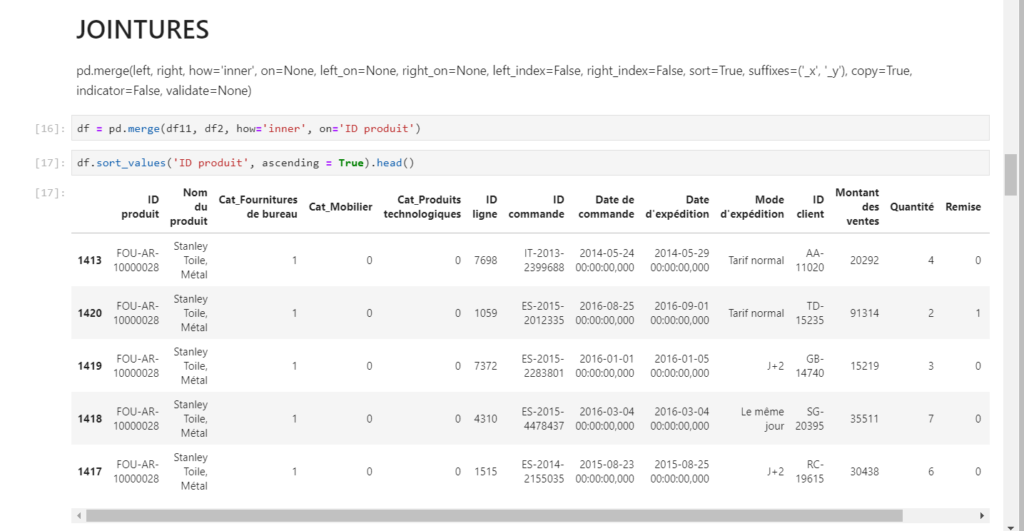
La fonction describe() donne un résumé statistique de toutes les variables numériques.
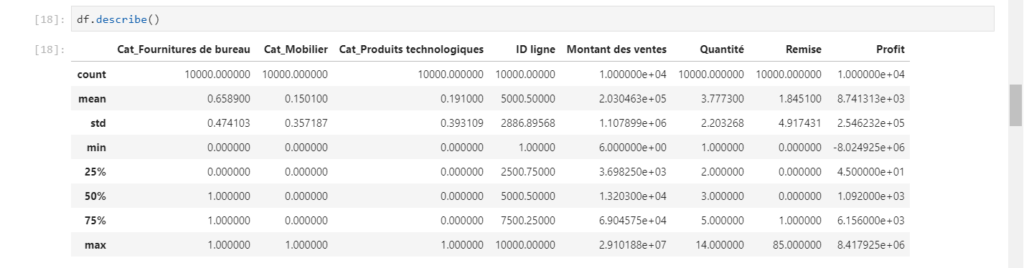
Il est ensuite possible de pousser des analyses exploratoires multidimensionnelles comme un modèle de Machine Learning non supervisé de type KMeans.
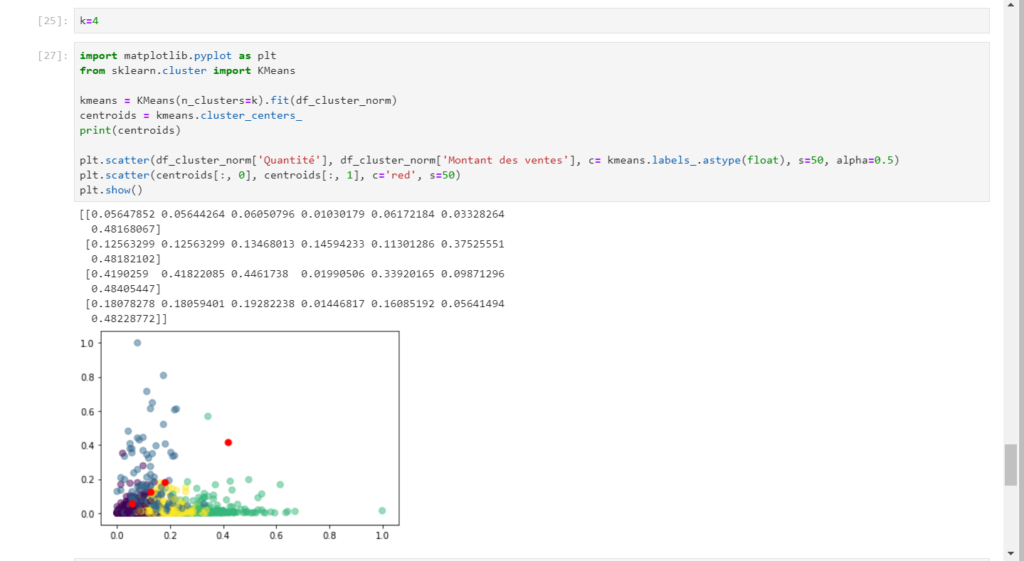
Le code complet vous est proposé dans ce notebook.